 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHod Lipson
Reconfigurable Robot Identification from Motion Data
Mar 15, 2024
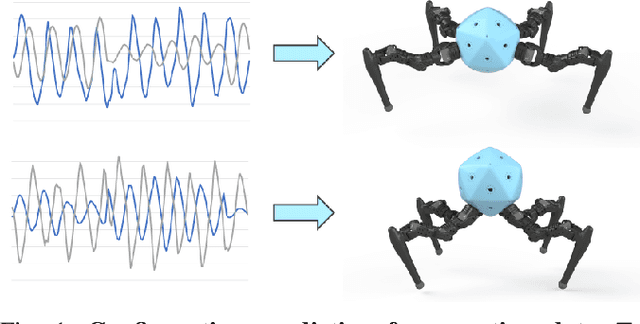
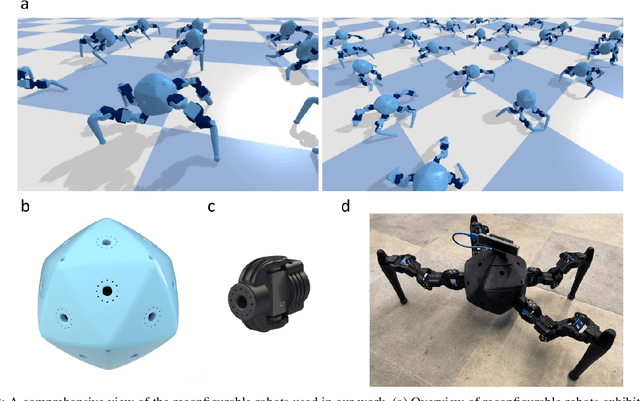
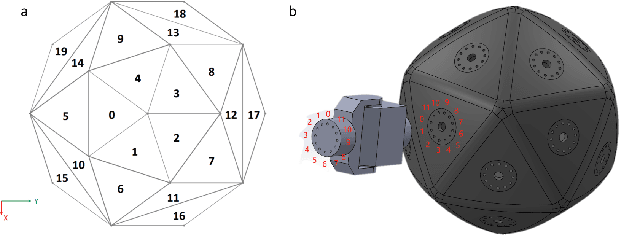
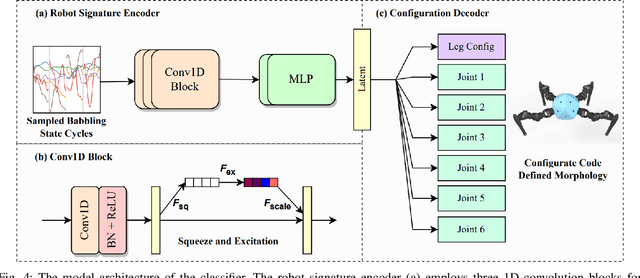
Integrating Large Language Models (VLMs) and Vision-Language Models (VLMs) with robotic systems enables robots to process and understand complex natural language instructions and visual information. However, a fundamental challenge remains: for robots to fully capitalize on these advancements, they must have a deep understanding of their physical embodiment. The gap between AI models cognitive capabilities and the understanding of physical embodiment leads to the following question: Can a robot autonomously understand and adapt to its physical form and functionalities through interaction with its environment? This question underscores the transition towards developing self-modeling robots without reliance on external sensory or pre-programmed knowledge about their structure. Here, we propose a meta self modeling that can deduce robot morphology through proprioception (the internal sense of position and movement). Our study introduces a 12 DoF reconfigurable legged robot, accompanied by a diverse dataset of 200k unique configurations, to systematically investigate the relationship between robotic motion and robot morphology. Utilizing a deep neural network model comprising a robot signature encoder and a configuration decoder, we demonstrate the capability of our system to accurately predict robot configurations from proprioceptive signals. This research contributes to the field of robotic self-modeling, aiming to enhance understanding of their physical embodiment and adaptability in real world scenarios.
Towards End-to-End Structure Solutions from Information-Compromised Diffraction Data via Generative Deep Learning
Dec 23, 2023The revolution in materials in the past century was built on a knowledge of the atomic arrangements and the structure-property relationship. The sine qua non for obtaining quantitative structural information is single crystal crystallography. However, increasingly we need to solve structures in cases where the information content in our input signal is significantly degraded, for example, due to orientational averaging of grains, finite size effects due to nanostructure, and mixed signals due to sample heterogeneity. Understanding the structure property relationships in such situations is, if anything, more important and insightful, yet we do not have robust approaches for accomplishing it. In principle, machine learning (ML) and deep learning (DL) are promising approaches since they augment information in the degraded input signal with prior knowledge learned from large databases of already known structures. Here we present a novel ML approach, a variational query-based multi-branch deep neural network that has the promise to be a robust but general tool to address this problem end-to-end. We demonstrate the approach on computed powder x-ray diffraction (PXRD), along with partial chemical composition information, as input. We choose as a structural representation a modified electron density we call the Cartesian mapped electron density (CMED), that straightforwardly allows our ML model to learn material structures across different chemistries, symmetries and crystal systems. When evaluated on theoretically simulated data for the cubic and trigonal crystal systems, the system achieves up to $93.4\%$ average similarity with the ground truth on unseen materials, both with known and partially-known chemical composition information, showing great promise for successful structure solution even from degraded and incomplete input data.
Balanced and Deterministic Weight-sharing Helps Network Performance
Dec 13, 2023Weight-sharing plays a significant role in the success of many deep neural networks, by increasing memory efficiency and incorporating useful inductive priors about the problem into the network. But understanding how weight-sharing can be used effectively in general is a topic that has not been studied extensively. Chen et al. [2015] proposed HashedNets, which augments a multi-layer perceptron with a hash table, as a method for neural network compression. We generalize this method into a framework (ArbNets) that allows for efficient arbitrary weight-sharing, and use it to study the role of weight-sharing in neural networks. We show that common neural networks can be expressed as ArbNets with different hash functions. We also present two novel hash functions, the Dirichlet hash and the Neighborhood hash, and use them to demonstrate experimentally that balanced and deterministic weight-sharing helps with the performance of a neural network.
Accelerating Meta-Learning by Sharing Gradients
Dec 13, 2023The success of gradient-based meta-learning is primarily attributed to its ability to leverage related tasks to learn task-invariant information. However, the absence of interactions between different tasks in the inner loop leads to task-specific over-fitting in the initial phase of meta-training. While this is eventually corrected by the presence of these interactions in the outer loop, it comes at a significant cost of slower meta-learning. To address this limitation, we explicitly encode task relatedness via an inner loop regularization mechanism inspired by multi-task learning. Our algorithm shares gradient information from previously encountered tasks as well as concurrent tasks in the same task batch, and scales their contribution with meta-learned parameters. We show using two popular few-shot classification datasets that gradient sharing enables meta-learning under bigger inner loop learning rates and can accelerate the meta-training process by up to 134%.
Principled Weight Initialization for Hypernetworks
Dec 13, 2023Hypernetworks are meta neural networks that generate weights for a main neural network in an end-to-end differentiable manner. Despite extensive applications ranging from multi-task learning to Bayesian deep learning, the problem of optimizing hypernetworks has not been studied to date. We observe that classical weight initialization methods like Glorot & Bengio (2010) and He et al. (2015), when applied directly on a hypernet, fail to produce weights for the mainnet in the correct scale. We develop principled techniques for weight initialization in hypernets, and show that they lead to more stable mainnet weights, lower training loss, and faster convergence.
Assessing SATNet's Ability to Solve the Symbol Grounding Problem
Dec 13, 2023SATNet is an award-winning MAXSAT solver that can be used to infer logical rules and integrated as a differentiable layer in a deep neural network. It had been shown to solve Sudoku puzzles visually from examples of puzzle digit images, and was heralded as an impressive achievement towards the longstanding AI goal of combining pattern recognition with logical reasoning. In this paper, we clarify SATNet's capabilities by showing that in the absence of intermediate labels that identify individual Sudoku digit images with their logical representations, SATNet completely fails at visual Sudoku (0% test accuracy). More generally, the failure can be pinpointed to its inability to learn to assign symbols to perceptual phenomena, also known as the symbol grounding problem, which has long been thought to be a prerequisite for intelligent agents to perform real-world logical reasoning. We propose an MNIST based test as an easy instance of the symbol grounding problem that can serve as a sanity check for differentiable symbolic solvers in general. Naive applications of SATNet on this test lead to performance worse than that of models without logical reasoning capabilities. We report on the causes of SATNet's failure and how to prevent them.
Teaching Robots to Build Simulations of Themselves
Nov 20, 2023Simulation enables robots to plan and estimate the outcomes of prospective actions without the need to physically execute them. We introduce a self-supervised learning framework to enable robots model and predict their morphology, kinematics and motor control using only brief raw video data, eliminating the need for extensive real-world data collection and kinematic priors. By observing their own movements, akin to humans watching their reflection in a mirror, robots learn an ability to simulate themselves and predict their spatial motion for various tasks. Our results demonstrate that this self-learned simulation not only enables accurate motion planning but also allows the robot to detect abnormalities and recover from damage.
Designing a Hair-Clip Inspired Bistable Mechanism for Soft Fish Robots
Nov 06, 2023The Hair clip mechanism (HCM) is an in-plane prestressed bistable mechanism proposed in our previous research [1]~[5] to enhance the functionality of soft robotics. HCMs have several advantages, such as high rigidity, high mobility, good repeatability, and design and fabrication simplicity, compared to existing soft and compliant robotics. Using our experience with fish robots, this work delves into designing a novel HCM robotic propulsion system made from PETG plastic, carbon fiber-reinforced plastic (CFRP), and steel. Detailed derivation and verification of the HCM theory are given, and the influence of key parameters like dimensions, material types, and servo motor specifications are summarized. The designing algorithm offers insight into HCM robotics. It enables us to search for suitable components, operate robots at a desired frequency, and achieve high-frequency and high-speed undulatory swimming for fish robots.
CarbonFish -- A Bistable Underactuated Compliant Fish Robot capable of High Frequency Undulation
Nov 06, 2023The Hair Clip Mechanism HCM represents an innovative in plane prestressed bistable mechanism, as delineated in our preceding studies, devised to augment the functional prowess of soft robotics. When juxtaposed with conventional soft and compliant robotic systems, HCMs exhibit pronounced rigidity, augmented mobility, reproducible repeatability, and an effective design and fabrication paradigm. In this research, we investigate the feasibility of utilizing carbon fiber reinforced plastic CFRP as the foundational material for an HCM based fish robot, herein referred to as CarbonFish. Our objective centers on realizing high frequency undulatory motion, thereby laying the groundwork for accelerated aquatic locomotion in subsequent models. We proffer an exhaustive design and fabrication schema underpinned by mathematical principles. Preliminary evaluations of our single actuated CarbonFish have evidenced an undulation frequency approaching 10 Hz, suggesting its potential to outperform other biologically inspired aquatic entities as well as real fish.
Knolling bot 2.0: Enhancing Object Organization with Self-supervised Graspability Estimation
Oct 30, 2023Building on recent advancements in transformer based approaches for domestic robots performing knolling, the art of organizing scattered items into neat arrangements. This paper introduces Knolling bot 2.0. Recognizing the challenges posed by piles of objects or items situated closely together, this upgraded system incorporates a self-supervised graspability estimation model. If objects are deemed ungraspable, an additional behavior will be executed to separate the objects before knolling the table. By integrating this grasp prediction mechanism with existing visual perception and transformer based knolling models, an advanced system capable of decluttering and organizing even more complex and densely populated table settings is demonstrated. Experimental evaluations demonstrate the effectiveness of this module, yielding a graspability prediction accuracy of 95.7%.