 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYulin Li
Collision-Free Trajectory Optimization in Cluttered Environments with Sums-of-Squares Programming
Apr 08, 2024
In this work, we propose a trajectory optimization approach for robot navigation in cluttered 3D environments. We represent the robot's geometry as a semialgebraic set defined by polynomial inequalities such that robots with general shapes can be suitably characterized. To address the robot navigation task in obstacle-dense environments, we exploit the free space directly to construct a sequence of free regions, and allocate each waypoint on the trajectory to a specific region. Then, we incorporate a uniform scaling factor for each free region, and formulate a Sums-of-Squares (SOS) optimization problem that renders the containment relationship between the robot and the free space computationally tractable. The SOS optimization problem is further reformulated to a semidefinite program (SDP), and the collision-free constraints are shown to be equivalent to limiting the scaling factor along the entire trajectory. In this context, the robot at a specific configuration is tailored to stay within the free region. Next, to solve the trajectory optimization problem with the proposed safety constraints (which are implicitly dependent on the robot configurations), we derive the analytical solution to the gradient of the minimum scaling factor with respect to the robot configuration. As a result, this seamlessly facilitates the use of gradient-based methods in efficient solving of the trajectory optimization problem. Through a series of simulations and real-world experiments, the proposed trajectory optimization approach is validated in various challenging scenarios, and the results demonstrate its effectiveness in generating collision-free trajectories in dense and intricate environments populated with obstacles.
Robot Navigation in Unknown and Cluttered Workspace with Dynamical System Modulation in Starshaped Roadmap
Mar 18, 2024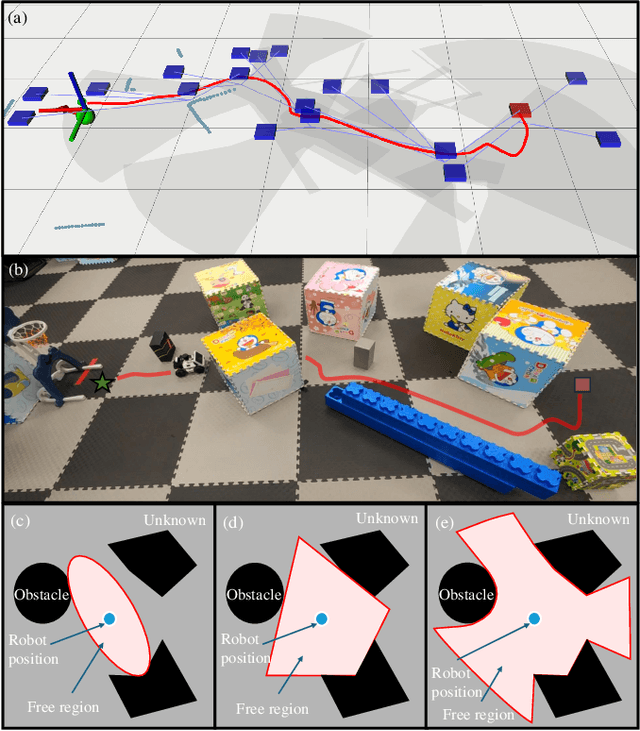
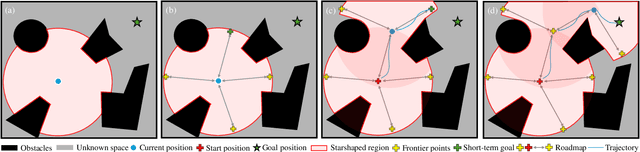
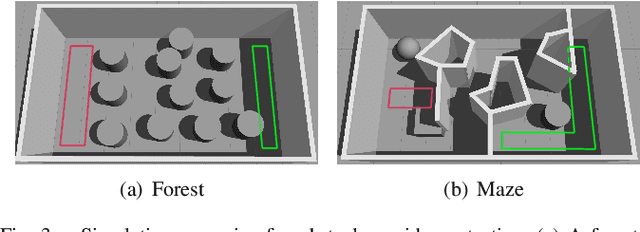
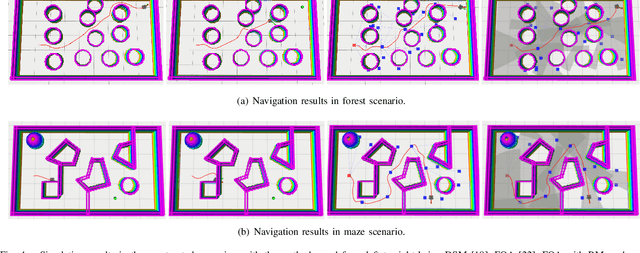
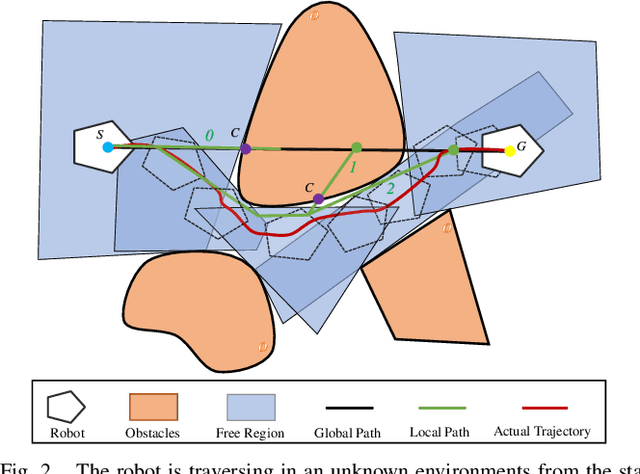
This paper presents a novel reactive motion planning framework for navigating robots in unknown and cluttered 2D workspace. Typical existing methods are developed by enforcing the robot staying in free regions represented by the locally extracted ellipse or polygon. Instead, we navigate the robot in free space with an alternate starshaped decomposition, which is calculated directly from real-time sensor data. Additionally, a roadmap is constructed incrementally to maintain the connectivity information of the starshaped regions. Compared to the roadmap built upon connected polygons or ellipses in the conventional approaches, the concave starshaped region is better suited to capture the natural distribution of sensor data, so that the perception information can be fully exploited for robot navigation. In this sense, conservative and myopic behaviors are avoided with the proposed approach, and intricate obstacle configurations can be suitably accommodated in unknown and cluttered environments. Then, we design a heuristic exploration algorithm on the roadmap to determine the frontier points of the starshaped regions, from which short-term goals are selected to attract the robot towards the goal configuration. It is noteworthy that, a recovery mechanism is developed on the roadmap that is triggered once a non-extendable short-term goal is reached. This mechanism renders it possible to deal with dead-end situations that can be typically encountered in unknown and cluttered environments. Furthermore, safe and smooth motion within the starshaped regions is generated by employing the Dynamical System Modulation (DSM) approach on the constructed roadmap. Through comprehensive evaluation in both simulations and real-world experiments, the proposed method outperforms the benchmark methods in terms of success rate and traveling time.
Collaborative Position Reasoning Network for Referring Image Segmentation
Jan 22, 2024Given an image and a natural language expression as input, the goal of referring image segmentation is to segment the foreground masks of the entities referred by the expression. Existing methods mainly focus on interactive learning between vision and language to enhance the multi-modal representations for global context reasoning. However, predicting directly in pixel-level space can lead to collapsed positioning and poor segmentation results. Its main challenge lies in how to explicitly model entity localization, especially for non-salient entities. In this paper, we tackle this problem by executing a Collaborative Position Reasoning Network (CPRN) via the proposed novel Row-and-Column interactive (RoCo) and Guided Holistic interactive (Holi) modules. Specifically, RoCo aggregates the visual features into the row- and column-wise features corresponding two directional axes respectively. It offers a fine-grained matching behavior that perceives the associations between the linguistic features and two decoupled visual features to perform position reasoning over a hierarchical space. Holi integrates features of the two modalities by a cross-modal attention mechanism, which suppresses the irrelevant redundancy under the guide of positioning information from RoCo. Thus, with the incorporation of RoCo and Holi modules, CPRN captures the visual details of position reasoning so that the model can achieve more accurate segmentation. To our knowledge, this is the first work that explicitly focuses on position reasoning modeling. We also validate the proposed method on three evaluation datasets. It consistently outperforms existing state-of-the-art methods.
Improved Consensus ADMM for Cooperative Motion Planning of Large-Scale Connected Autonomous Vehicles with Limited Communication
Jan 17, 2024This paper investigates a cooperative motion planning problem for large-scale connected autonomous vehicles (CAVs) under limited communications, which addresses the challenges of high communication and computing resource requirements. Our proposed methodology incorporates a parallel optimization algorithm with improved consensus ADMM considering a more realistic locally connected topology network, and time complexity of O(N) is achieved by exploiting the sparsity in the dual update process. To further enhance the computational efficiency, we employ a lightweight evolution strategy for the dynamic connectivity graph of CAVs, and each sub-problem split from the consensus ADMM only requires managing a small group of CAVs. The proposed method implemented with the receding horizon scheme is validated thoroughly, and comparisons with existing numerical solvers and approaches demonstrate the efficiency of our proposed algorithm. Also, simulations on large-scale cooperative driving tasks involving 80 vehicles are performed in the high-fidelity CARLA simulator, which highlights the remarkable computational efficiency, scalability, and effectiveness of our proposed development. Demonstration videos are available at https://henryhcliu.github.io/icadmm_cmp_carla.
Frequency Domain Modality-invariant Feature Learning for Visible-infrared Person Re-Identification
Jan 04, 2024Visible-infrared person re-identification (VI-ReID) is challenging due to the significant cross-modality discrepancies between visible and infrared images. While existing methods have focused on designing complex network architectures or using metric learning constraints to learn modality-invariant features, they often overlook which specific component of the image causes the modality discrepancy problem. In this paper, we first reveal that the difference in the amplitude component of visible and infrared images is the primary factor that causes the modality discrepancy and further propose a novel Frequency Domain modality-invariant feature learning framework (FDMNet) to reduce modality discrepancy from the frequency domain perspective. Our framework introduces two novel modules, namely the Instance-Adaptive Amplitude Filter (IAF) module and the Phrase-Preserving Normalization (PPNorm) module, to enhance the modality-invariant amplitude component and suppress the modality-specific component at both the image- and feature-levels. Extensive experimental results on two standard benchmarks, SYSU-MM01 and RegDB, demonstrate the superior performance of our FDMNet against state-of-the-art methods.
Geometry-Aware Safety-Critical Local Reactive Controller for Robot Navigation in Unknown and Cluttered Environments
Oct 09, 2023

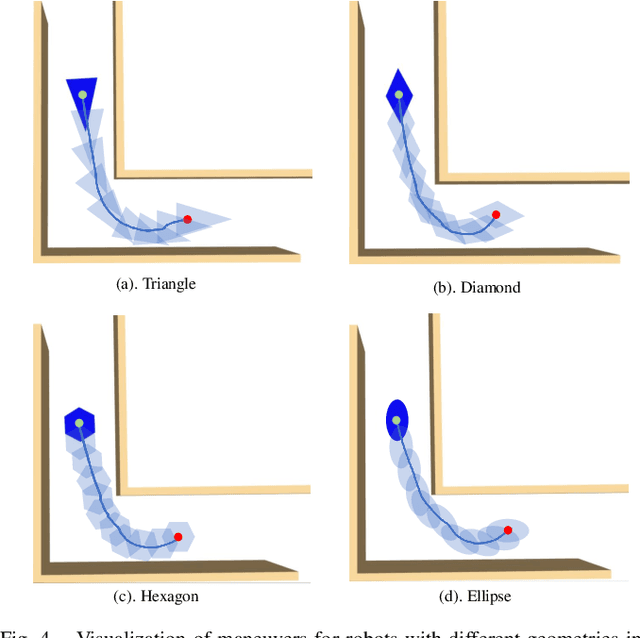
This work proposes a safety-critical local reactive controller that enables the robot to navigate in unknown and cluttered environments. In particular, the trajectory tracking task is formulated as a constrained polynomial optimization problem. Then, safety constraints are imposed on the control variables invoking the notion of polynomial positivity certificates in conjunction with their Sum-of-Squares (SOS) approximation, thereby confining the robot motion inside the locally extracted convex free region. It is noteworthy that, in the process of devising the proposed safety constraints, the geometry of the robot can be approximated using any shape that can be characterized with a set of polynomial functions. The optimization problem is further convexified into a semidefinite program (SDP) leveraging truncated multi-sequences (tms) and moment relaxation, which favorably facilitates the effective use of off-the-shelf conic programming solvers, such that real-time performance is attainable. Various robot navigation tasks are investigated to demonstrate the effectiveness of the proposed approach in terms of safety and tracking performance.
MataDoc: Margin and Text Aware Document Dewarping for Arbitrary Boundary
Jul 24, 2023


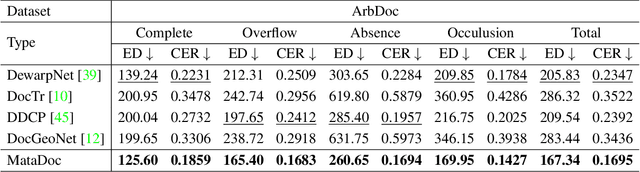
Document dewarping from a distorted camera-captured image is of great value for OCR and document understanding. The document boundary plays an important role which is more evident than the inner region in document dewarping. Current learning-based methods mainly focus on complete boundary cases, leading to poor document correction performance of documents with incomplete boundaries. In contrast to these methods, this paper proposes MataDoc, the first method focusing on arbitrary boundary document dewarping with margin and text aware regularizations. Specifically, we design the margin regularization by explicitly considering background consistency to enhance boundary perception. Moreover, we introduce word position consistency to keep text lines straight in rectified document images. To produce a comprehensive evaluation of MataDoc, we propose a novel benchmark ArbDoc, mainly consisting of document images with arbitrary boundaries in four typical scenarios. Extensive experiments confirm the superiority of MataDoc with consideration for the incomplete boundary on ArbDoc and also demonstrate the effectiveness of the proposed method on DocUNet, DIR300, and WarpDoc datasets.
Fast-StrucTexT: An Efficient Hourglass Transformer with Modality-guided Dynamic Token Merge for Document Understanding
May 19, 2023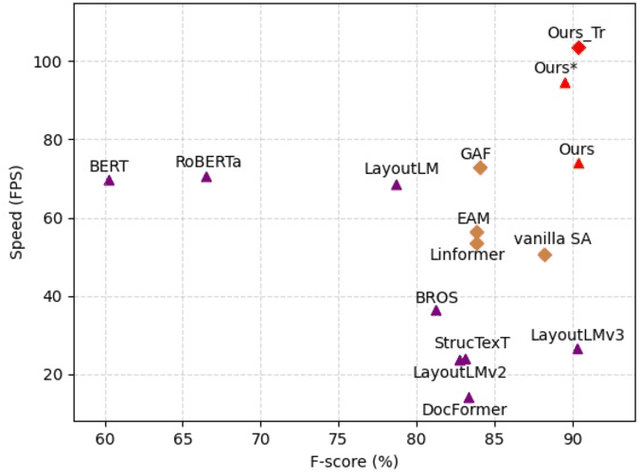
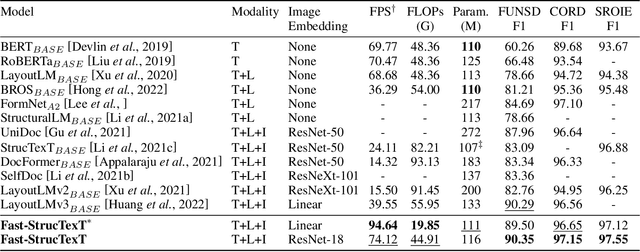
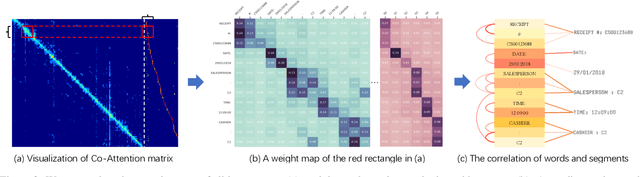

Transformers achieve promising performance in document understanding because of their high effectiveness and still suffer from quadratic computational complexity dependency on the sequence length. General efficient transformers are challenging to be directly adapted to model document. They are unable to handle the layout representation in documents, e.g. word, line and paragraph, on different granularity levels and seem hard to achieve a good trade-off between efficiency and performance. To tackle the concerns, we propose Fast-StrucTexT, an efficient multi-modal framework based on the StrucTexT algorithm with an hourglass transformer architecture, for visual document understanding. Specifically, we design a modality-guided dynamic token merging block to make the model learn multi-granularity representation and prunes redundant tokens. Additionally, we present a multi-modal interaction module called Symmetry Cross Attention (SCA) to consider multi-modal fusion and efficiently guide the token mergence. The SCA allows one modality input as query to calculate cross attention with another modality in a dual phase. Extensive experiments on FUNSD, SROIE, and CORD datasets demonstrate that our model achieves the state-of-the-art performance and almost 1.9X faster inference time than the state-of-the-art methods.
Integrated Decision-Making and Control for Urban Autonomous Driving with Traffic Rules Compliance
Apr 03, 2023

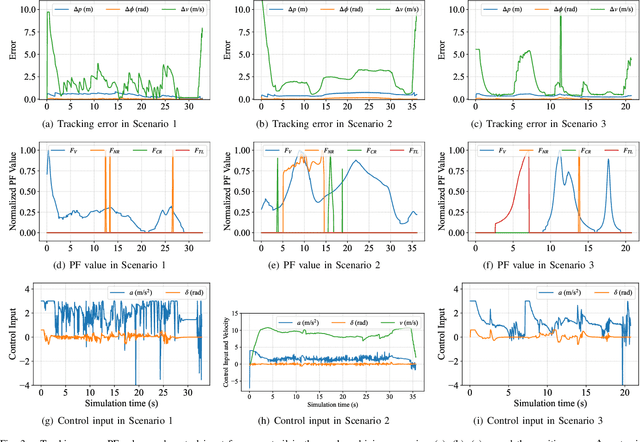
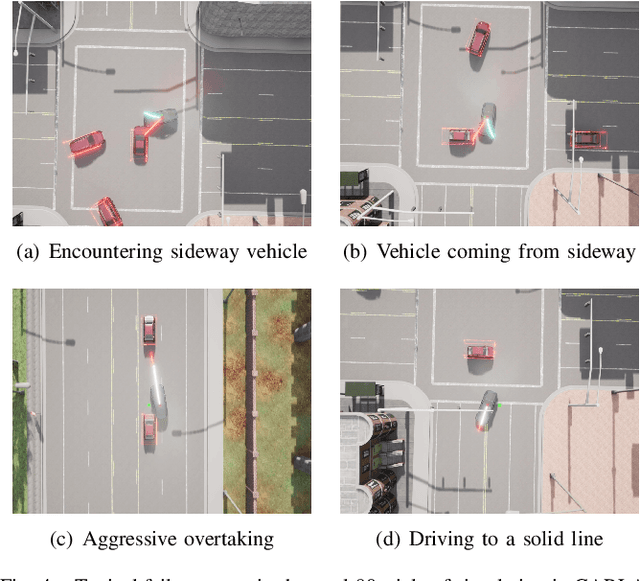
In urban driving scenarios, autonomous vehicles are expected to conform to traffic rules covering traffic lights, traversable and non-traversable traffic lines, etc. In this article, we propose an optimization-based integrated decision-making and control scheme for urban autonomous driving. Inherently, to ensure the compliance with traffic rules, an innovative design of potential functions (PFs) is presented to characterize various traffic rules that are commonly encountered in urban driving scenarios, and these PFs are further incorporated as part of the model predictive control (MPC) formulation. In this sense, it circumvents the necessity of typical hand-crafted rule design, and high-level decision-making is attained implicitly along with control as an integrated architecture, facilitating flexible maneuvers with safety guarantees. As demonstrated from a series of simulations in CARLA, it is noteworthy that the proposed framework admits real-time performance and high generalizability.
Chance-Aware Lane Change with High-Level Model Predictive Control Through Curriculum Reinforcement Learning
Mar 07, 2023
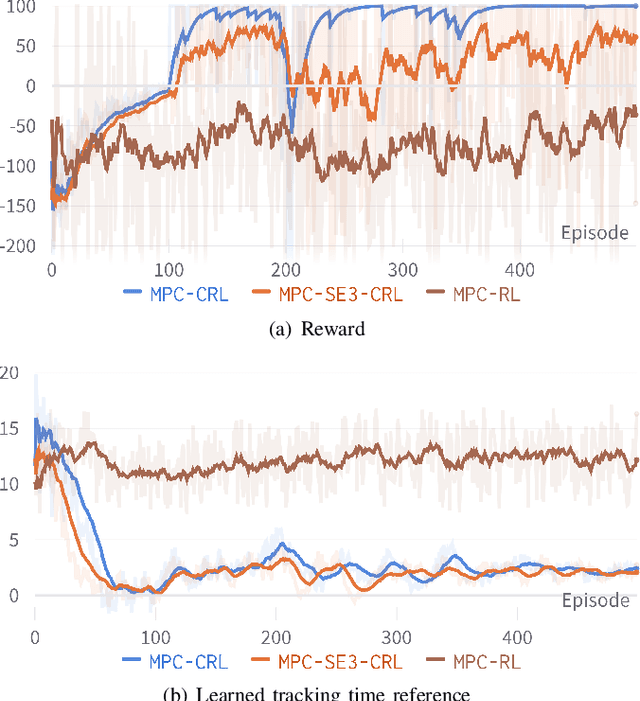
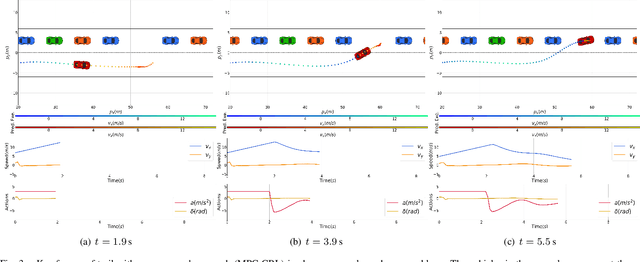

Lane change in dense traffic is considered a challenging problem that typically requires the recognization of an opportune and appropriate time for maneuvers. In this work, we propose a chance-aware lane-change strategy with high-level model predictive control (MPC) through curriculum reinforcement learning (CRL). The embodied high-level MPC in our proposed framework is parameterized with augmented decision variables, where full-state references and regulatory factors concerning their importance are introduced. In this sense, improved adaptiveness to dense and dynamic environments with high complexity is exhibited. Furthermore, to improve the convergence speed and ensure a high-quality policy, effective curriculum design is integrated into the reinforcement learning (RL) framework with policy transfer and enhancement. With comprehensive experiments towards the chance-aware lane-change scenario, accelerated convergence speed and improved reward performance are demonstrated through comparisons with representative baseline methods. It is noteworthy that, given a narrow chance in the dense and dynamic traffic flow, the proposed approach generates high-quality lane-change maneuvers such that the vehicle merges into the traffic flow with a high success rate.