 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChenming Zhang
OpenStereo: A Comprehensive Benchmark for Stereo Matching and Strong Baseline
Dec 01, 2023
Stereo matching, a pivotal technique in computer vision, plays a crucial role in robotics, autonomous navigation, and augmented reality. Despite the development of numerous impressive methods in recent years, replicating their results and determining the most suitable architecture for practical application remains challenging. Addressing this gap, our paper introduces a comprehensive benchmark focusing on practical applicability rather than solely on performance enhancement. Specifically, we develop a flexible and efficient stereo matching codebase, called OpenStereo. OpenStereo includes training and inference codes of more than 12 network models, making it, to our knowledge, the most complete stereo matching toolbox available. Based on OpenStereo, we conducted experiments on the SceneFlow dataset and have achieved or surpassed the performance metrics reported in the original paper. Additionally, we conduct an in-depth revisitation of recent developments in stereo matching through ablative experiments. These investigations inspired the creation of StereoBase, a simple yet strong baseline model. Our extensive comparative analyses of StereoBase against numerous contemporary stereo matching methods on the SceneFlow dataset demonstrate its remarkably strong performance. The source code is available at https://github.com/XiandaGuo/OpenStereo.
Grid-SD2E: A General Grid-Feedback in a System for Cognitive Learning
Apr 04, 2023



Comprehending how the brain interacts with the external world through generated neural signals is crucial for determining its working mechanism, treating brain diseases, and understanding intelligence. Although many theoretical models have been proposed, they have thus far been difficult to integrate and develop. In this study, we were inspired in part by grid cells in creating a more general and robust grid module and constructing an interactive and self-reinforcing cognitive system together with Bayesian reasoning, an approach called space-division and exploration-exploitation with grid-feedback (Grid-SD2E). Here, a grid module can be used as an interaction medium between the outside world and a system, as well as a self-reinforcement medium within the system. The space-division and exploration-exploitation (SD2E) receives the 0/1 signals of a grid through its space-division (SD) module. The system described in this paper is also a theoretical model derived from experiments conducted by other researchers and our experience on neural decoding. Herein, we analyse the rationality of the system based on the existing theories in both neuroscience and cognitive science, and attempt to propose special and general rules to explain the different interactions between people and between people and the external world. What's more, based on this model, the smallest computing unit is extracted, which is analogous to a single neuron in the brain.
A Simple Baseline for Supervised Surround-view Depth Estimation
Mar 14, 2023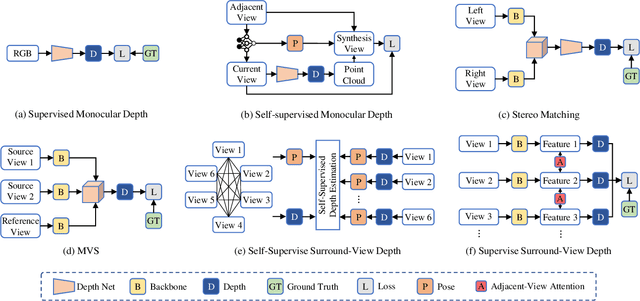
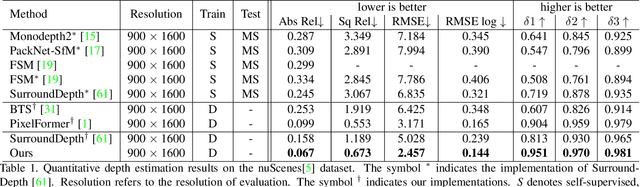
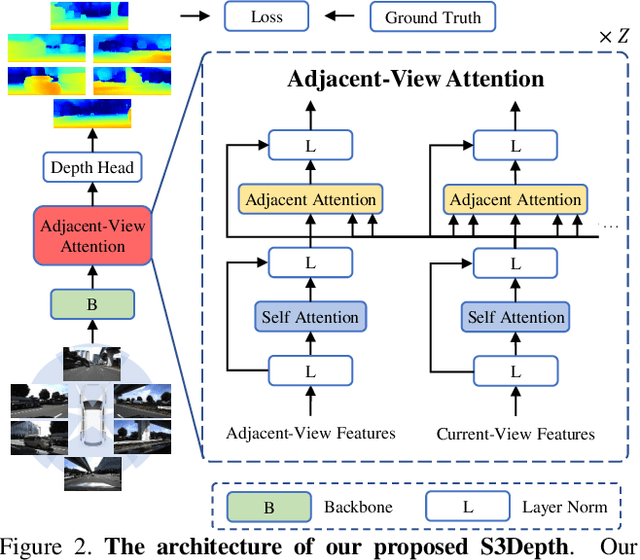
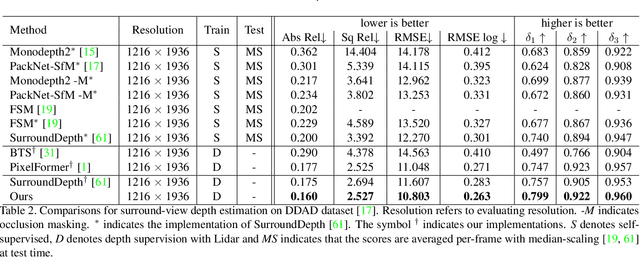
Depth estimation has been widely studied and serves as the fundamental step of 3D perception for autonomous driving. Though significant progress has been made for monocular depth estimation in the past decades, these attempts are mainly conducted on the KITTI benchmark with only front-view cameras, which ignores the correlations across surround-view cameras. In this paper, we propose S3Depth, a Simple Baseline for Supervised Surround-view Depth Estimation, to jointly predict the depth maps across multiple surrounding cameras. Specifically, we employ a global-to-local feature extraction module which combines CNN with transformer layers for enriched representations. Further, the Adjacent-view Attention mechanism is proposed to enable the intra-view and inter-view feature propagation. The former is achieved by the self-attention module within each view, while the latter is realized by the adjacent attention module, which computes the attention across multi-cameras to exchange the multi-scale representations across surround-view feature maps. Extensive experiments show that our method achieves superior performance over existing state-of-the-art methods on both DDAD and nuScenes datasets.