 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinghao Wu
Tackling Noisy Labels with Network Parameter Additive Decomposition
Mar 20, 2024
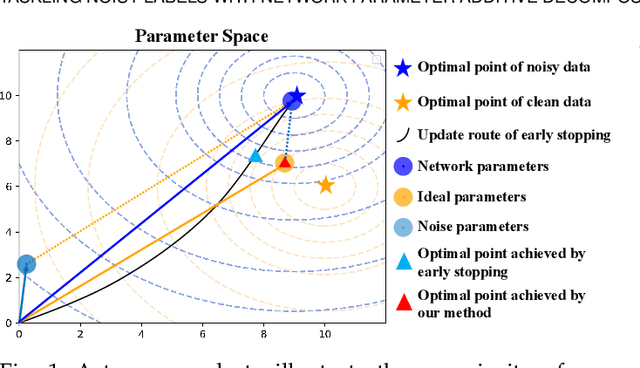
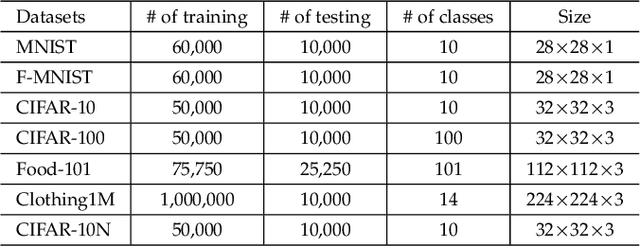
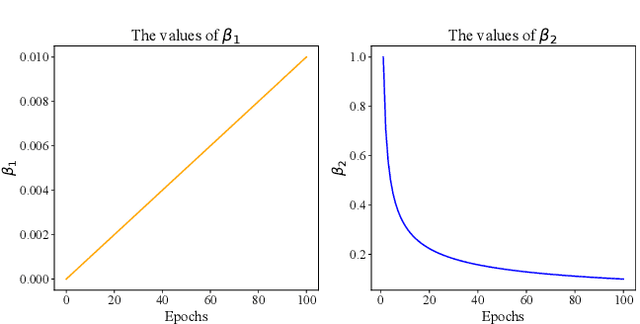
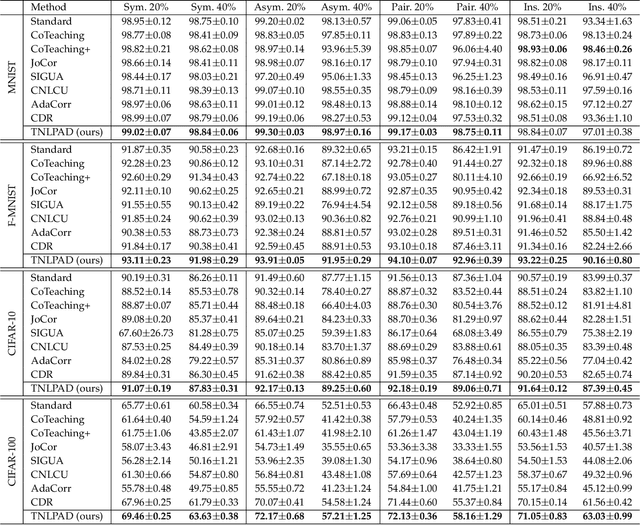
Given data with noisy labels, over-parameterized deep networks suffer overfitting mislabeled data, resulting in poor generalization. The memorization effect of deep networks shows that although the networks have the ability to memorize all noisy data, they would first memorize clean training data, and then gradually memorize mislabeled training data. A simple and effective method that exploits the memorization effect to combat noisy labels is early stopping. However, early stopping cannot distinguish the memorization of clean data and mislabeled data, resulting in the network still inevitably overfitting mislabeled data in the early training stage.In this paper, to decouple the memorization of clean data and mislabeled data, and further reduce the side effect of mislabeled data, we perform additive decomposition on network parameters. Namely, all parameters are additively decomposed into two groups, i.e., parameters $\mathbf{w}$ are decomposed as $\mathbf{w}=\bm{\sigma}+\bm{\gamma}$. Afterward, the parameters $\bm{\sigma}$ are considered to memorize clean data, while the parameters $\bm{\gamma}$ are considered to memorize mislabeled data. Benefiting from the memorization effect, the updates of the parameters $\bm{\sigma}$ are encouraged to fully memorize clean data in early training, and then discouraged with the increase of training epochs to reduce interference of mislabeled data. The updates of the parameters $\bm{\gamma}$ are the opposite. In testing, only the parameters $\bm{\sigma}$ are employed to enhance generalization. Extensive experiments on both simulated and real-world benchmarks confirm the superior performance of our method.
Bold but Cautious: Unlocking the Potential of Personalized Federated Learning through Cautiously Aggressive Collaboration
Sep 20, 2023

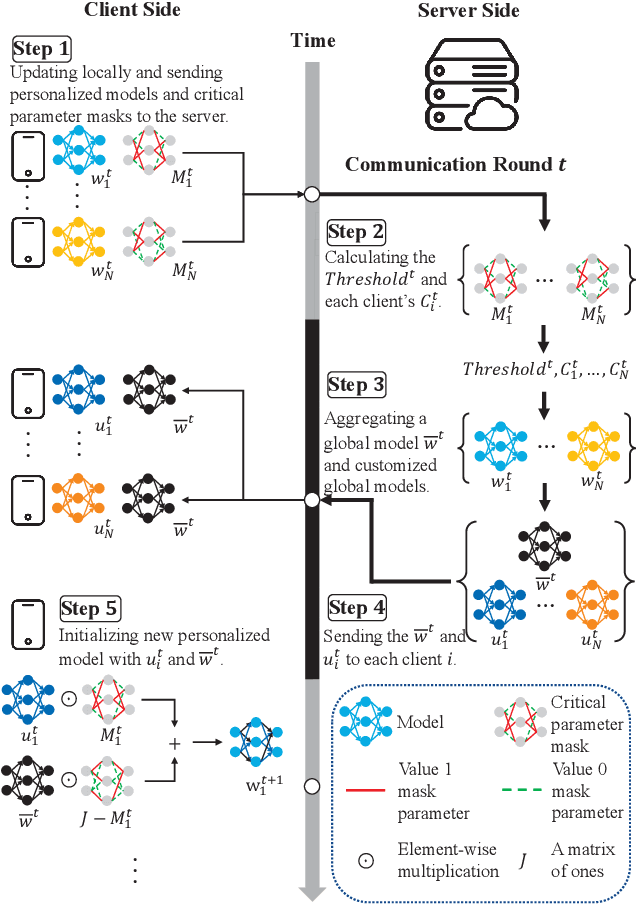
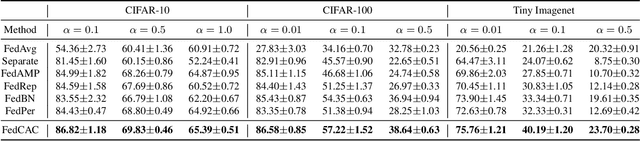
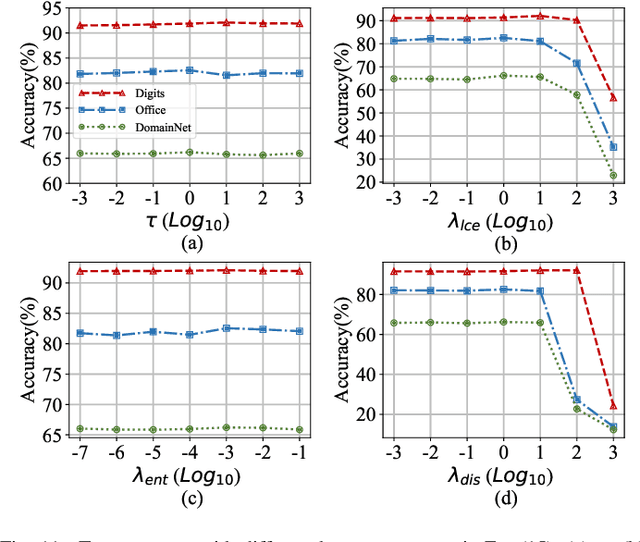
Personalized federated learning (PFL) reduces the impact of non-independent and identically distributed (non-IID) data among clients by allowing each client to train a personalized model when collaborating with others. A key question in PFL is to decide which parameters of a client should be localized or shared with others. In current mainstream approaches, all layers that are sensitive to non-IID data (such as classifier layers) are generally personalized. The reasoning behind this approach is understandable, as localizing parameters that are easily influenced by non-IID data can prevent the potential negative effect of collaboration. However, we believe that this approach is too conservative for collaboration. For example, for a certain client, even if its parameters are easily influenced by non-IID data, it can still benefit by sharing these parameters with clients having similar data distribution. This observation emphasizes the importance of considering not only the sensitivity to non-IID data but also the similarity of data distribution when determining which parameters should be localized in PFL. This paper introduces a novel guideline for client collaboration in PFL. Unlike existing approaches that prohibit all collaboration of sensitive parameters, our guideline allows clients to share more parameters with others, leading to improved model performance. Additionally, we propose a new PFL method named FedCAC, which employs a quantitative metric to evaluate each parameter's sensitivity to non-IID data and carefully selects collaborators based on this evaluation. Experimental results demonstrate that FedCAC enables clients to share more parameters with others, resulting in superior performance compared to state-of-the-art methods, particularly in scenarios where clients have diverse distributions.
Take Your Pick: Enabling Effective Personalized Federated Learning within Low-dimensional Feature Space
Jul 26, 2023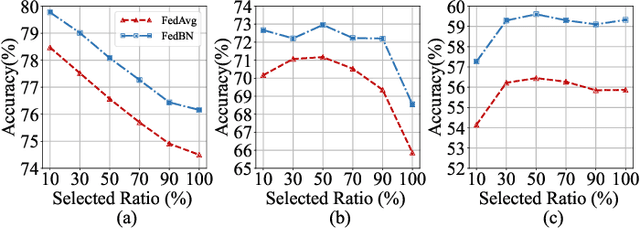


Personalized federated learning (PFL) is a popular framework that allows clients to have different models to address application scenarios where clients' data are in different domains. The typical model of a client in PFL features a global encoder trained by all clients to extract universal features from the raw data and personalized layers (e.g., a classifier) trained using the client's local data. Nonetheless, due to the differences between the data distributions of different clients (aka, domain gaps), the universal features produced by the global encoder largely encompass numerous components irrelevant to a certain client's local task. Some recent PFL methods address the above problem by personalizing specific parameters within the encoder. However, these methods encounter substantial challenges attributed to the high dimensionality and non-linearity of neural network parameter space. In contrast, the feature space exhibits a lower dimensionality, providing greater intuitiveness and interpretability as compared to the parameter space. To this end, we propose a novel PFL framework named FedPick. FedPick achieves PFL in the low-dimensional feature space by selecting task-relevant features adaptively for each client from the features generated by the global encoder based on its local data distribution. It presents a more accessible and interpretable implementation of PFL compared to those methods working in the parameter space. Extensive experimental results show that FedPick could effectively select task-relevant features for each client and improve model performance in cross-domain FL.
3Deformer: A Common Framework for Image-Guided Mesh Deformation
Jul 19, 2023We propose 3Deformer, a general-purpose framework for interactive 3D shape editing. Given a source 3D mesh with semantic materials, and a user-specified semantic image, 3Deformer can accurately edit the source mesh following the shape guidance of the semantic image, while preserving the source topology as rigid as possible. Recent studies of 3D shape editing mostly focus on learning neural networks to predict 3D shapes, which requires high-cost 3D training datasets and is limited to handling objects involved in the datasets. Unlike these studies, our 3Deformer is a non-training and common framework, which only requires supervision of readily-available semantic images, and is compatible with editing various objects unlimited by datasets. In 3Deformer, the source mesh is deformed utilizing the differentiable renderer technique, according to the correspondences between semantic images and mesh materials. However, guiding complex 3D shapes with a simple 2D image incurs extra challenges, that is, the deform accuracy, surface smoothness, geometric rigidity, and global synchronization of the edited mesh should be guaranteed. To address these challenges, we propose a hierarchical optimization architecture to balance the global and local shape features, and propose further various strategies and losses to improve properties of accuracy, smoothness, rigidity, and so on. Extensive experiments show that our 3Deformer is able to produce impressive results and reaches the state-of-the-art level.