 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXianda Guo
GenAD: Generative End-to-End Autonomous Driving
Feb 20, 2024
Directly producing planning results from raw sensors has been a long-desired solution for autonomous driving and has attracted increasing attention recently. Most existing end-to-end autonomous driving methods factorize this problem into perception, motion prediction, and planning. However, we argue that the conventional progressive pipeline still cannot comprehensively model the entire traffic evolution process, e.g., the future interaction between the ego car and other traffic participants and the structural trajectory prior. In this paper, we explore a new paradigm for end-to-end autonomous driving, where the key is to predict how the ego car and the surroundings evolve given past scenes. We propose GenAD, a generative framework that casts autonomous driving into a generative modeling problem. We propose an instance-centric scene tokenizer that first transforms the surrounding scenes into map-aware instance tokens. We then employ a variational autoencoder to learn the future trajectory distribution in a structural latent space for trajectory prior modeling. We further adopt a temporal model to capture the agent and ego movements in the latent space to generate more effective future trajectories. GenAD finally simultaneously performs motion prediction and planning by sampling distributions in the learned structural latent space conditioned on the instance tokens and using the learned temporal model to generate futures. Extensive experiments on the widely used nuScenes benchmark show that the proposed GenAD achieves state-of-the-art performance on vision-centric end-to-end autonomous driving with high efficiency. Code: https://github.com/wzzheng/GenAD.
OpenStereo: A Comprehensive Benchmark for Stereo Matching and Strong Baseline
Dec 01, 2023Stereo matching, a pivotal technique in computer vision, plays a crucial role in robotics, autonomous navigation, and augmented reality. Despite the development of numerous impressive methods in recent years, replicating their results and determining the most suitable architecture for practical application remains challenging. Addressing this gap, our paper introduces a comprehensive benchmark focusing on practical applicability rather than solely on performance enhancement. Specifically, we develop a flexible and efficient stereo matching codebase, called OpenStereo. OpenStereo includes training and inference codes of more than 12 network models, making it, to our knowledge, the most complete stereo matching toolbox available. Based on OpenStereo, we conducted experiments on the SceneFlow dataset and have achieved or surpassed the performance metrics reported in the original paper. Additionally, we conduct an in-depth revisitation of recent developments in stereo matching through ablative experiments. These investigations inspired the creation of StereoBase, a simple yet strong baseline model. Our extensive comparative analyses of StereoBase against numerous contemporary stereo matching methods on the SceneFlow dataset demonstrate its remarkably strong performance. The source code is available at https://github.com/XiandaGuo/OpenStereo.
Multi-Prompt with Depth Partitioned Cross-Modal Learning
May 25, 2023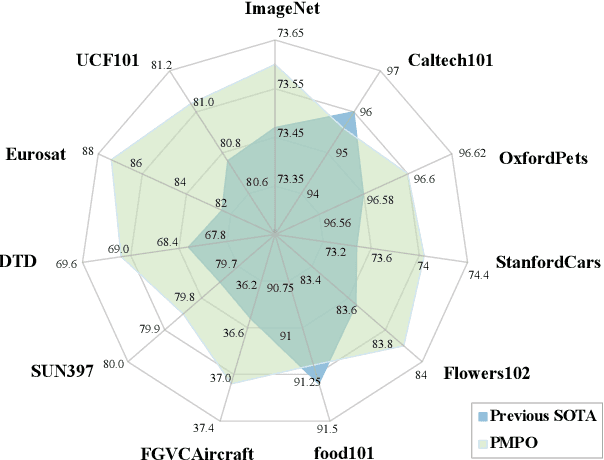
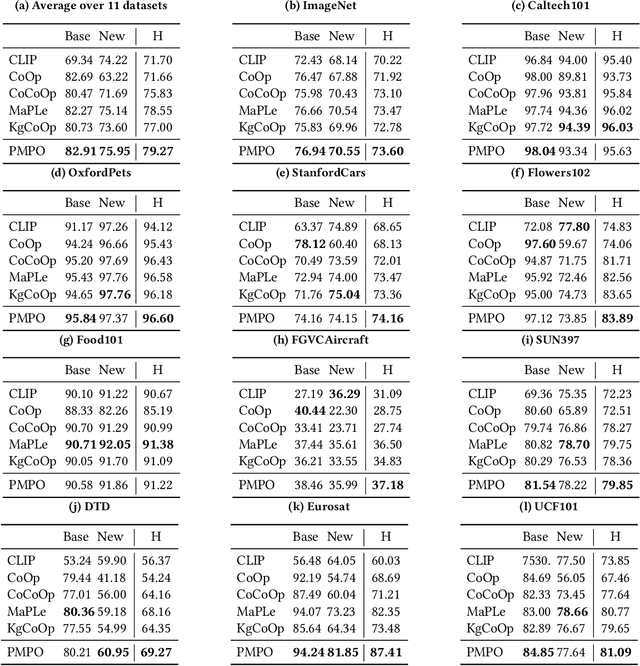

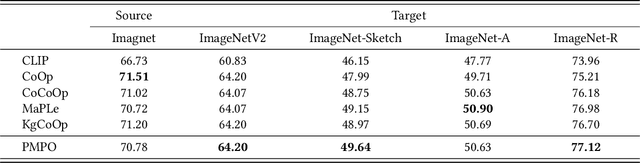
In recent years, soft prompt learning methods have been proposed to fine-tune large-scale vision-language pre-trained models for various downstream tasks. These methods typically combine learnable textual tokens with class tokens as input for models with frozen parameters. However, they often employ a single prompt to describe class contexts, failing to capture categories' diverse attributes adequately. This study introduces the Partitioned Multi-modal Prompt (PMPO), a multi-modal prompting technique that extends the soft prompt from a single learnable prompt to multiple prompts. Our method divides the visual encoder depths and connects learnable prompts to the separated visual depths, enabling different prompts to capture the hierarchical contextual depths of visual representations. Furthermore, to maximize the advantages of multi-prompt learning, we incorporate prior information from manually designed templates and learnable multi-prompts, thus improving the generalization capabilities of our approach. We evaluate the effectiveness of our approach on three challenging tasks: new class generalization, cross-dataset evaluation, and domain generalization. For instance, our method achieves a $79.28$ harmonic mean, averaged over 11 diverse image recognition datasets ($+7.62$ compared to CoOp), demonstrating significant competitiveness compared to state-of-the-art prompting methods.
DyGait: Exploiting Dynamic Representations for High-performance Gait Recognition
Mar 27, 2023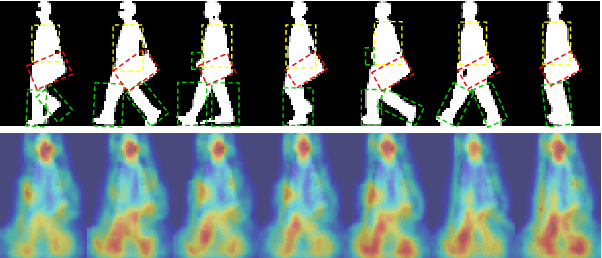

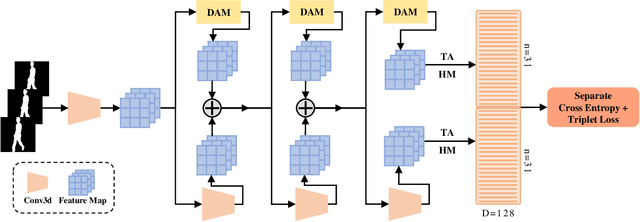

Gait recognition is a biometric technology that recognizes the identity of humans through their walking patterns. Compared with other biometric technologies, gait recognition is more difficult to disguise and can be applied to the condition of long-distance without the cooperation of subjects. Thus, it has unique potential and wide application for crime prevention and social security. At present, most gait recognition methods directly extract features from the video frames to establish representations. However, these architectures learn representations from different features equally but do not pay enough attention to dynamic features, which refers to a representation of dynamic parts of silhouettes over time (e.g. legs). Since dynamic parts of the human body are more informative than other parts (e.g. bags) during walking, in this paper, we propose a novel and high-performance framework named DyGait. This is the first framework on gait recognition that is designed to focus on the extraction of dynamic features. Specifically, to take full advantage of the dynamic information, we propose a Dynamic Augmentation Module (DAM), which can automatically establish spatial-temporal feature representations of the dynamic parts of the human body. The experimental results show that our DyGait network outperforms other state-of-the-art gait recognition methods. It achieves an average Rank-1 accuracy of 71.4% on the GREW dataset, 66.3% on the Gait3D dataset, 98.4% on the CASIA-B dataset and 98.3% on the OU-MVLP dataset.
A Simple Baseline for Supervised Surround-view Depth Estimation
Mar 14, 2023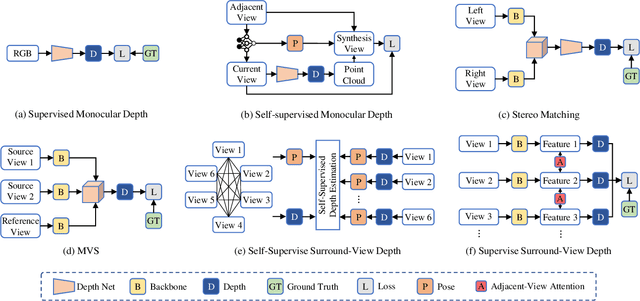
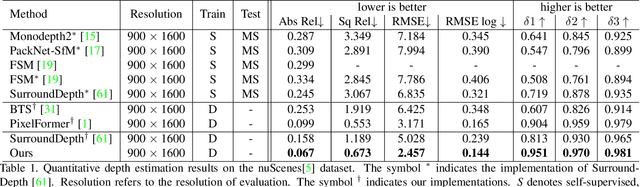
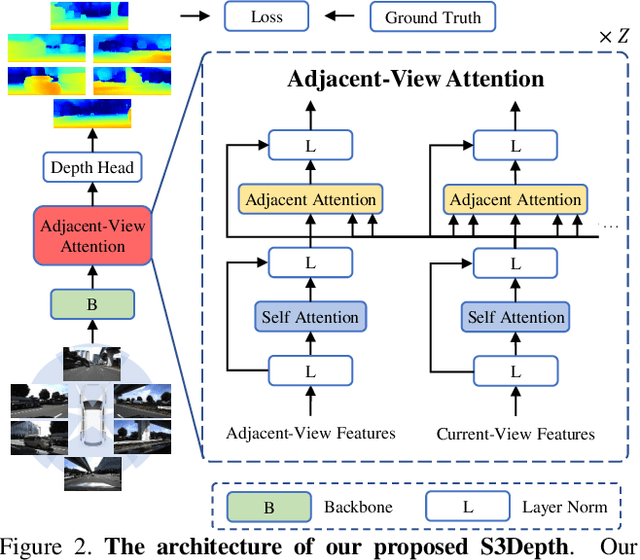
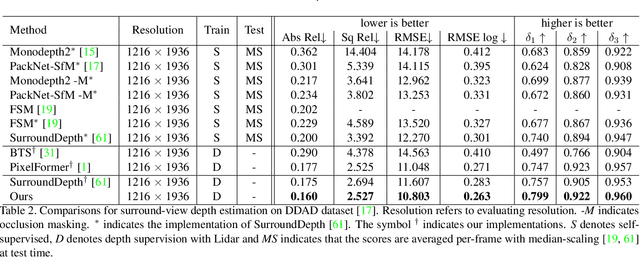
Depth estimation has been widely studied and serves as the fundamental step of 3D perception for autonomous driving. Though significant progress has been made for monocular depth estimation in the past decades, these attempts are mainly conducted on the KITTI benchmark with only front-view cameras, which ignores the correlations across surround-view cameras. In this paper, we propose S3Depth, a Simple Baseline for Supervised Surround-view Depth Estimation, to jointly predict the depth maps across multiple surrounding cameras. Specifically, we employ a global-to-local feature extraction module which combines CNN with transformer layers for enriched representations. Further, the Adjacent-view Attention mechanism is proposed to enable the intra-view and inter-view feature propagation. The former is achieved by the self-attention module within each view, while the latter is realized by the adjacent attention module, which computes the attention across multi-cameras to exchange the multi-scale representations across surround-view feature maps. Extensive experiments show that our method achieves superior performance over existing state-of-the-art methods on both DDAD and nuScenes datasets.
DiffusionDepth: Diffusion Denoising Approach for Monocular Depth Estimation
Mar 13, 2023



Monocular depth estimation is a challenging task that predicts the pixel-wise depth from a single 2D image. Current methods typically model this problem as a regression or classification task. We propose DiffusionDepth, a new approach that reformulates monocular depth estimation as a denoising diffusion process. It learns an iterative denoising process to `denoise' random depth distribution into a depth map with the guidance of monocular visual conditions. The process is performed in the latent space encoded by a dedicated depth encoder and decoder. Instead of diffusing ground truth (GT) depth, the model learns to reverse the process of diffusing the refined depth of itself into random depth distribution. This self-diffusion formulation overcomes the difficulty of applying generative models to sparse GT depth scenarios. The proposed approach benefits this task by refining depth estimation step by step, which is superior for generating accurate and highly detailed depth maps. Experimental results on KITTI and NYU-Depth-V2 datasets suggest that a simple yet efficient diffusion approach could reach state-of-the-art performance in both indoor and outdoor scenarios with acceptable inference time.
MonoViT: Self-Supervised Monocular Depth Estimation with a Vision Transformer
Aug 06, 2022



Self-supervised monocular depth estimation is an attractive solution that does not require hard-to-source depth labels for training. Convolutional neural networks (CNNs) have recently achieved great success in this task. However, their limited receptive field constrains existing network architectures to reason only locally, dampening the effectiveness of the self-supervised paradigm. In the light of the recent successes achieved by Vision Transformers (ViTs), we propose MonoViT, a brand-new framework combining the global reasoning enabled by ViT models with the flexibility of self-supervised monocular depth estimation. By combining plain convolutions with Transformer blocks, our model can reason locally and globally, yielding depth prediction at a higher level of detail and accuracy, allowing MonoViT to achieve state-of-the-art performance on the established KITTI dataset. Moreover, MonoViT proves its superior generalization capacities on other datasets such as Make3D and DrivingStereo.
Gait Recognition in the Wild: A Benchmark
May 05, 2022
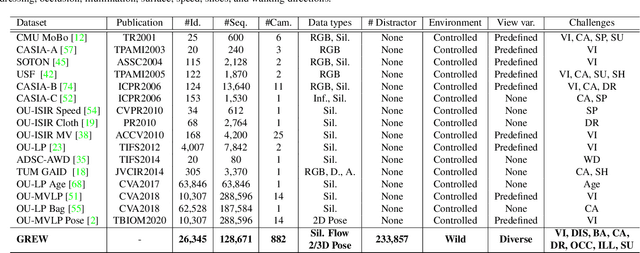

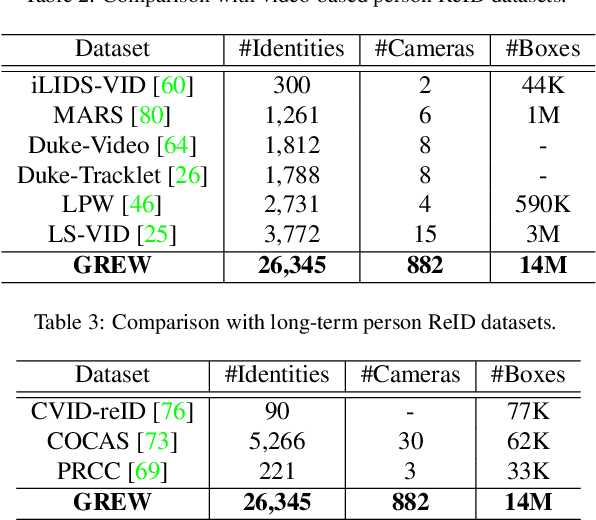
Gait benchmarks empower the research community to train and evaluate high-performance gait recognition systems. Even though growing efforts have been devoted to cross-view recognition, academia is restricted by current existing databases captured in the controlled environment. In this paper, we contribute a new benchmark for Gait REcognition in the Wild (GREW). The GREW dataset is constructed from natural videos, which contains hundreds of cameras and thousands of hours streams in open systems. With tremendous manual annotations, the GREW consists of 26K identities and 128K sequences with rich attributes for unconstrained gait recognition. Moreover, we add a distractor set of over 233K sequences, making it more suitable for real-world applications. Compared with prevailing predefined cross-view datasets, the GREW has diverse and practical view variations, as well as more natural challenging factors. To the best of our knowledge, this is the first large-scale dataset for gait recognition in the wild. Equipped with this benchmark, we dissect the unconstrained gait recognition problem. Representative appearance-based and model-based methods are explored, and comprehensive baselines are established. Experimental results show (1) The proposed GREW benchmark is necessary for training and evaluating gait recognizer in the wild. (2) For state-of-the-art gait recognition approaches, there is a lot of room for improvement. (3) The GREW benchmark can be used as effective pre-training for controlled gait recognition. Benchmark website is https://www.grew-benchmark.org/.
GaitStrip: Gait Recognition via Effective Strip-based Feature Representations and Multi-Level Framework
Mar 08, 2022



Many gait recognition methods first partition the human gait into N-parts and then combine them to establish part-based feature representations. Their gait recognition performance is often affected by partitioning strategies, which are empirically chosen in different datasets. However, we observe that strips as the basic component of parts are agnostic against different partitioning strategies. Motivated by this observation, we present a strip-based multi-level gait recognition network, named GaitStrip, to extract comprehensive gait information at different levels. To be specific, our high-level branch explores the context of gait sequences and our low-level one focuses on detailed posture changes. We introduce a novel StriP-Based feature extractor (SPB) to learn the strip-based feature representations by directly taking each strip of the human body as the basic unit. Moreover, we propose a novel multi-branch structure, called Enhanced Convolution Module (ECM), to extract different representations of gaits. ECM consists of the Spatial-Temporal feature extractor (ST), the Frame-Level feature extractor (FL) and SPB, and has two obvious advantages: First, each branch focuses on a specific representation, which can be used to improve the robustness of the network. Specifically, ST aims to extract spatial-temporal features of gait sequences, while FL is used to generate the feature representation of each frame. Second, the parameters of the ECM can be reduced in test by introducing a structural re-parameterization technique. Extensive experimental results demonstrate that our GaitStrip achieves state-of-the-art performance in both normal walking and complex conditions.