 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaojie Tang
Shall We Talk: Exploring Spontaneous Collaborations of Competing LLM Agents
Feb 19, 2024
Recent advancements have shown that agents powered by large language models (LLMs) possess capabilities to simulate human behaviors and societal dynamics. However, the potential for LLM agents to spontaneously establish collaborative relationships in the absence of explicit instructions has not been studied. To address this gap, we conduct three case studies, revealing that LLM agents are capable of spontaneously forming collaborations even within competitive settings. This finding not only demonstrates the capacity of LLM agents to mimic competition and cooperation in human societies but also validates a promising vision of computational social science. Specifically, it suggests that LLM agents could be utilized to model human social interactions, including those with spontaneous collaborations, thus offering insights into social phenomena. The source codes for this study are available at https://github.com/wuzengqing001225/SABM_ShallWeTalk .
Point cloud-based registration and image fusion between cardiac SPECT MPI and CTA
Feb 10, 2024A method was proposed for the point cloud-based registration and image fusion between cardiac single photon emission computed tomography (SPECT) myocardial perfusion images (MPI) and cardiac computed tomography angiograms (CTA). Firstly, the left ventricle (LV) epicardial regions (LVERs) in SPECT and CTA images were segmented by using different U-Net neural networks trained to generate the point clouds of the LV epicardial contours (LVECs). Secondly, according to the characteristics of cardiac anatomy, the special points of anterior and posterior interventricular grooves (APIGs) were manually marked in both SPECT and CTA image volumes. Thirdly, we developed an in-house program for coarsely registering the special points of APIGs to ensure a correct cardiac orientation alignment between SPECT and CTA images. Fourthly, we employed ICP, SICP or CPD algorithm to achieve a fine registration for the point clouds (together with the special points of APIGs) of the LV epicardial surfaces (LVERs) in SPECT and CTA images. Finally, the image fusion between SPECT and CTA was realized after the fine registration. The experimental results showed that the cardiac orientation was aligned well and the mean distance error of the optimal registration method (CPD with affine transform) was consistently less than 3 mm. The proposed method could effectively fuse the structures from cardiac CTA and SPECT functional images, and demonstrated a potential in assisting in accurate diagnosis of cardiac diseases by combining complementary advantages of the two imaging modalities.
Assortment Planning with Sponsored Products
Feb 09, 2024In the rapidly evolving landscape of retail, assortment planning plays a crucial role in determining the success of a business. With the rise of sponsored products and their increasing prominence in online marketplaces, retailers face new challenges in effectively managing their product assortment in the presence of sponsored products. Remarkably, previous research in assortment planning largely overlooks the existence of sponsored products and their potential impact on overall recommendation effectiveness. Instead, they commonly make the simplifying assumption that all products are either organic or non-sponsored. This research gap underscores the necessity for a more thorough investigation of the assortment planning challenge when sponsored products are in play. We formulate the assortment planning problem in the presence of sponsored products as a combinatorial optimization task. The ultimate objective is to compute an assortment plan that optimizes expected revenue while considering the specific requirements of placing sponsored products strategically.
Efficient Generalized Low-Rank Tensor Contextual Bandits
Nov 09, 2023In this paper, we aim to build a novel bandits algorithm that is capable of fully harnessing the power of multi-dimensional data and the inherent non-linearity of reward functions to provide high-usable and accountable decision-making services. To this end, we introduce a generalized low-rank tensor contextual bandits model in which an action is formed from three feature vectors, and thus can be represented by a tensor. In this formulation, the reward is determined through a generalized linear function applied to the inner product of the action's feature tensor and a fixed but unknown parameter tensor with a low tubal rank. To effectively achieve the trade-off between exploration and exploitation, we introduce a novel algorithm called "Generalized Low-Rank Tensor Exploration Subspace then Refine" (G-LowTESTR). This algorithm first collects raw data to explore the intrinsic low-rank tensor subspace information embedded in the decision-making scenario, and then converts the original problem into an almost lower-dimensional generalized linear contextual bandits problem. Rigorous theoretical analysis shows that the regret bound of G-LowTESTR is superior to those in vectorization and matricization cases. We conduct a series of simulations and real data experiments to further highlight the effectiveness of G-LowTESTR, leveraging its ability to capitalize on the low-rank tensor structure for enhanced learning.
Lifting the Veil: Unlocking the Power of Depth in Q-learning
Oct 27, 2023With the help of massive data and rich computational resources, deep Q-learning has been widely used in operations research and management science and has contributed to great success in numerous applications, including recommender systems, supply chains, games, and robotic manipulation. However, the success of deep Q-learning lacks solid theoretical verification and interpretability. The aim of this paper is to theoretically verify the power of depth in deep Q-learning. Within the framework of statistical learning theory, we rigorously prove that deep Q-learning outperforms its traditional version by demonstrating its good generalization error bound. Our results reveal that the main reason for the success of deep Q-learning is the excellent performance of deep neural networks (deep nets) in capturing the special properties of rewards namely, spatial sparseness and piecewise constancy, rather than their large capacities. In this paper, we make fundamental contributions to the field of reinforcement learning by answering to the following three questions: Why does deep Q-learning perform so well? When does deep Q-learning perform better than traditional Q-learning? How many samples are required to achieve a specific prediction accuracy for deep Q-learning? Our theoretical assertions are verified by applying deep Q-learning in the well-known beer game in supply chain management and a simulated recommender system.
Provable Tensor Completion with Graph Information
Oct 04, 2023Graphs, depicting the interrelations between variables, has been widely used as effective side information for accurate data recovery in various matrix/tensor recovery related applications. In this paper, we study the tensor completion problem with graph information. Current research on graph-regularized tensor completion tends to be task-specific, lacking generality and systematic approaches. Furthermore, a recovery theory to ensure performance remains absent. Moreover, these approaches overlook the dynamic aspects of graphs, treating them as static akin to matrices, even though graphs could exhibit dynamism in tensor-related scenarios. To confront these challenges, we introduce a pioneering framework in this paper that systematically formulates a novel model, theory, and algorithm for solving the dynamic graph regularized tensor completion problem. For the model, we establish a rigorous mathematical representation of the dynamic graph, based on which we derive a new tensor-oriented graph smoothness regularization. By integrating this regularization into a tensor decomposition model based on transformed t-SVD, we develop a comprehensive model simultaneously capturing the low-rank and similarity structure of the tensor. In terms of theory, we showcase the alignment between the proposed graph smoothness regularization and a weighted tensor nuclear norm. Subsequently, we establish assurances of statistical consistency for our model, effectively bridging a gap in the theoretical examination of the problem involving tensor recovery with graph information. In terms of the algorithm, we develop a solution of high effectiveness, accompanied by a guaranteed convergence, to address the resulting model. To showcase the prowess of our proposed model in contrast to established ones, we provide in-depth numerical experiments encompassing synthetic data as well as real-world datasets.
Bold but Cautious: Unlocking the Potential of Personalized Federated Learning through Cautiously Aggressive Collaboration
Sep 20, 2023

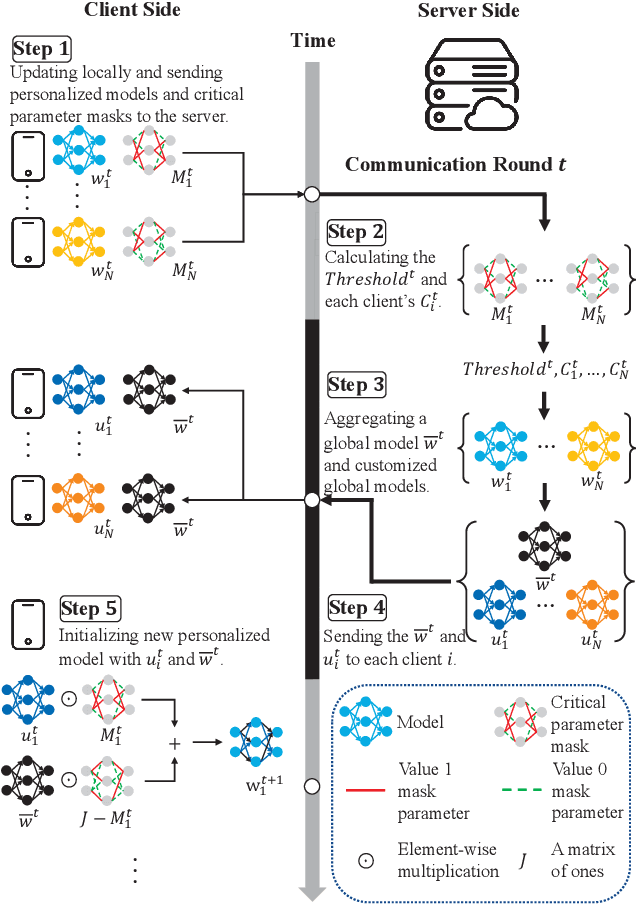
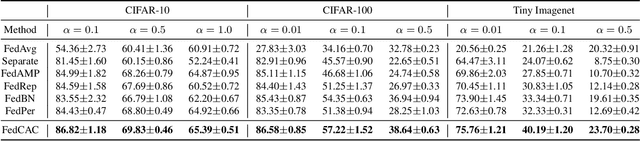
Personalized federated learning (PFL) reduces the impact of non-independent and identically distributed (non-IID) data among clients by allowing each client to train a personalized model when collaborating with others. A key question in PFL is to decide which parameters of a client should be localized or shared with others. In current mainstream approaches, all layers that are sensitive to non-IID data (such as classifier layers) are generally personalized. The reasoning behind this approach is understandable, as localizing parameters that are easily influenced by non-IID data can prevent the potential negative effect of collaboration. However, we believe that this approach is too conservative for collaboration. For example, for a certain client, even if its parameters are easily influenced by non-IID data, it can still benefit by sharing these parameters with clients having similar data distribution. This observation emphasizes the importance of considering not only the sensitivity to non-IID data but also the similarity of data distribution when determining which parameters should be localized in PFL. This paper introduces a novel guideline for client collaboration in PFL. Unlike existing approaches that prohibit all collaboration of sensitive parameters, our guideline allows clients to share more parameters with others, leading to improved model performance. Additionally, we propose a new PFL method named FedCAC, which employs a quantitative metric to evaluate each parameter's sensitivity to non-IID data and carefully selects collaborators based on this evaluation. Experimental results demonstrate that FedCAC enables clients to share more parameters with others, resulting in superior performance compared to state-of-the-art methods, particularly in scenarios where clients have diverse distributions.
Data Summarization beyond Monotonicity: Non-monotone Two-Stage Submodular Maximization
Sep 11, 2023The objective of a two-stage submodular maximization problem is to reduce the ground set using provided training functions that are submodular, with the aim of ensuring that optimizing new objective functions over the reduced ground set yields results comparable to those obtained over the original ground set. This problem has applications in various domains including data summarization. Existing studies often assume the monotonicity of the objective function, whereas our work pioneers the extension of this research to accommodate non-monotone submodular functions. We have introduced the first constant-factor approximation algorithms for this more general case.
Non-monotone Sequential Submodular Maximization
Aug 16, 2023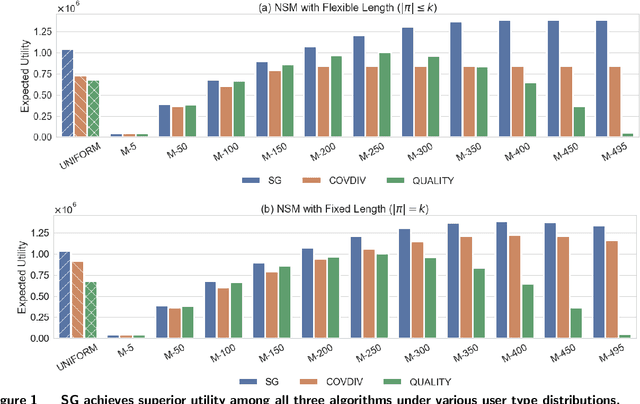
In this paper, we study a fundamental problem in submodular optimization, which is called sequential submodular maximization. Specifically, we aim to select and rank a group of $k$ items from a ground set $V$ such that the weighted summation of $k$ (possibly non-monotone) submodular functions $f_1, \cdots ,f_k: 2^V \rightarrow \mathbb{R}^+$ is maximized, here each function $f_j$ takes the first $j$ items from this sequence as input. The existing research on sequential submodular maximization has predominantly concentrated on the monotone setting, assuming that the submodular functions are non-decreasing. However, in various real-world scenarios, like diversity-aware recommendation systems, adding items to an existing set might negatively impact the overall utility. In response, this paper pioneers the examination of the aforementioned problem with non-monotone submodular functions and offers effective solutions for both flexible and fixed length constraints, as well as a special case with identical utility functions. The empirical evaluations further validate the effectiveness of our proposed algorithms in the domain of video recommendations. The results of this research have implications in various fields, including recommendation systems and assortment optimization, where the ordering of items significantly impacts the overall value obtained.
Take Your Pick: Enabling Effective Personalized Federated Learning within Low-dimensional Feature Space
Jul 26, 2023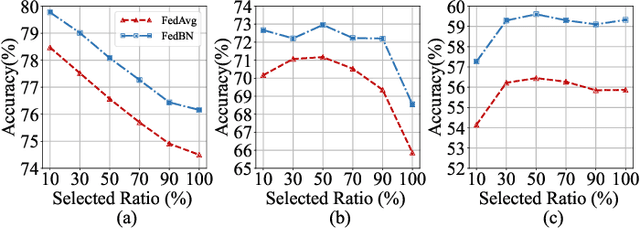


Personalized federated learning (PFL) is a popular framework that allows clients to have different models to address application scenarios where clients' data are in different domains. The typical model of a client in PFL features a global encoder trained by all clients to extract universal features from the raw data and personalized layers (e.g., a classifier) trained using the client's local data. Nonetheless, due to the differences between the data distributions of different clients (aka, domain gaps), the universal features produced by the global encoder largely encompass numerous components irrelevant to a certain client's local task. Some recent PFL methods address the above problem by personalizing specific parameters within the encoder. However, these methods encounter substantial challenges attributed to the high dimensionality and non-linearity of neural network parameter space. In contrast, the feature space exhibits a lower dimensionality, providing greater intuitiveness and interpretability as compared to the parameter space. To this end, we propose a novel PFL framework named FedPick. FedPick achieves PFL in the low-dimensional feature space by selecting task-relevant features adaptively for each client from the features generated by the global encoder based on its local data distribution. It presents a more accessible and interpretable implementation of PFL compared to those methods working in the parameter space. Extensive experimental results show that FedPick could effectively select task-relevant features for each client and improve model performance in cross-domain FL.