 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMang Ye
Semi-supervised Text-based Person Search
Apr 28, 2024
Text-based person search (TBPS) aims to retrieve images of a specific person from a large image gallery based on a natural language description. Existing methods rely on massive annotated image-text data to achieve satisfactory performance in fully-supervised learning. It poses a significant challenge in practice, as acquiring person images from surveillance videos is relatively easy, while obtaining annotated texts is challenging. The paper undertakes a pioneering initiative to explore TBPS under the semi-supervised setting, where only a limited number of person images are annotated with textual descriptions while the majority of images lack annotations. We present a two-stage basic solution based on generation-then-retrieval for semi-supervised TBPS. The generation stage enriches annotated data by applying an image captioning model to generate pseudo-texts for unannotated images. Later, the retrieval stage performs fully-supervised retrieval learning using the augmented data. Significantly, considering the noise interference of the pseudo-texts on retrieval learning, we propose a noise-robust retrieval framework that enhances the ability of the retrieval model to handle noisy data. The framework integrates two key strategies: Hybrid Patch-Channel Masking (PC-Mask) to refine the model architecture, and Noise-Guided Progressive Training (NP-Train) to enhance the training process. PC-Mask performs masking on the input data at both the patch-level and the channel-level to prevent overfitting noisy supervision. NP-Train introduces a progressive training schedule based on the noise level of pseudo-texts to facilitate noise-robust learning. Extensive experiments on multiple TBPS benchmarks show that the proposed framework achieves promising performance under the semi-supervised setting.
Transformer for Object Re-Identification: A Survey
Jan 13, 2024Object Re-Identification (Re-ID) aims to identify and retrieve specific objects from varying viewpoints. For a prolonged period, this field has been predominantly driven by deep convolutional neural networks. In recent years, the Transformer has witnessed remarkable advancements in computer vision, prompting an increasing body of research to delve into the application of Transformer in Re-ID. This paper provides a comprehensive review and in-depth analysis of the Transformer-based Re-ID. In categorizing existing works into Image/Video-Based Re-ID, Re-ID with limited data/annotations, Cross-Modal Re-ID, and Special Re-ID Scenarios, we thoroughly elucidate the advantages demonstrated by the Transformer in addressing a multitude of challenges across these domains. Considering the trending unsupervised Re-ID, we propose a new Transformer baseline, UntransReID, achieving state-of-the-art performance on both single-/cross modal tasks. Besides, this survey also covers a wide range of Re-ID research objects, including progress in animal Re-ID. Given the diversity of species in animal Re-ID, we devise a standardized experimental benchmark and conduct extensive experiments to explore the applicability of Transformer for this task to facilitate future research. Finally, we discuss some important yet under-investigated open issues in the big foundation model era, we believe it will serve as a new handbook for researchers in this field.
Negative Pre-aware for Noisy Cross-modal Matching
Dec 15, 2023Cross-modal noise-robust learning is a challenging task since noisy correspondence is hard to recognize and rectify. Due to the cumulative and unavoidable negative impact of unresolved noise, existing methods cannot maintain a stable performance when the noise increases. In this paper, we present a novel Negative Pre-aware Cross-modal (NPC) matching solution for large visual-language model fine-tuning on noisy downstream tasks. It is featured in two aspects: (1) For noise recognition and resistance, previous methods usually directly filter out a noise subset, we propose to estimate the negative impact of each sample. It does not need additional correction mechanisms that may predict unreliable correction results, leading to self-reinforcing error. We assign a confidence weight to each sample according to its negative impact in the training process. This adaptively adjusts the contribution of each sample to avoid noisy accumulation. (2) For maintaining stable performance with increasing noise, we utilize the memorization effect of DNNs by maintaining a memory bank. Specifically, we apply GMM to select high-confident clean samples as the memory entry, where the memory entry is used to estimate the negative impact of each sample. Since clean samples are easier distinguished by GMM with increasing noise, the memory bank can still maintain high quality at a high noise ratio. Compared to the correction mechanism focusing on noise samples, memory bank-based estimation is more robust, which makes the model performance stable on noisy datasets. Extensive experiments demonstrate that our method significantly improves matching accuracy and performance stability at increasing noise ratio. Our approach also surpasses the state-of-the-art methods by a large margin. The code is available at: https://github.com/ZhangXu0963/NPC.
Federated Learning for Generalization, Robustness, Fairness: A Survey and Benchmark
Nov 12, 2023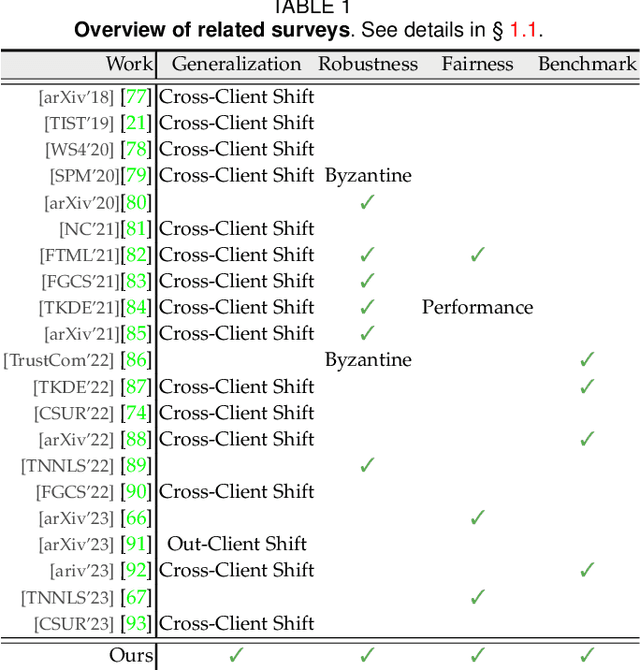
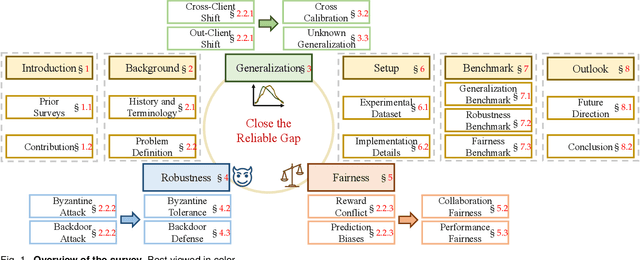

Federated learning has emerged as a promising paradigm for privacy-preserving collaboration among different parties. Recently, with the popularity of federated learning, an influx of approaches have delivered towards different realistic challenges. In this survey, we provide a systematic overview of the important and recent developments of research on federated learning. Firstly, we introduce the study history and terminology definition of this area. Then, we comprehensively review three basic lines of research: generalization, robustness, and fairness, by introducing their respective background concepts, task settings, and main challenges. We also offer a detailed overview of representative literature on both methods and datasets. We further benchmark the reviewed methods on several well-known datasets. Finally, we point out several open issues in this field and suggest opportunities for further research. We also provide a public website to continuously track developments in this fast advancing field: https://github.com/WenkeHuang/MarsFL.
Rotation Invariant Transformer for Recognizing Object in UAVs
Nov 05, 2023Recognizing a target of interest from the UAVs is much more challenging than the existing object re-identification tasks across multiple city cameras. The images taken by the UAVs usually suffer from significant size difference when generating the object bounding boxes and uncertain rotation variations. Existing methods are usually designed for city cameras, incapable of handing the rotation issue in UAV scenarios. A straightforward solution is to perform the image-level rotation augmentation, but it would cause loss of useful information when inputting the powerful vision transformer as patches. This motivates us to simulate the rotation operation at the patch feature level, proposing a novel rotation invariant vision transformer (RotTrans). This strategy builds on high-level features with the help of the specificity of the vision transformer structure, which enhances the robustness against large rotation differences. In addition, we design invariance constraint to establish the relationship between the original feature and the rotated features, achieving stronger rotation invariance. Our proposed transformer tested on the latest UAV datasets greatly outperforms the current state-of-the-arts, which is 5.9\% and 4.8\% higher than the highest mAP and Rank1. Notably, our model also performs competitively for the person re-identification task on traditional city cameras. In particular, our solution wins the first place in the UAV-based person re-recognition track in the Multi-Modal Video Reasoning and Analyzing Competition held in ICCV 2021. Code is available at https://github.com/whucsy/RotTrans.
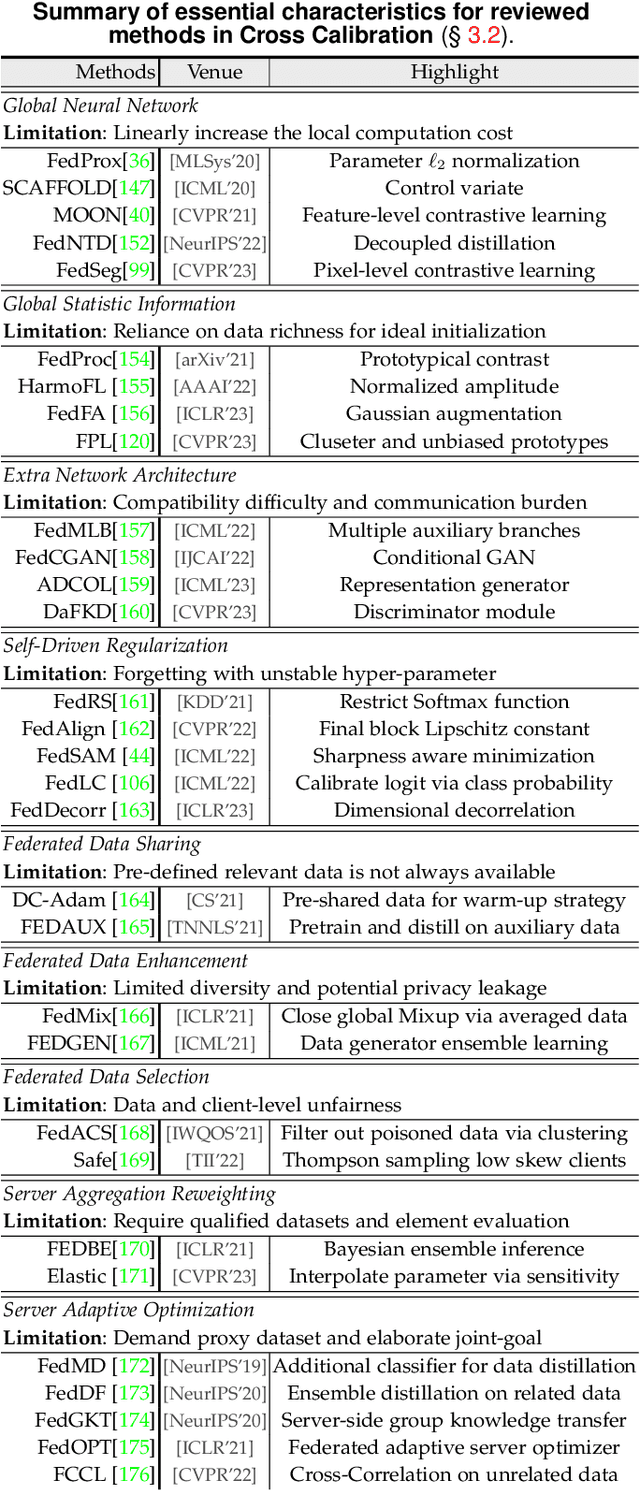
Generalizable Heterogeneous Federated Cross-Correlation and Instance Similarity Learning
Sep 28, 2023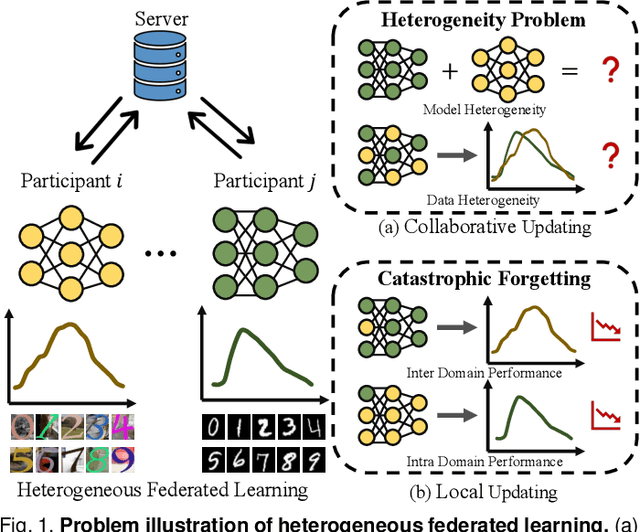
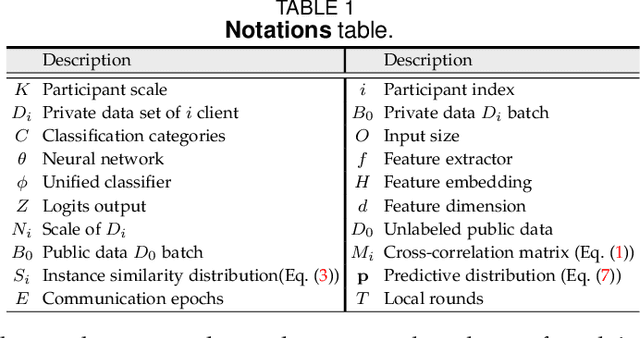
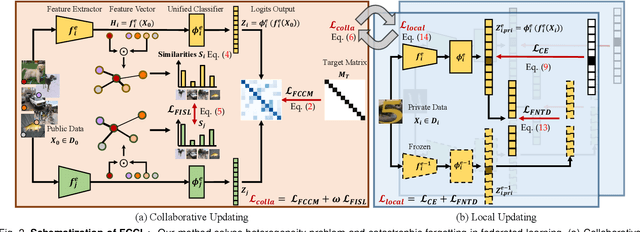
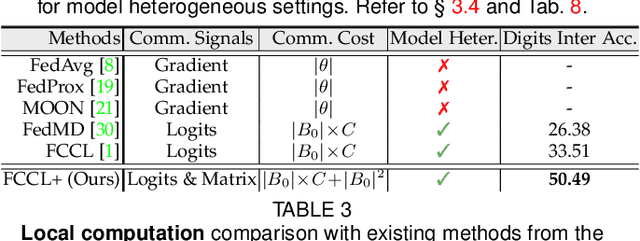
Federated learning is an important privacy-preserving multi-party learning paradigm, involving collaborative learning with others and local updating on private data. Model heterogeneity and catastrophic forgetting are two crucial challenges, which greatly limit the applicability and generalizability. This paper presents a novel FCCL+, federated correlation and similarity learning with non-target distillation, facilitating the both intra-domain discriminability and inter-domain generalization. For heterogeneity issue, we leverage irrelevant unlabeled public data for communication between the heterogeneous participants. We construct cross-correlation matrix and align instance similarity distribution on both logits and feature levels, which effectively overcomes the communication barrier and improves the generalizable ability. For catastrophic forgetting in local updating stage, FCCL+ introduces Federated Non Target Distillation, which retains inter-domain knowledge while avoiding the optimization conflict issue, fulling distilling privileged inter-domain information through depicting posterior classes relation. Considering that there is no standard benchmark for evaluating existing heterogeneous federated learning under the same setting, we present a comprehensive benchmark with extensive representative methods under four domain shift scenarios, supporting both heterogeneous and homogeneous federated settings. Empirical results demonstrate the superiority of our method and the efficiency of modules on various scenarios.
Rethinking Client Drift in Federated Learning: A Logit Perspective
Aug 20, 2023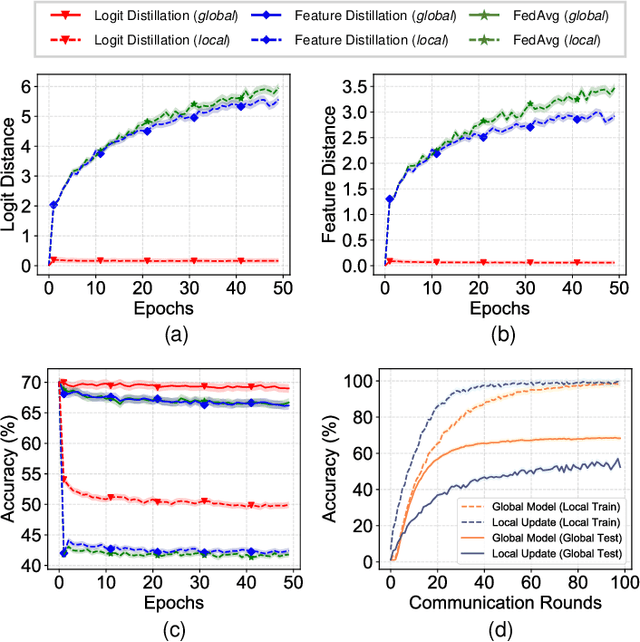
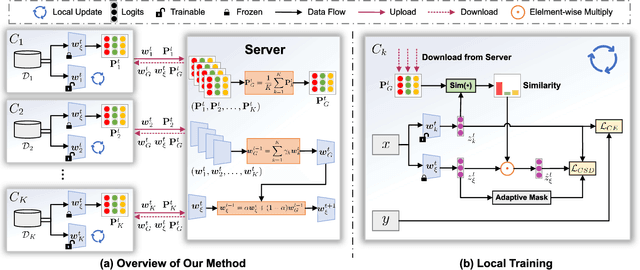
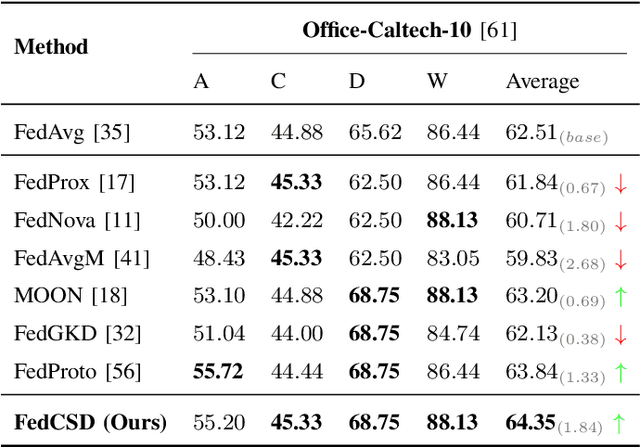
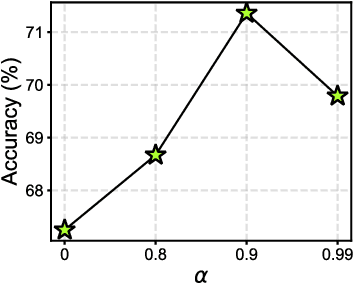
Federated Learning (FL) enables multiple clients to collaboratively learn in a distributed way, allowing for privacy protection. However, the real-world non-IID data will lead to client drift which degrades the performance of FL. Interestingly, we find that the difference in logits between the local and global models increases as the model is continuously updated, thus seriously deteriorating FL performance. This is mainly due to catastrophic forgetting caused by data heterogeneity between clients. To alleviate this problem, we propose a new algorithm, named FedCSD, a Class prototype Similarity Distillation in a federated framework to align the local and global models. FedCSD does not simply transfer global knowledge to local clients, as an undertrained global model cannot provide reliable knowledge, i.e., class similarity information, and its wrong soft labels will mislead the optimization of local models. Concretely, FedCSD introduces a class prototype similarity distillation to align the local logits with the refined global logits that are weighted by the similarity between local logits and the global prototype. To enhance the quality of global logits, FedCSD adopts an adaptive mask to filter out the terrible soft labels of the global models, thereby preventing them to mislead local optimization. Extensive experiments demonstrate the superiority of our method over the state-of-the-art federated learning approaches in various heterogeneous settings. The source code will be released.
An Empirical Study of CLIP for Text-based Person Search
Aug 19, 2023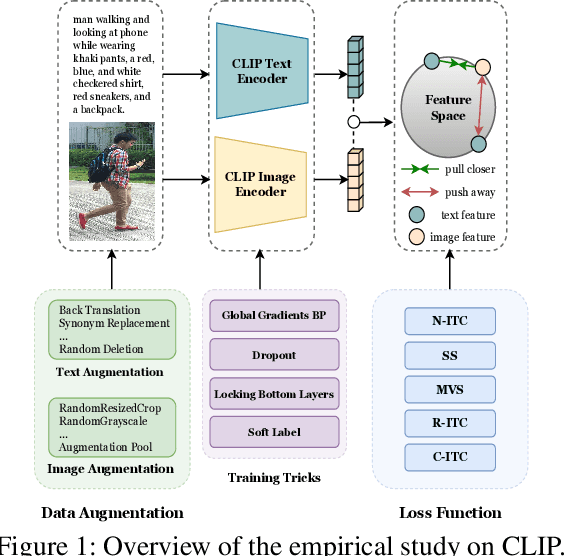
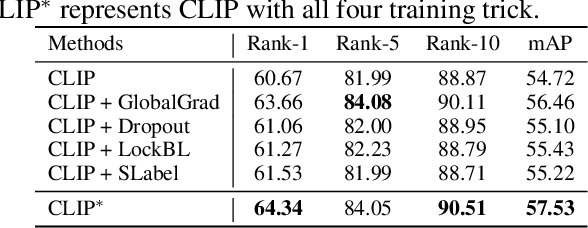
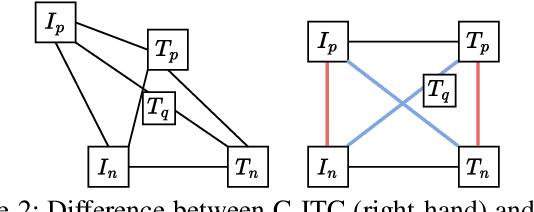
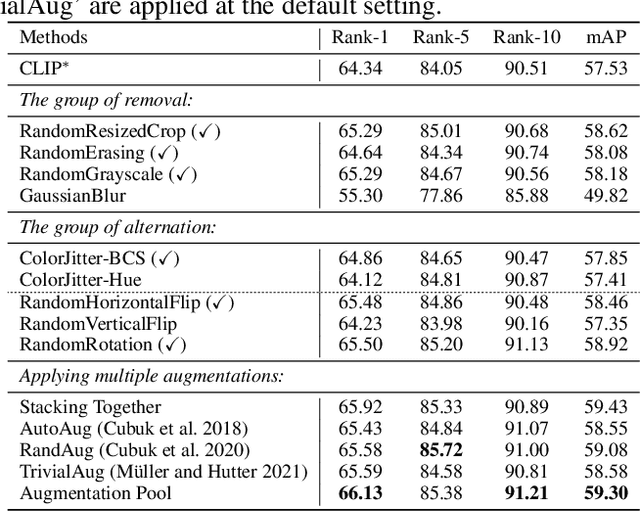
Text-based Person Search (TBPS) aims to retrieve the person images using natural language descriptions. Recently, Contrastive Language Image Pretraining (CLIP), a universal large cross-modal vision-language pre-training model, has remarkably performed over various cross-modal downstream tasks due to its powerful cross-modal semantic learning capacity. TPBS, as a fine-grained cross-modal retrieval task, is also facing the rise of research on the CLIP-based TBPS. In order to explore the potential of the visual-language pre-training model for downstream TBPS tasks, this paper makes the first attempt to conduct a comprehensive empirical study of CLIP for TBPS and thus contribute a straightforward, incremental, yet strong TBPS-CLIP baseline to the TBPS community. We revisit critical design considerations under CLIP, including data augmentation and loss function. The model, with the aforementioned designs and practical training tricks, can attain satisfactory performance without any sophisticated modules. Also, we conduct the probing experiments of TBPS-CLIP in model generalization and model compression, demonstrating the effectiveness of TBPS-CLIP from various aspects. This work is expected to provide empirical insights and highlight future CLIP-based TBPS research.
Heterogeneous Federated Learning: State-of-the-art and Research Challenges
Jul 20, 2023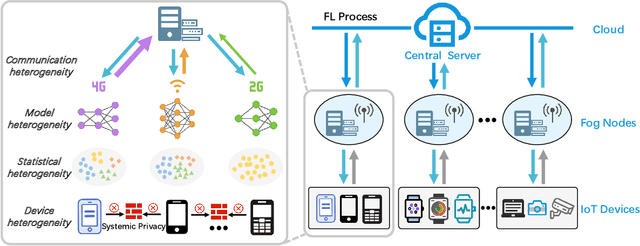
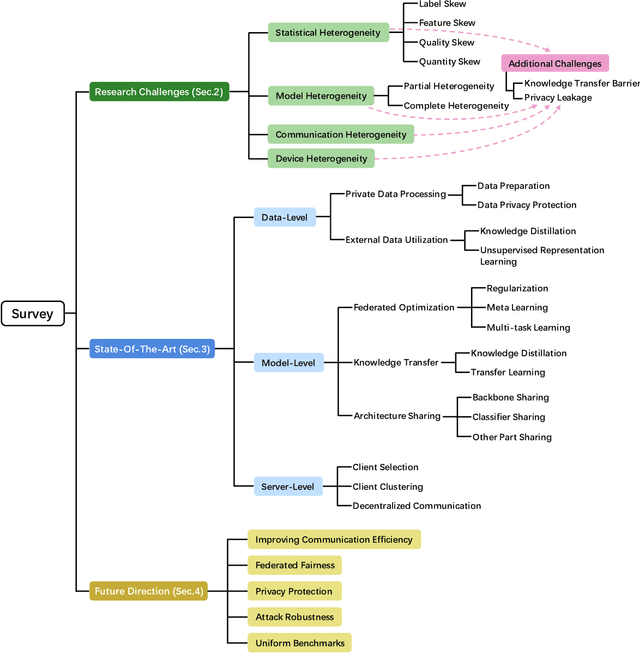
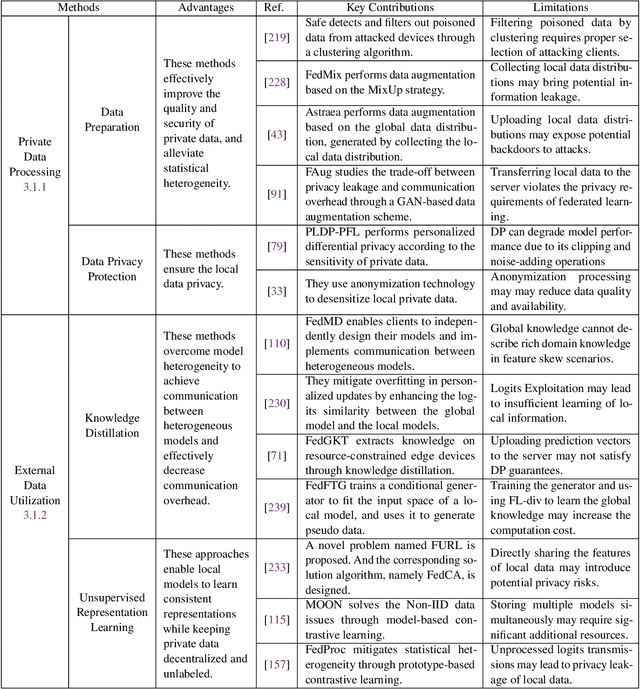
Federated learning (FL) has drawn increasing attention owing to its potential use in large-scale industrial applications. Existing federated learning works mainly focus on model homogeneous settings. However, practical federated learning typically faces the heterogeneity of data distributions, model architectures, network environments, and hardware devices among participant clients. Heterogeneous Federated Learning (HFL) is much more challenging, and corresponding solutions are diverse and complex. Therefore, a systematic survey on this topic about the research challenges and state-of-the-art is essential. In this survey, we firstly summarize the various research challenges in HFL from five aspects: statistical heterogeneity, model heterogeneity, communication heterogeneity, device heterogeneity, and additional challenges. In addition, recent advances in HFL are reviewed and a new taxonomy of existing HFL methods is proposed with an in-depth analysis of their pros and cons. We classify existing methods from three different levels according to the HFL procedure: data-level, model-level, and server-level. Finally, several critical and promising future research directions in HFL are discussed, which may facilitate further developments in this field. A periodically updated collection on HFL is available at https://github.com/marswhu/HFL_Survey.
Symmetric Uncertainty-Aware Feature Transmission for Depth Super-Resolution
Jun 01, 2023

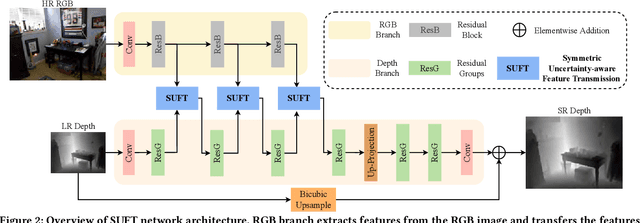
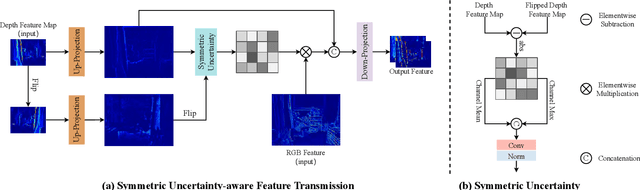
Color-guided depth super-resolution (DSR) is an encouraging paradigm that enhances a low-resolution (LR) depth map guided by an extra high-resolution (HR) RGB image from the same scene. Existing methods usually use interpolation to upscale the depth maps before feeding them into the network and transfer the high-frequency information extracted from HR RGB images to guide the reconstruction of depth maps. However, the extracted high-frequency information usually contains textures that are not present in depth maps in the existence of the cross-modality gap, and the noises would be further aggravated by interpolation due to the resolution gap between the RGB and depth images. To tackle these challenges, we propose a novel Symmetric Uncertainty-aware Feature Transmission (SUFT) for color-guided DSR. (1) For the resolution gap, SUFT builds an iterative up-and-down sampling pipeline, which makes depth features and RGB features spatially consistent while suppressing noise amplification and blurring by replacing common interpolated pre-upsampling. (2) For the cross-modality gap, we propose a novel Symmetric Uncertainty scheme to remove parts of RGB information harmful to the recovery of HR depth maps. Extensive experiments on benchmark datasets and challenging real-world settings suggest that our method achieves superior performance compared to state-of-the-art methods. Our code and models are available at https://github.com/ShiWuxuan/SUFT.