 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoyuan Wang
The Solution for the ICCV 2023 1st Scientific Figure Captioning Challenge
Mar 26, 2024

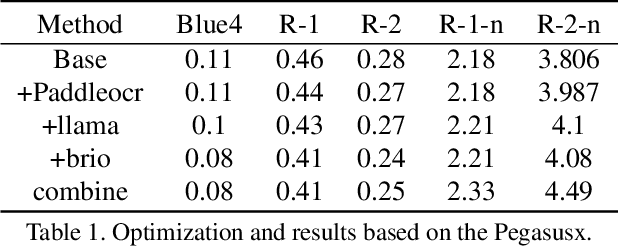
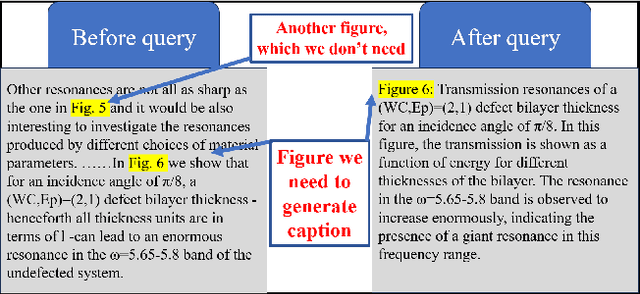
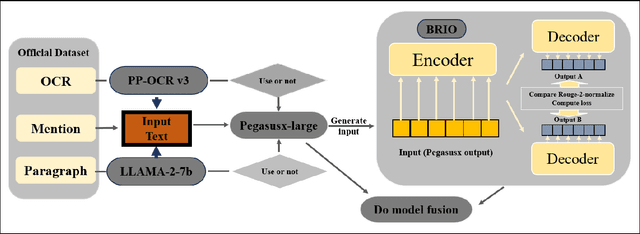
In this paper, we propose a solution for improving the quality of captions generated for figures in papers. We adopt the approach of summarizing the textual content in the paper to generate image captions. Throughout our study, we encounter discrepancies in the OCR information provided in the official dataset. To rectify this, we employ the PaddleOCR toolkit to extract OCR information from all images. Moreover, we observe that certain textual content in the official paper pertains to images that are not relevant for captioning, thereby introducing noise during caption generation. To mitigate this issue, we leverage LLaMA to extract image-specific information by querying the textual content based on image mentions, effectively filtering out extraneous information. Additionally, we recognize a discrepancy between the primary use of maximum likelihood estimation during text generation and the evaluation metrics such as ROUGE employed to assess the quality of generated captions. To bridge this gap, we integrate the BRIO model framework, enabling a more coherent alignment between the generation and evaluation processes. Our approach ranked first in the final test with a score of 4.49.
WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens
Jan 18, 2024World models play a crucial role in understanding and predicting the dynamics of the world, which is essential for video generation. However, existing world models are confined to specific scenarios such as gaming or driving, limiting their ability to capture the complexity of general world dynamic environments. Therefore, we introduce WorldDreamer, a pioneering world model to foster a comprehensive comprehension of general world physics and motions, which significantly enhances the capabilities of video generation. Drawing inspiration from the success of large language models, WorldDreamer frames world modeling as an unsupervised visual sequence modeling challenge. This is achieved by mapping visual inputs to discrete tokens and predicting the masked ones. During this process, we incorporate multi-modal prompts to facilitate interaction within the world model. Our experiments show that WorldDreamer excels in generating videos across different scenarios, including natural scenes and driving environments. WorldDreamer showcases versatility in executing tasks such as text-to-video conversion, image-tovideo synthesis, and video editing. These results underscore WorldDreamer's effectiveness in capturing dynamic elements within diverse general world environments.
Adaptive Residue-wise Profile Fusion for Low Homologous Protein SecondaryStructure Prediction Using External Knowledge
Aug 05, 2021



Protein secondary structure prediction (PSSP) is essential for protein function analysis. However, for low homologous proteins, the PSSP suffers from insufficient input features. In this paper, we explicitly import external self-supervised knowledge for low homologous PSSP under the guidance of residue-wise profile fusion. In practice, we firstly demonstrate the superiority of profile over Position-Specific Scoring Matrix (PSSM) for low homologous PSSP. Based on this observation, we introduce the novel self-supervised BERT features as the pseudo profile, which implicitly involves the residue distribution in all native discovered sequences as the complementary features. Further-more, a novel residue-wise attention is specially designed to adaptively fuse different features (i.e.,original low-quality profile, BERT based pseudo profile), which not only takes full advantage of each feature but also avoids noise disturbance. Be-sides, the feature consistency loss is proposed to accelerate the model learning from multiple semantic levels. Extensive experiments confirm that our method outperforms state-of-the-arts (i.e.,4.7%forextremely low homologous cases on BC40 dataset).