 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianwei Niu
Scaffold-BPE: Enhancing Byte Pair Encoding with Simple and Effective Scaffold Token Removal
Apr 27, 2024
Byte Pair Encoding (BPE) serves as a foundation method for text tokenization in the Natural Language Processing (NLP) field. Despite its wide adoption, the original BPE algorithm harbors an inherent flaw: it inadvertently introduces a frequency imbalance for tokens in the text corpus. Since BPE iteratively merges the most frequent token pair in the text corpus while keeping all tokens that have been merged in the vocabulary, it unavoidably holds tokens that primarily represent subwords of complete words and appear infrequently on their own in the text corpus. We term such tokens as Scaffold Tokens. Due to their infrequent appearance in the text corpus, Scaffold Tokens pose a learning imbalance issue for language models. To address that issue, we propose Scaffold-BPE, which incorporates a dynamic scaffold token removal mechanism by parameter-free, computation-light, and easy-to-implement modifications to the original BPE. This novel approach ensures the exclusion of low-frequency Scaffold Tokens from the token representations for the given texts, thereby mitigating the issue of frequency imbalance and facilitating model training. On extensive experiments across language modeling tasks and machine translation tasks, Scaffold-BPE consistently outperforms the original BPE, well demonstrating its effectiveness and superiority.
Temporal Scaling Law for Large Language Models
Apr 27, 2024Recently, Large Language Models (LLMs) are widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed as Scaling Laws, have discovered that the loss of LLMs scales as power laws with model size, computational budget, and dataset size. However, the performance of LLMs throughout the training process remains untouched. In this paper, we propose the novel concept of Temporal Scaling Law and study the loss of LLMs from the temporal dimension. We first investigate the imbalance of loss on each token positions and develop a reciprocal-law across model scales and training stages. We then derive the temporal scaling law by studying the temporal patterns of the reciprocal-law parameters. Results on both in-distribution (IID) data and out-of-distribution (OOD) data demonstrate that our temporal scaling law accurately predicts the performance of LLMs in future training stages. Moreover, the temporal scaling law reveals that LLMs learn uniformly on different token positions, despite the loss imbalance. Experiments on pre-training LLMs in various scales show that this phenomenon verifies the default training paradigm for generative language models, in which no re-weighting strategies are attached during training. Overall, the temporal scaling law provides deeper insight into LLM pre-training.
End-To-End Underwater Video Enhancement: Dataset and Model
Mar 18, 2024

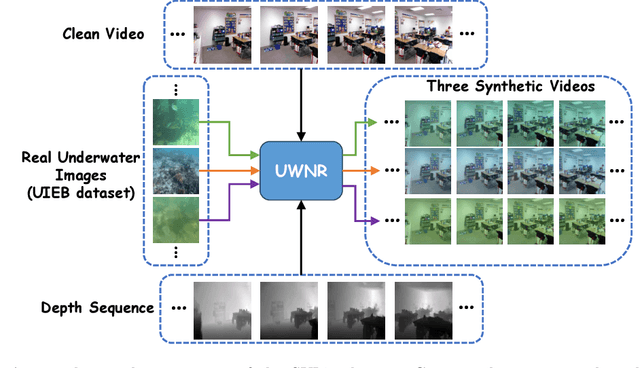
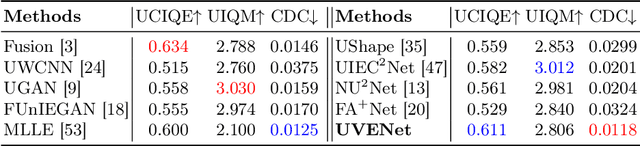
Underwater video enhancement (UVE) aims to improve the visibility and frame quality of underwater videos, which has significant implications for marine research and exploration. However, existing methods primarily focus on developing image enhancement algorithms to enhance each frame independently. There is a lack of supervised datasets and models specifically tailored for UVE tasks. To fill this gap, we construct the Synthetic Underwater Video Enhancement (SUVE) dataset, comprising 840 diverse underwater-style videos paired with ground-truth reference videos. Based on this dataset, we train a novel underwater video enhancement model, UVENet, which utilizes inter-frame relationships to achieve better enhancement performance. Through extensive experiments on both synthetic and real underwater videos, we demonstrate the effectiveness of our approach. This study represents the first comprehensive exploration of UVE to our knowledge. The code is available at https://anonymous.4open.science/r/UVENet.
Joint Attention-Guided Feature Fusion Network for Saliency Detection of Surface Defects
Feb 05, 2024Surface defect inspection plays an important role in the process of industrial manufacture and production. Though Convolutional Neural Network (CNN) based defect inspection methods have made huge leaps, they still confront a lot of challenges such as defect scale variation, complex background, low contrast, and so on. To address these issues, we propose a joint attention-guided feature fusion network (JAFFNet) for saliency detection of surface defects based on the encoder-decoder network. JAFFNet mainly incorporates a joint attention-guided feature fusion (JAFF) module into decoding stages to adaptively fuse low-level and high-level features. The JAFF module learns to emphasize defect features and suppress background noise during feature fusion, which is beneficial for detecting low-contrast defects. In addition, JAFFNet introduces a dense receptive field (DRF) module following the encoder to capture features with rich context information, which helps detect defects of different scales. The JAFF module mainly utilizes a learned joint channel-spatial attention map provided by high-level semantic features to guide feature fusion. The attention map makes the model pay more attention to defect features. The DRF module utilizes a sequence of multi-receptive-field (MRF) units with each taking as inputs all the preceding MRF feature maps and the original input. The obtained DRF features capture rich context information with a large range of receptive fields. Extensive experiments conducted on SD-saliency-900, Magnetic tile, and DAGM 2007 indicate that our method achieves promising performance in comparison with other state-of-the-art methods. Meanwhile, our method reaches a real-time defect detection speed of 66 FPS.
NID-SLAM: Neural Implicit Representation-based RGB-D SLAM in dynamic environments
Jan 02, 2024Neural implicit representations have been explored to enhance visual SLAM algorithms, especially in providing high-fidelity dense map. Existing methods operate robustly in static scenes but struggle with the disruption caused by moving objects. In this paper we present NID-SLAM, which significantly improves the performance of neural SLAM in dynamic environments. We propose a new approach to enhance inaccurate regions in semantic masks, particularly in marginal areas. Utilizing the geometric information present in depth images, this method enables accurate removal of dynamic objects, thereby reducing the probability of camera drift. Additionally, we introduce a keyframe selection strategy for dynamic scenes, which enhances camera tracking robustness against large-scale objects and improves the efficiency of mapping. Experiments on publicly available RGB-D datasets demonstrate that our method outperforms competitive neural SLAM approaches in tracking accuracy and mapping quality in dynamic environments.
UIEDP:Underwater Image Enhancement with Diffusion Prior
Dec 11, 2023Underwater image enhancement (UIE) aims to generate clear images from low-quality underwater images. Due to the unavailability of clear reference images, researchers often synthesize them to construct paired datasets for training deep models. However, these synthesized images may sometimes lack quality, adversely affecting training outcomes. To address this issue, we propose UIE with Diffusion Prior (UIEDP), a novel framework treating UIE as a posterior distribution sampling process of clear images conditioned on degraded underwater inputs. Specifically, UIEDP combines a pre-trained diffusion model capturing natural image priors with any existing UIE algorithm, leveraging the latter to guide conditional generation. The diffusion prior mitigates the drawbacks of inferior synthetic images, resulting in higher-quality image generation. Extensive experiments have demonstrated that our UIEDP yields significant improvements across various metrics, especially no-reference image quality assessment. And the generated enhanced images also exhibit a more natural appearance.
Bold but Cautious: Unlocking the Potential of Personalized Federated Learning through Cautiously Aggressive Collaboration
Sep 20, 2023

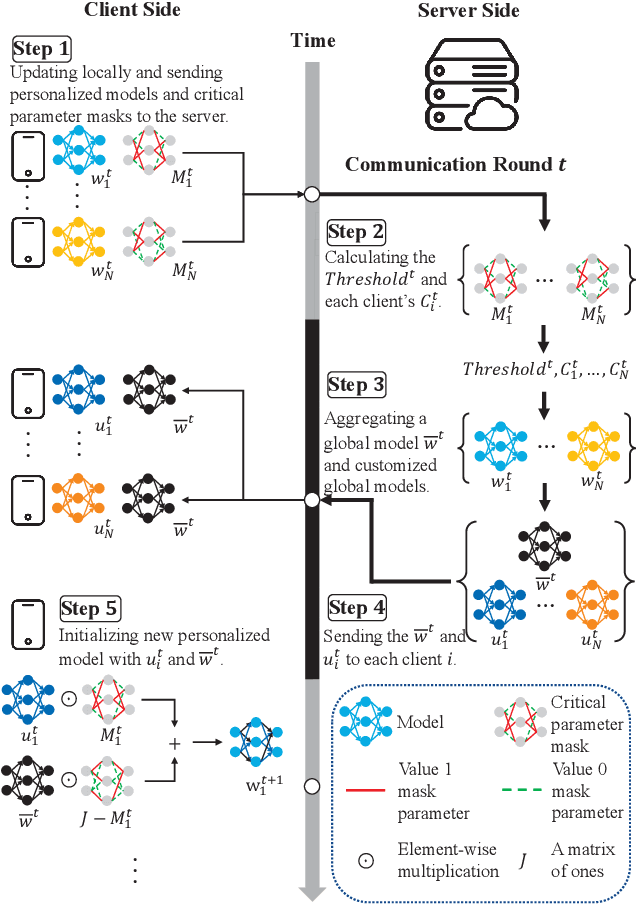
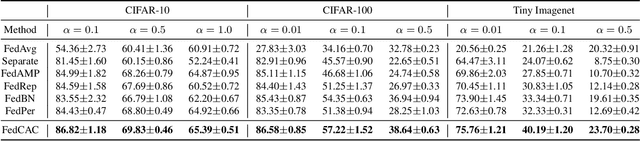
Personalized federated learning (PFL) reduces the impact of non-independent and identically distributed (non-IID) data among clients by allowing each client to train a personalized model when collaborating with others. A key question in PFL is to decide which parameters of a client should be localized or shared with others. In current mainstream approaches, all layers that are sensitive to non-IID data (such as classifier layers) are generally personalized. The reasoning behind this approach is understandable, as localizing parameters that are easily influenced by non-IID data can prevent the potential negative effect of collaboration. However, we believe that this approach is too conservative for collaboration. For example, for a certain client, even if its parameters are easily influenced by non-IID data, it can still benefit by sharing these parameters with clients having similar data distribution. This observation emphasizes the importance of considering not only the sensitivity to non-IID data but also the similarity of data distribution when determining which parameters should be localized in PFL. This paper introduces a novel guideline for client collaboration in PFL. Unlike existing approaches that prohibit all collaboration of sensitive parameters, our guideline allows clients to share more parameters with others, leading to improved model performance. Additionally, we propose a new PFL method named FedCAC, which employs a quantitative metric to evaluate each parameter's sensitivity to non-IID data and carefully selects collaborators based on this evaluation. Experimental results demonstrate that FedCAC enables clients to share more parameters with others, resulting in superior performance compared to state-of-the-art methods, particularly in scenarios where clients have diverse distributions.
Take Your Pick: Enabling Effective Personalized Federated Learning within Low-dimensional Feature Space
Jul 26, 2023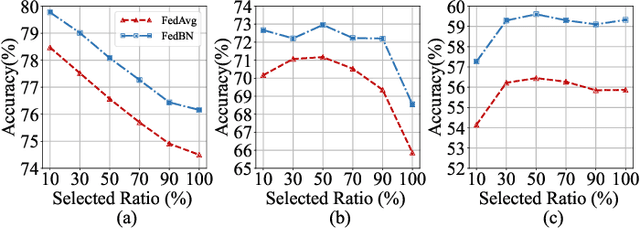

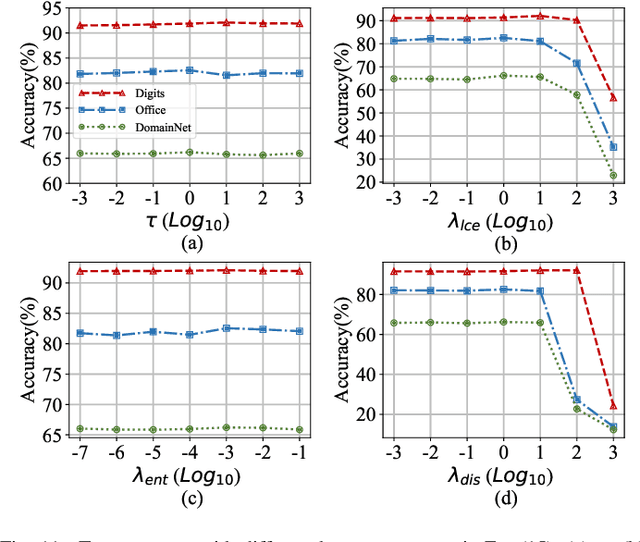

Personalized federated learning (PFL) is a popular framework that allows clients to have different models to address application scenarios where clients' data are in different domains. The typical model of a client in PFL features a global encoder trained by all clients to extract universal features from the raw data and personalized layers (e.g., a classifier) trained using the client's local data. Nonetheless, due to the differences between the data distributions of different clients (aka, domain gaps), the universal features produced by the global encoder largely encompass numerous components irrelevant to a certain client's local task. Some recent PFL methods address the above problem by personalizing specific parameters within the encoder. However, these methods encounter substantial challenges attributed to the high dimensionality and non-linearity of neural network parameter space. In contrast, the feature space exhibits a lower dimensionality, providing greater intuitiveness and interpretability as compared to the parameter space. To this end, we propose a novel PFL framework named FedPick. FedPick achieves PFL in the low-dimensional feature space by selecting task-relevant features adaptively for each client from the features generated by the global encoder based on its local data distribution. It presents a more accessible and interpretable implementation of PFL compared to those methods working in the parameter space. Extensive experimental results show that FedPick could effectively select task-relevant features for each client and improve model performance in cross-domain FL.
3Deformer: A Common Framework for Image-Guided Mesh Deformation
Jul 19, 2023We propose 3Deformer, a general-purpose framework for interactive 3D shape editing. Given a source 3D mesh with semantic materials, and a user-specified semantic image, 3Deformer can accurately edit the source mesh following the shape guidance of the semantic image, while preserving the source topology as rigid as possible. Recent studies of 3D shape editing mostly focus on learning neural networks to predict 3D shapes, which requires high-cost 3D training datasets and is limited to handling objects involved in the datasets. Unlike these studies, our 3Deformer is a non-training and common framework, which only requires supervision of readily-available semantic images, and is compatible with editing various objects unlimited by datasets. In 3Deformer, the source mesh is deformed utilizing the differentiable renderer technique, according to the correspondences between semantic images and mesh materials. However, guiding complex 3D shapes with a simple 2D image incurs extra challenges, that is, the deform accuracy, surface smoothness, geometric rigidity, and global synchronization of the edited mesh should be guaranteed. To address these challenges, we propose a hierarchical optimization architecture to balance the global and local shape features, and propose further various strategies and losses to improve properties of accuracy, smoothness, rigidity, and so on. Extensive experiments show that our 3Deformer is able to produce impressive results and reaches the state-of-the-art level.
Unlocking the Potential of Federated Learning for Deeper Models
Jun 05, 2023



Federated learning (FL) is a new paradigm for distributed machine learning that allows a global model to be trained across multiple clients without compromising their privacy. Although FL has demonstrated remarkable success in various scenarios, recent studies mainly utilize shallow and small neural networks. In our research, we discover a significant performance decline when applying the existing FL framework to deeper neural networks, even when client data are independently and identically distributed (i.i.d.). Our further investigation shows that the decline is due to the continuous accumulation of dissimilarities among client models during the layer-by-layer back-propagation process, which we refer to as "divergence accumulation." As deeper models involve a longer chain of divergence accumulation, they tend to manifest greater divergence, subsequently leading to performance decline. Both theoretical derivations and empirical evidence are proposed to support the existence of divergence accumulation and its amplified effects in deeper models. To address this issue, we propose several technical guidelines based on reducing divergence, such as using wider models and reducing the receptive field. These approaches can greatly improve the accuracy of FL on deeper models. For example, the application of these guidelines can boost the ResNet101 model's performance by as much as 43\% on the Tiny-ImageNet dataset.