 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoyuan Chen
PreAfford: Universal Affordance-Based Pre-Grasping for Diverse Objects and Environments
Apr 04, 2024
Robotic manipulation of ungraspable objects with two-finger grippers presents significant challenges due to the paucity of graspable features, while traditional pre-grasping techniques, which rely on repositioning objects and leveraging external aids like table edges, lack the adaptability across object categories and scenes. Addressing this, we introduce PreAfford, a novel pre-grasping planning framework that utilizes a point-level affordance representation and a relay training approach to enhance adaptability across a broad range of environments and object types, including those previously unseen. Demonstrated on the ShapeNet-v2 dataset, PreAfford significantly improves grasping success rates by 69% and validates its practicality through real-world experiments. This work offers a robust and adaptable solution for manipulating ungraspable objects.
Rethinking Software Engineering in the Foundation Model Era: A Curated Catalogue of Challenges in the Development of Trustworthy FMware
Mar 04, 2024Foundation models (FMs), such as Large Language Models (LLMs), have revolutionized software development by enabling new use cases and business models. We refer to software built using FMs as FMware. The unique properties of FMware (e.g., prompts, agents, and the need for orchestration), coupled with the intrinsic limitations of FMs (e.g., hallucination) lead to a completely new set of software engineering challenges. Based on our industrial experience, we identified 10 key SE4FMware challenges that have caused enterprise FMware development to be unproductive, costly, and risky. In this paper, we discuss these challenges in detail and state the path for innovation that we envision. Next, we present FMArts, which is our long-term effort towards creating a cradle-to-grave platform for the engineering of trustworthy FMware. Finally, we (i) show how the unique properties of FMArts enabled us to design and develop a complex FMware for a large customer in a timely manner and (ii) discuss the lessons that we learned in doing so. We hope that the disclosure of the aforementioned challenges and our associated efforts to tackle them will not only raise awareness but also promote deeper and further discussions, knowledge sharing, and innovative solutions across the software engineering discipline.
Aligner: Achieving Efficient Alignment through Weak-to-Strong Correction
Feb 06, 2024Efforts to align Large Language Models (LLMs) are mainly conducted via Reinforcement Learning from Human Feedback (RLHF) methods. However, RLHF encounters major challenges including training reward models, actor-critic engineering, and importantly, it requires access to LLM parameters. Here we introduce Aligner, a new efficient alignment paradigm that bypasses the whole RLHF process by learning the correctional residuals between the aligned and the unaligned answers. Our Aligner offers several key advantages. Firstly, it is an autoregressive seq2seq model that is trained on the query-answer-correction dataset via supervised learning; this offers a parameter-efficient alignment solution with minimal resources. Secondly, the Aligner facilitates weak-to-strong generalization; finetuning large pretrained models by Aligner's supervisory signals demonstrates strong performance boost. Thirdly, Aligner functions as a model-agnostic plug-and-play module, allowing for its direct application on different open-source and API-based models. Remarkably, Aligner-7B improves 11 different LLMs by 21.9% in helpfulness and 23.8% in harmlessness on average (GPT-4 by 17.5% and 26.9%). When finetuning (strong) Llama2-70B with (weak) Aligner-13B's supervision, we can improve Llama2 by 8.2% in helpfulness and 61.6% in harmlessness. See our dataset and code at https://aligner2024.github.io
DittoGym: Learning to Control Soft Shape-Shifting Robots
Jan 29, 2024Robot co-design, where the morphology of a robot is optimized jointly with a learned policy to solve a specific task, is an emerging area of research. It holds particular promise for soft robots, which are amenable to novel manufacturing techniques that can realize learned morphologies and actuators. Inspired by nature and recent novel robot designs, we propose to go a step further and explore the novel reconfigurable robots, defined as robots that can change their morphology within their lifetime. We formalize control of reconfigurable soft robots as a high-dimensional reinforcement learning (RL) problem. We unify morphology change, locomotion, and environment interaction in the same action space, and introduce an appropriate, coarse-to-fine curriculum that enables us to discover policies that accomplish fine-grained control of the resulting robots. We also introduce DittoGym, a comprehensive RL benchmark for reconfigurable soft robots that require fine-grained morphology changes to accomplish the tasks. Finally, we evaluate our proposed coarse-to-fine algorithm on DittoGym and demonstrate robots that learn to change their morphology several times within a sequence, uniquely enabled by our RL algorithm. More results are available at https://dittogym.github.io.
SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
Jan 22, 2024Understanding and reasoning about spatial relationships is a fundamental capability for Visual Question Answering (VQA) and robotics. While Vision Language Models (VLM) have demonstrated remarkable performance in certain VQA benchmarks, they still lack capabilities in 3D spatial reasoning, such as recognizing quantitative relationships of physical objects like distances or size differences. We hypothesize that VLMs' limited spatial reasoning capability is due to the lack of 3D spatial knowledge in training data and aim to solve this problem by training VLMs with Internet-scale spatial reasoning data. To this end, we present a system to facilitate this approach. We first develop an automatic 3D spatial VQA data generation framework that scales up to 2 billion VQA examples on 10 million real-world images. We then investigate various factors in the training recipe, including data quality, training pipeline, and VLM architecture. Our work features the first internet-scale 3D spatial reasoning dataset in metric space. By training a VLM on such data, we significantly enhance its ability on both qualitative and quantitative spatial VQA. Finally, we demonstrate that this VLM unlocks novel downstream applications in chain-of-thought spatial reasoning and robotics due to its quantitative estimation capability. Project website: https://spatial-vlm.github.io/
Towards End-to-End Structure Solutions from Information-Compromised Diffraction Data via Generative Deep Learning
Dec 23, 2023The revolution in materials in the past century was built on a knowledge of the atomic arrangements and the structure-property relationship. The sine qua non for obtaining quantitative structural information is single crystal crystallography. However, increasingly we need to solve structures in cases where the information content in our input signal is significantly degraded, for example, due to orientational averaging of grains, finite size effects due to nanostructure, and mixed signals due to sample heterogeneity. Understanding the structure property relationships in such situations is, if anything, more important and insightful, yet we do not have robust approaches for accomplishing it. In principle, machine learning (ML) and deep learning (DL) are promising approaches since they augment information in the degraded input signal with prior knowledge learned from large databases of already known structures. Here we present a novel ML approach, a variational query-based multi-branch deep neural network that has the promise to be a robust but general tool to address this problem end-to-end. We demonstrate the approach on computed powder x-ray diffraction (PXRD), along with partial chemical composition information, as input. We choose as a structural representation a modified electron density we call the Cartesian mapped electron density (CMED), that straightforwardly allows our ML model to learn material structures across different chemistries, symmetries and crystal systems. When evaluated on theoretically simulated data for the cubic and trigonal crystal systems, the system achieves up to $93.4\%$ average similarity with the ground truth on unseen materials, both with known and partially-known chemical composition information, showing great promise for successful structure solution even from degraded and incomplete input data.
AI Alignment: A Comprehensive Survey
Nov 01, 2023AI alignment aims to make AI systems behave in line with human intentions and values. As AI systems grow more capable, the potential large-scale risks associated with misaligned AI systems become salient. Hundreds of AI experts and public figures have expressed concerns about AI risks, arguing that "mitigating the risk of extinction from AI should be a global priority, alongside other societal-scale risks such as pandemics and nuclear war". To provide a comprehensive and up-to-date overview of the alignment field, in this survey paper, we delve into the core concepts, methodology, and practice of alignment. We identify the RICE principles as the key objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality. Guided by these four principles, we outline the landscape of current alignment research and decompose them into two key components: forward alignment and backward alignment. The former aims to make AI systems aligned via alignment training, while the latter aims to gain evidence about the systems' alignment and govern them appropriately to avoid exacerbating misalignment risks. Forward alignment and backward alignment form a recurrent process where the alignment of AI systems from the forward process is verified in the backward process, meanwhile providing updated objectives for forward alignment in the next round. On forward alignment, we discuss learning from feedback and learning under distribution shift. On backward alignment, we discuss assurance techniques and governance practices that apply to every stage of AI systems' lifecycle. We also release and continually update the website (www.alignmentsurvey.com) which features tutorials, collections of papers, blog posts, and other resources.
Policy Stitching: Learning Transferable Robot Policies
Sep 24, 2023Training robots with reinforcement learning (RL) typically involves heavy interactions with the environment, and the acquired skills are often sensitive to changes in task environments and robot kinematics. Transfer RL aims to leverage previous knowledge to accelerate learning of new tasks or new body configurations. However, existing methods struggle to generalize to novel robot-task combinations and scale to realistic tasks due to complex architecture design or strong regularization that limits the capacity of the learned policy. We propose Policy Stitching, a novel framework that facilitates robot transfer learning for novel combinations of robots and tasks. Our key idea is to apply modular policy design and align the latent representations between the modular interfaces. Our method allows direct stitching of the robot and task modules trained separately to form a new policy for fast adaptation. Our simulated and real-world experiments on various 3D manipulation tasks demonstrate the superior zero-shot and few-shot transfer learning performances of our method. Our project website is at: http://generalroboticslab.com/PolicyStitching/ .
Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks
Aug 01, 2023
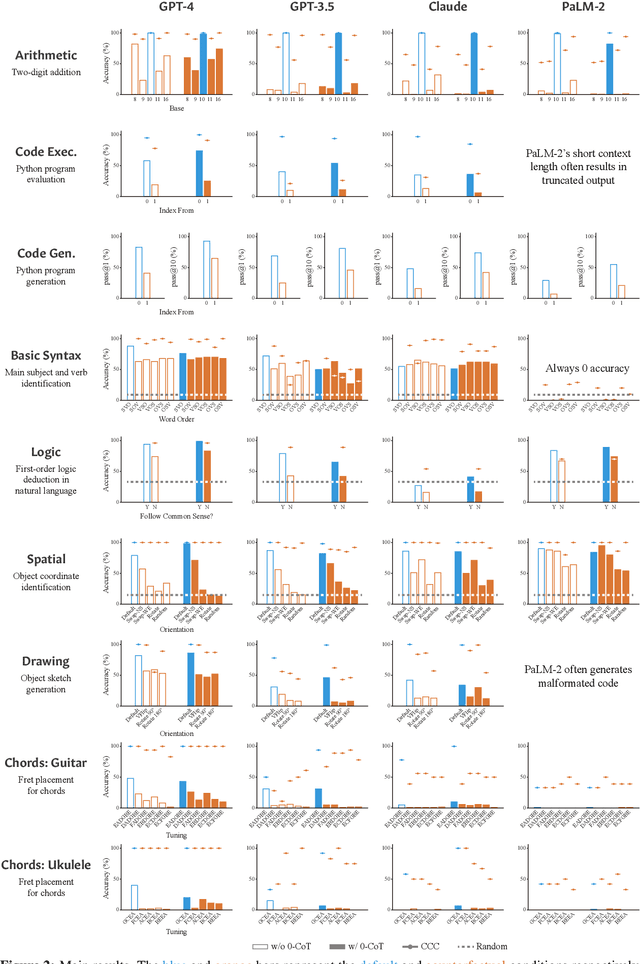

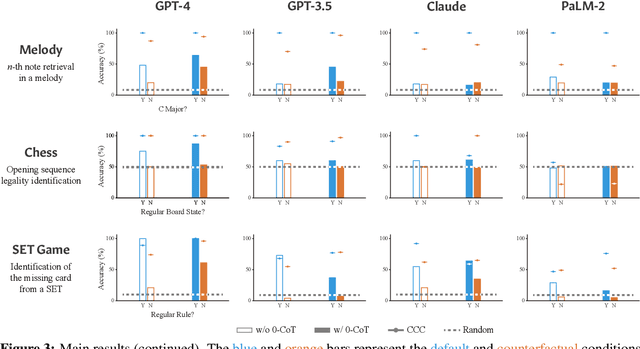
The impressive performance of recent language models across a wide range of tasks suggests that they possess a degree of abstract reasoning skills. Are these skills general and transferable, or specialized to specific tasks seen during pretraining? To disentangle these effects, we propose an evaluation framework based on "counterfactual" task variants that deviate from the default assumptions underlying standard tasks. Across a suite of 11 tasks, we observe nontrivial performance on the counterfactual variants, but nevertheless find that performance substantially and consistently degrades compared to the default conditions. This suggests that while current LMs may possess abstract task-solving skills to a degree, they often also rely on narrow, non-transferable procedures for task-solving. These results motivate a more careful interpretation of language model performance that teases apart these aspects of behavior.
Self-Supervised Reinforcement Learning that Transfers using Random Features
May 26, 2023
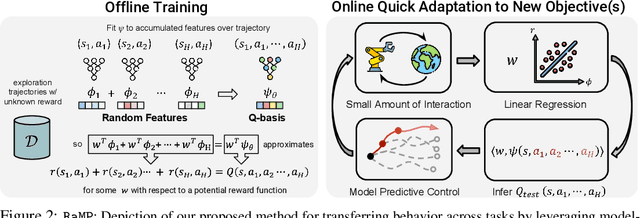


Model-free reinforcement learning algorithms have exhibited great potential in solving single-task sequential decision-making problems with high-dimensional observations and long horizons, but are known to be hard to generalize across tasks. Model-based RL, on the other hand, learns task-agnostic models of the world that naturally enables transfer across different reward functions, but struggles to scale to complex environments due to the compounding error. To get the best of both worlds, we propose a self-supervised reinforcement learning method that enables the transfer of behaviors across tasks with different rewards, while circumventing the challenges of model-based RL. In particular, we show self-supervised pre-training of model-free reinforcement learning with a number of random features as rewards allows implicit modeling of long-horizon environment dynamics. Then, planning techniques like model-predictive control using these implicit models enable fast adaptation to problems with new reward functions. Our method is self-supervised in that it can be trained on offline datasets without reward labels, but can then be quickly deployed on new tasks. We validate that our proposed method enables transfer across tasks on a variety of manipulation and locomotion domains in simulation, opening the door to generalist decision-making agents.