 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZijia Lin
Evaluating Concept-based Explanations of Language Models: A Study on Faithfulness and Readability
Apr 30, 2024
Despite the surprisingly high intelligence exhibited by Large Language Models (LLMs), we are somehow intimidated to fully deploy them into real-life applications considering their black-box nature. Concept-based explanations arise as a promising avenue for explaining what the LLMs have learned, making them more transparent to humans. However, current evaluations for concepts tend to be heuristic and non-deterministic, e.g. case study or human evaluation, hindering the development of the field. To bridge the gap, we approach concept-based explanation evaluation via faithfulness and readability. We first introduce a formal definition of concept generalizable to diverse concept-based explanations. Based on this, we quantify faithfulness via the difference in the output upon perturbation. We then provide an automatic measure for readability, by measuring the coherence of patterns that maximally activate a concept. This measure serves as a cost-effective and reliable substitute for human evaluation. Finally, based on measurement theory, we describe a meta-evaluation method for evaluating the above measures via reliability and validity, which can be generalized to other tasks as well. Extensive experimental analysis has been conducted to validate and inform the selection of concept evaluation measures.
Temporal Scaling Law for Large Language Models
Apr 27, 2024Recently, Large Language Models (LLMs) are widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed as Scaling Laws, have discovered that the loss of LLMs scales as power laws with model size, computational budget, and dataset size. However, the performance of LLMs throughout the training process remains untouched. In this paper, we propose the novel concept of Temporal Scaling Law and study the loss of LLMs from the temporal dimension. We first investigate the imbalance of loss on each token positions and develop a reciprocal-law across model scales and training stages. We then derive the temporal scaling law by studying the temporal patterns of the reciprocal-law parameters. Results on both in-distribution (IID) data and out-of-distribution (OOD) data demonstrate that our temporal scaling law accurately predicts the performance of LLMs in future training stages. Moreover, the temporal scaling law reveals that LLMs learn uniformly on different token positions, despite the loss imbalance. Experiments on pre-training LLMs in various scales show that this phenomenon verifies the default training paradigm for generative language models, in which no re-weighting strategies are attached during training. Overall, the temporal scaling law provides deeper insight into LLM pre-training.
Scaffold-BPE: Enhancing Byte Pair Encoding with Simple and Effective Scaffold Token Removal
Apr 27, 2024Byte Pair Encoding (BPE) serves as a foundation method for text tokenization in the Natural Language Processing (NLP) field. Despite its wide adoption, the original BPE algorithm harbors an inherent flaw: it inadvertently introduces a frequency imbalance for tokens in the text corpus. Since BPE iteratively merges the most frequent token pair in the text corpus while keeping all tokens that have been merged in the vocabulary, it unavoidably holds tokens that primarily represent subwords of complete words and appear infrequently on their own in the text corpus. We term such tokens as Scaffold Tokens. Due to their infrequent appearance in the text corpus, Scaffold Tokens pose a learning imbalance issue for language models. To address that issue, we propose Scaffold-BPE, which incorporates a dynamic scaffold token removal mechanism by parameter-free, computation-light, and easy-to-implement modifications to the original BPE. This novel approach ensures the exclusion of low-frequency Scaffold Tokens from the token representations for the given texts, thereby mitigating the issue of frequency imbalance and facilitating model training. On extensive experiments across language modeling tasks and machine translation tasks, Scaffold-BPE consistently outperforms the original BPE, well demonstrating its effectiveness and superiority.
PYRA: Parallel Yielding Re-Activation for Training-Inference Efficient Task Adaptation
Mar 14, 2024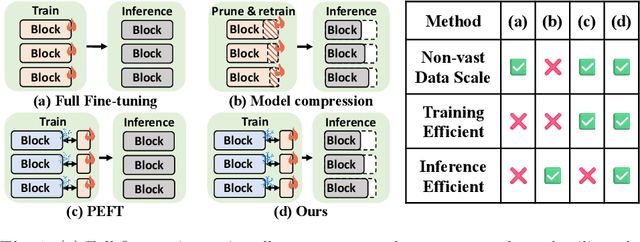
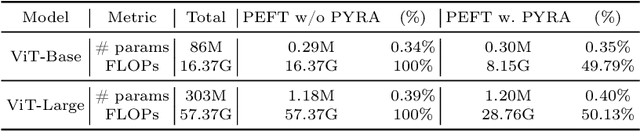
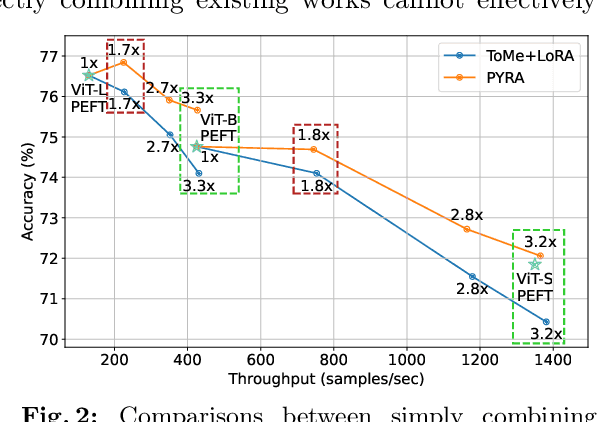
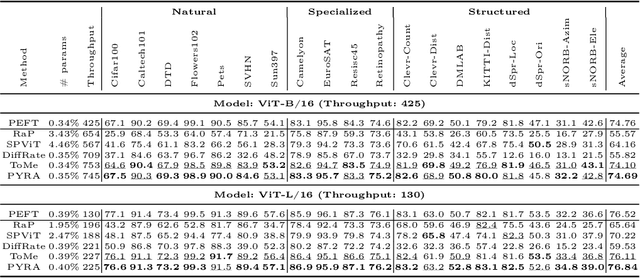
Recently, the scale of transformers has grown rapidly, which introduces considerable challenges in terms of training overhead and inference efficiency in the scope of task adaptation. Existing works, namely Parameter-Efficient Fine-Tuning (PEFT) and model compression, have separately investigated the challenges. However, PEFT cannot guarantee the inference efficiency of the original backbone, especially for large-scale models. Model compression requires significant training costs for structure searching and re-training. Consequently, a simple combination of them cannot guarantee accomplishing both training efficiency and inference efficiency with minimal costs. In this paper, we propose a novel Parallel Yielding Re-Activation (PYRA) method for such a challenge of training-inference efficient task adaptation. PYRA first utilizes parallel yielding adaptive weights to comprehensively perceive the data distribution in downstream tasks. A re-activation strategy for token modulation is then applied for tokens to be merged, leading to calibrated token features. Extensive experiments demonstrate that PYRA outperforms all competing methods under both low compression rate and high compression rate, demonstrating its effectiveness and superiority in maintaining both training efficiency and inference efficiency for large-scale foundation models. Our code will be released to the public.
Drop your Decoder: Pre-training with Bag-of-Word Prediction for Dense Passage Retrieval
Jan 20, 2024Masked auto-encoder pre-training has emerged as a prevalent technique for initializing and enhancing dense retrieval systems. It generally utilizes additional Transformer decoder blocks to provide sustainable supervision signals and compress contextual information into dense representations. However, the underlying reasons for the effectiveness of such a pre-training technique remain unclear. The usage of additional Transformer-based decoders also incurs significant computational costs. In this study, we aim to shed light on this issue by revealing that masked auto-encoder (MAE) pre-training with enhanced decoding significantly improves the term coverage of input tokens in dense representations, compared to vanilla BERT checkpoints. Building upon this observation, we propose a modification to the traditional MAE by replacing the decoder of a masked auto-encoder with a completely simplified Bag-of-Word prediction task. This modification enables the efficient compression of lexical signals into dense representations through unsupervised pre-training. Remarkably, our proposed method achieves state-of-the-art retrieval performance on several large-scale retrieval benchmarks without requiring any additional parameters, which provides a 67% training speed-up compared to standard masked auto-encoder pre-training with enhanced decoding.
RepViT-SAM: Towards Real-Time Segmenting Anything
Dec 10, 2023Segment Anything Model (SAM) has shown impressive zero-shot transfer performance for various computer vision tasks recently. However, its heavy computation costs remain daunting for practical applications. MobileSAM proposes to replace the heavyweight image encoder in SAM with TinyViT by employing distillation, which results in a significant reduction in computational requirements. However, its deployment on resource-constrained mobile devices still encounters challenges due to the substantial memory and computational overhead caused by self-attention mechanisms. Recently, RepViT achieves the state-of-the-art performance and latency trade-off on mobile devices by incorporating efficient architectural designs of ViTs into CNNs. Here, to achieve real-time segmenting anything on mobile devices, following MobileSAM, we replace the heavyweight image encoder in SAM with RepViT model, ending up with the RepViT-SAM model. Extensive experiments show that RepViT-SAM can enjoy significantly better zero-shot transfer capability than MobileSAM, along with nearly $10\times$ faster inference speed. The code and models are available at \url{https://github.com/THU-MIG/RepViT}.
InfoEntropy Loss to Mitigate Bias of Learning Difficulties for Generative Language Models
Nov 01, 2023



Generative language models are usually pretrained on large text corpus via predicting the next token (i.e., sub-word/word/phrase) given the previous ones. Recent works have demonstrated the impressive performance of large generative language models on downstream tasks. However, existing generative language models generally neglect an inherent challenge in text corpus during training, i.e., the imbalance between frequent tokens and infrequent ones. It can lead a language model to be dominated by common and easy-to-learn tokens, thereby overlooking the infrequent and difficult-to-learn ones. To alleviate that, we propose an Information Entropy Loss (InfoEntropy Loss) function. During training, it can dynamically assess the learning difficulty of a to-be-learned token, according to the information entropy of the corresponding predicted probability distribution over the vocabulary. Then it scales the training loss adaptively, trying to lead the model to focus more on the difficult-to-learn tokens. On the Pile dataset, we train generative language models at different scales of 436M, 1.1B, and 6.7B parameters. Experiments reveal that models incorporating the proposed InfoEntropy Loss can gain consistent performance improvement on downstream benchmarks.
KwaiYiiMath: Technical Report
Oct 19, 2023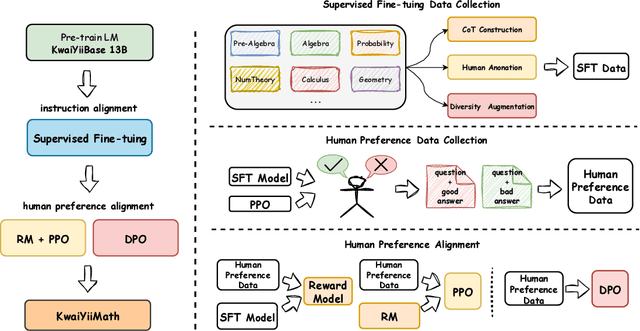
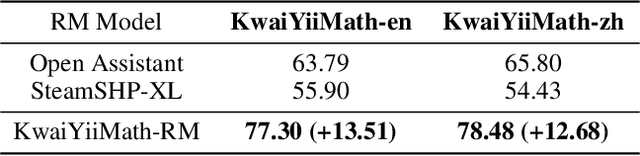
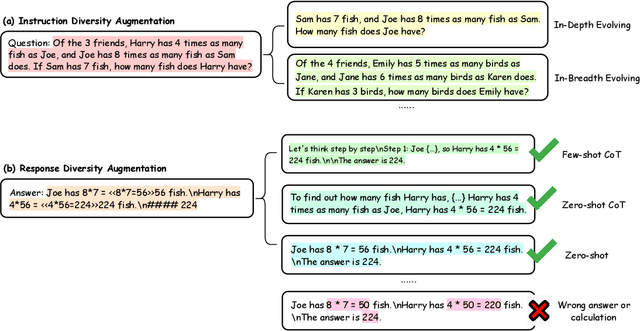
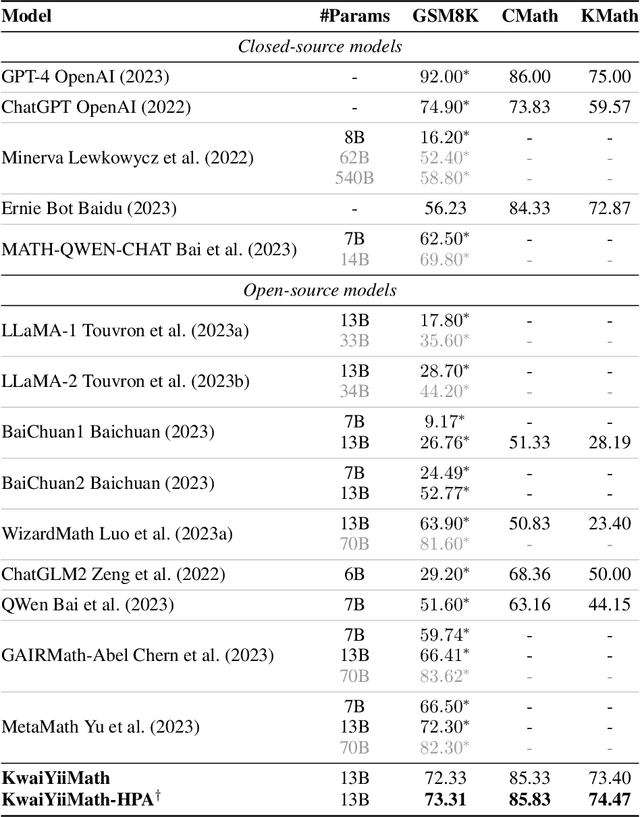
Recent advancements in large language models (LLMs) have demonstrated remarkable abilities in handling a variety of natural language processing (NLP) downstream tasks, even on mathematical tasks requiring multi-step reasoning. In this report, we introduce the KwaiYiiMath which enhances the mathematical reasoning abilities of KwaiYiiBase1, by applying Supervised Fine-Tuning (SFT) and Reinforced Learning from Human Feedback (RLHF), including on both English and Chinese mathematical tasks. Meanwhile, we also constructed a small-scale Chinese primary school mathematics test set (named KMath), consisting of 188 examples to evaluate the correctness of the problem-solving process generated by the models. Empirical studies demonstrate that KwaiYiiMath can achieve state-of-the-art (SOTA) performance on GSM8k, CMath, and KMath compared with the similar size models, respectively.
Confidence-based Visual Dispersal for Few-shot Unsupervised Domain Adaptation
Sep 29, 2023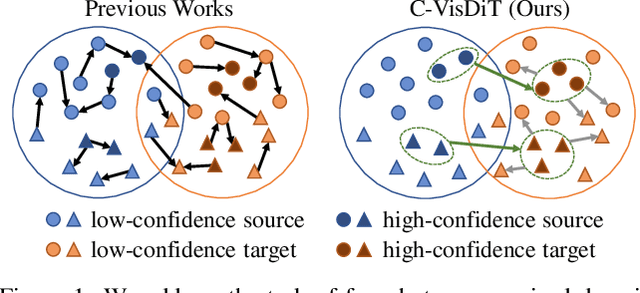
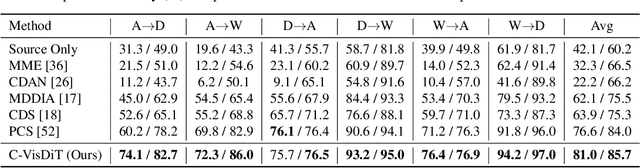
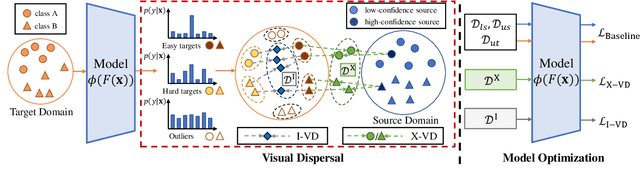
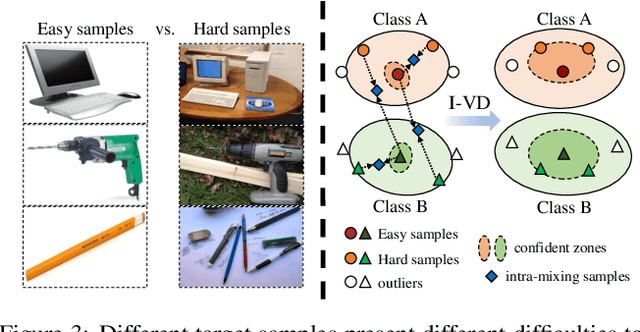
Unsupervised domain adaptation aims to transfer knowledge from a fully-labeled source domain to an unlabeled target domain. However, in real-world scenarios, providing abundant labeled data even in the source domain can be infeasible due to the difficulty and high expense of annotation. To address this issue, recent works consider the Few-shot Unsupervised Domain Adaptation (FUDA) where only a few source samples are labeled, and conduct knowledge transfer via self-supervised learning methods. Yet existing methods generally overlook that the sparse label setting hinders learning reliable source knowledge for transfer. Additionally, the learning difficulty difference in target samples is different but ignored, leaving hard target samples poorly classified. To tackle both deficiencies, in this paper, we propose a novel Confidence-based Visual Dispersal Transfer learning method (C-VisDiT) for FUDA. Specifically, C-VisDiT consists of a cross-domain visual dispersal strategy that transfers only high-confidence source knowledge for model adaptation and an intra-domain visual dispersal strategy that guides the learning of hard target samples with easy ones. We conduct extensive experiments on Office-31, Office-Home, VisDA-C, and DomainNet benchmark datasets and the results demonstrate that the proposed C-VisDiT significantly outperforms state-of-the-art FUDA methods. Our code is available at https://github.com/Bostoncake/C-VisDiT.
CAIT: Triple-Win Compression towards High Accuracy, Fast Inference, and Favorable Transferability For ViTs
Sep 27, 2023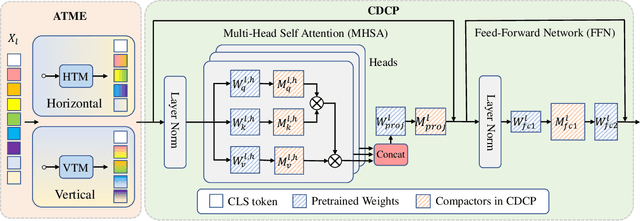

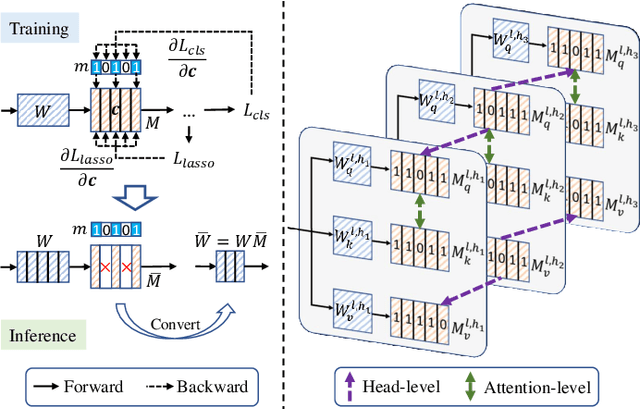
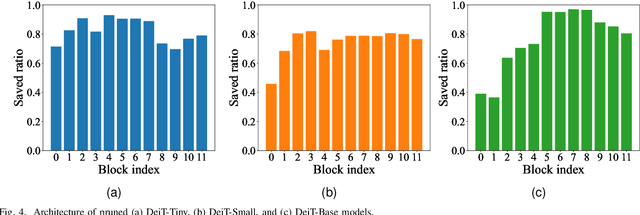
Vision Transformers (ViTs) have emerged as state-of-the-art models for various vision tasks recently. However, their heavy computation costs remain daunting for resource-limited devices. Consequently, researchers have dedicated themselves to compressing redundant information in ViTs for acceleration. However, they generally sparsely drop redundant image tokens by token pruning or brutally remove channels by channel pruning, leading to a sub-optimal balance between model performance and inference speed. They are also disadvantageous in transferring compressed models to downstream vision tasks that require the spatial structure of images, such as semantic segmentation. To tackle these issues, we propose a joint compression method for ViTs that offers both high accuracy and fast inference speed, while also maintaining favorable transferability to downstream tasks (CAIT). Specifically, we introduce an asymmetric token merging (ATME) strategy to effectively integrate neighboring tokens. It can successfully compress redundant token information while preserving the spatial structure of images. We further employ a consistent dynamic channel pruning (CDCP) strategy to dynamically prune unimportant channels in ViTs. Thanks to CDCP, insignificant channels in multi-head self-attention modules of ViTs can be pruned uniformly, greatly enhancing the model compression. Extensive experiments on benchmark datasets demonstrate that our proposed method can achieve state-of-the-art performance across various ViTs. For example, our pruned DeiT-Tiny and DeiT-Small achieve speedups of 1.7$\times$ and 1.9$\times$, respectively, without accuracy drops on ImageNet. On the ADE20k segmentation dataset, our method can enjoy up to 1.31$\times$ speedups with comparable mIoU. Our code will be publicly available.