 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunde Jia
Fine-Grained Annotation for Face Anti-Spoofing
Oct 12, 2023




Face anti-spoofing plays a critical role in safeguarding facial recognition systems against presentation attacks. While existing deep learning methods show promising results, they still suffer from the lack of fine-grained annotations, which lead models to learn task-irrelevant or unfaithful features. In this paper, we propose a fine-grained annotation method for face anti-spoofing. Specifically, we first leverage the Segment Anything Model (SAM) to obtain pixel-wise segmentation masks by utilizing face landmarks as point prompts. The face landmarks provide segmentation semantics, which segments the face into regions. We then adopt these regions as masks and assemble them into three separate annotation maps: spoof, living, and background maps. Finally, we combine three separate maps into a three-channel map as annotations for model training. Furthermore, we introduce the Multi-Channel Region Exchange Augmentation (MCREA) to diversify training data and reduce overfitting. Experimental results demonstrate that our method outperforms existing state-of-the-art approaches in both intra-dataset and cross-dataset evaluations.
Neural 3D Scene Reconstruction from Multiple 2D Images without 3D Supervision
Jul 04, 2023



Neural 3D scene reconstruction methods have achieved impressive performance when reconstructing complex geometry and low-textured regions in indoor scenes. However, these methods heavily rely on 3D data which is costly and time-consuming to obtain in real world. In this paper, we propose a novel neural reconstruction method that reconstructs scenes using sparse depth under the plane constraints without 3D supervision. We introduce a signed distance function field, a color field, and a probability field to represent a scene. We optimize these fields to reconstruct the scene by using differentiable ray marching with accessible 2D images as supervision. We improve the reconstruction quality of complex geometry scene regions with sparse depth obtained by using the geometric constraints. The geometric constraints project 3D points on the surface to similar-looking regions with similar features in different 2D images. We impose the plane constraints to make large planes parallel or vertical to the indoor floor. Both two constraints help reconstruct accurate and smooth geometry structures of the scene. Without 3D supervision, our method achieves competitive performance compared with existing methods that use 3D supervision on the ScanNet dataset.
Fast-StrucTexT: An Efficient Hourglass Transformer with Modality-guided Dynamic Token Merge for Document Understanding
May 19, 2023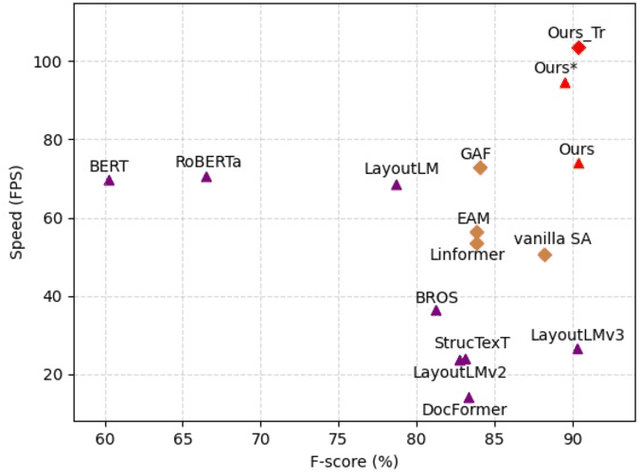
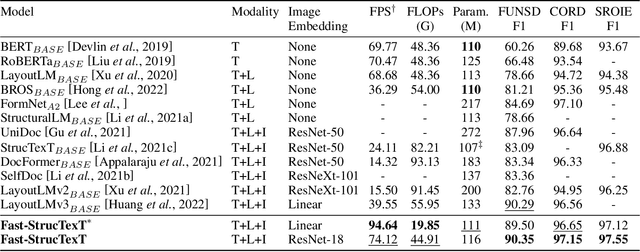
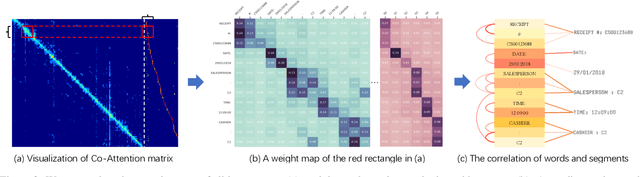

Transformers achieve promising performance in document understanding because of their high effectiveness and still suffer from quadratic computational complexity dependency on the sequence length. General efficient transformers are challenging to be directly adapted to model document. They are unable to handle the layout representation in documents, e.g. word, line and paragraph, on different granularity levels and seem hard to achieve a good trade-off between efficiency and performance. To tackle the concerns, we propose Fast-StrucTexT, an efficient multi-modal framework based on the StrucTexT algorithm with an hourglass transformer architecture, for visual document understanding. Specifically, we design a modality-guided dynamic token merging block to make the model learn multi-granularity representation and prunes redundant tokens. Additionally, we present a multi-modal interaction module called Symmetry Cross Attention (SCA) to consider multi-modal fusion and efficiently guide the token mergence. The SCA allows one modality input as query to calculate cross attention with another modality in a dual phase. Extensive experiments on FUNSD, SROIE, and CORD datasets demonstrate that our model achieves the state-of-the-art performance and almost 1.9X faster inference time than the state-of-the-art methods.
Exploring Data Geometry for Continual Learning
Apr 08, 2023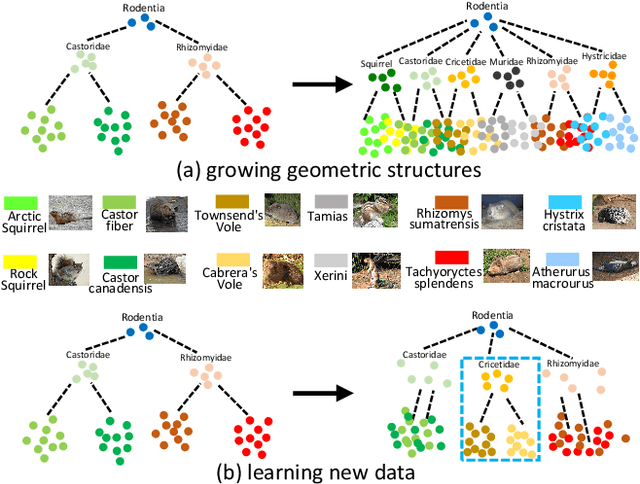
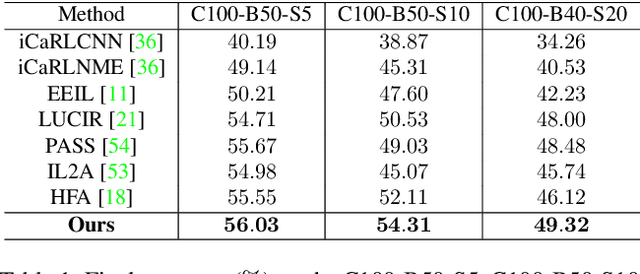
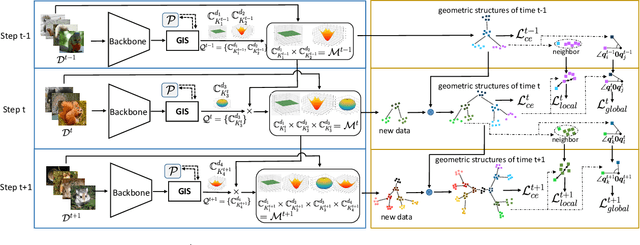
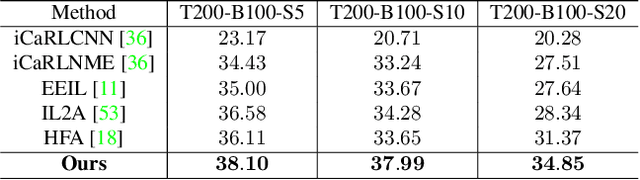
Continual learning aims to efficiently learn from a non-stationary stream of data while avoiding forgetting the knowledge of old data. In many practical applications, data complies with non-Euclidean geometry. As such, the commonly used Euclidean space cannot gracefully capture non-Euclidean geometric structures of data, leading to inferior results. In this paper, we study continual learning from a novel perspective by exploring data geometry for the non-stationary stream of data. Our method dynamically expands the geometry of the underlying space to match growing geometric structures induced by new data, and prevents forgetting by keeping geometric structures of old data into account. In doing so, making use of the mixed curvature space, we propose an incremental search scheme, through which the growing geometric structures are encoded. Then, we introduce an angular-regularization loss and a neighbor-robustness loss to train the model, capable of penalizing the change of global geometric structures and local geometric structures. Experiments show that our method achieves better performance than baseline methods designed in Euclidean space.
A Decomposition Model for Stereo Matching
Apr 15, 2021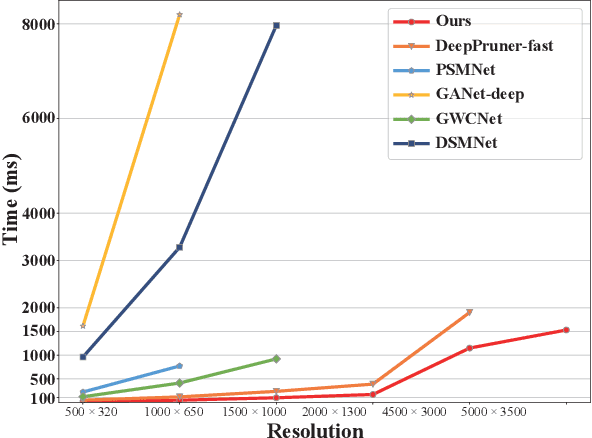
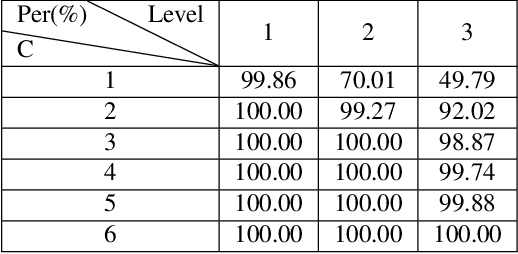
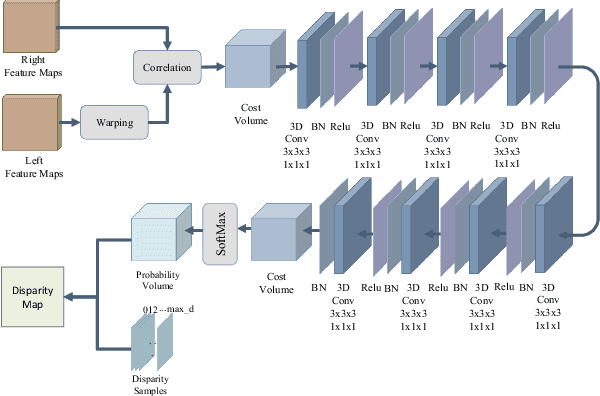

In this paper, we present a decomposition model for stereo matching to solve the problem of excessive growth in computational cost (time and memory cost) as the resolution increases. In order to reduce the huge cost of stereo matching at the original resolution, our model only runs dense matching at a very low resolution and uses sparse matching at different higher resolutions to recover the disparity of lost details scale-by-scale. After the decomposition of stereo matching, our model iteratively fuses the sparse and dense disparity maps from adjacent scales with an occlusion-aware mask. A refinement network is also applied to improving the fusion result. Compared with high-performance methods like PSMNet and GANet, our method achieves $10-100\times$ speed increase while obtaining comparable disparity estimation results.
A Hyperbolic-to-Hyperbolic Graph Convolutional Network
Apr 14, 2021



Hyperbolic graph convolutional networks (GCNs) demonstrate powerful representation ability to model graphs with hierarchical structure. Existing hyperbolic GCNs resort to tangent spaces to realize graph convolution on hyperbolic manifolds, which is inferior because tangent space is only a local approximation of a manifold. In this paper, we propose a hyperbolic-to-hyperbolic graph convolutional network (H2H-GCN) that directly works on hyperbolic manifolds. Specifically, we developed a manifold-preserving graph convolution that consists of a hyperbolic feature transformation and a hyperbolic neighborhood aggregation. The hyperbolic feature transformation works as linear transformation on hyperbolic manifolds. It ensures the transformed node representations still lie on the hyperbolic manifold by imposing the orthogonal constraint on the transformation sub-matrix. The hyperbolic neighborhood aggregation updates each node representation via the Einstein midpoint. The H2H-GCN avoids the distortion caused by tangent space approximations and keeps the global hyperbolic structure. Extensive experiments show that the H2H-GCN achieves substantial improvements on the link prediction, node classification, and graph classification tasks.
Video Captioning Using Weak Annotation
Sep 02, 2020



Video captioning has shown impressive progress in recent years. One key reason of the performance improvements made by existing methods lie in massive paired video-sentence data, but collecting such strong annotation, i.e., high-quality sentences, is time-consuming and laborious. It is the fact that there now exist an amazing number of videos with weak annotation that only contains semantic concepts such as actions and objects. In this paper, we investigate using weak annotation instead of strong annotation to train a video captioning model. To this end, we propose a progressive visual reasoning method that progressively generates fine sentences from weak annotations by inferring more semantic concepts and their dependency relationships for video captioning. To model concept relationships, we use dependency trees that are spanned by exploiting external knowledge from large sentence corpora. Through traversing the dependency trees, the sentences are generated to train the captioning model. Accordingly, we develop an iterative refinement algorithm that refines sentences via spanning dependency trees and fine-tunes the captioning model using the refined sentences in an alternative training manner. Experimental results demonstrate that our method using weak annotation is very competitive to the state-of-the-art methods using strong annotation.
Content-Aware Inter-Scale Cost Aggregation for Stereo Matching
Jun 05, 2020



Cost aggregation is a key component of stereo matching for high-quality depth estimation. Most methods use multi-scale processing to downsample cost volume for proper context information, but will cause loss of details when upsampling. In this paper, we present a content-aware inter-scale cost aggregation method that adaptively aggregates and upsamples the cost volume from coarse-scale to fine-scale by learning dynamic filter weights according to the content of the left and right views on the two scales. Our method achieves reliable detail recovery when upsampling through the aggregation of information across different scales. Furthermore, a novel decomposition strategy is proposed to efficiently construct the 3D filter weights and aggregate the 3D cost volume, which greatly reduces the computation cost. We first learn the 2D similarities via the feature maps on the two scales, and then build the 3D filter weights based on the 2D similarities from the left and right views. After that, we split the aggregation in a full 3D spatial-disparity space into the aggregation in 1D disparity space and 2D spatial space. Experiment results on Scene Flow dataset, KITTI2015 and Middlebury demonstrate the effectiveness of our method.
Deep 3D Portrait from a Single Image
Apr 24, 2020



In this paper, we present a learning-based approach for recovering the 3D geometry of human head from a single portrait image. Our method is learned in an unsupervised manner without any ground-truth 3D data. We represent the head geometry with a parametric 3D face model together with a depth map for other head regions including hair and ear. A two-step geometry learning scheme is proposed to learn 3D head reconstruction from in-the-wild face images, where we first learn face shape on single images using self-reconstruction and then learn hair and ear geometry using pairs of images in a stereo-matching fashion. The second step is based on the output of the first to not only improve the accuracy but also ensure the consistency of overall head geometry. We evaluate the accuracy of our method both in 3D and with pose manipulation tasks on 2D images. We alter pose based on the recovered geometry and apply a refinement network trained with adversarial learning to ameliorate the reprojected images and translate them to the real image domain. Extensive evaluations and comparison with previous methods show that our new method can produce high-fidelity 3D head geometry and head pose manipulation results.
Relational Reasoning using Prior Knowledge for Visual Captioning
Jun 04, 2019



Exploiting relationships among objects has achieved remarkable progress in interpreting images or videos by natural language. Most existing methods resort to first detecting objects and their relationships, and then generating textual descriptions, which heavily depends on pre-trained detectors and leads to performance drop when facing problems of heavy occlusion, tiny-size objects and long-tail in object detection. In addition, the separate procedure of detecting and captioning results in semantic inconsistency between the pre-defined object/relation categories and the target lexical words. We exploit prior human commonsense knowledge for reasoning relationships between objects without any pre-trained detectors and reaching semantic coherency within one image or video in captioning. The prior knowledge (e.g., in the form of knowledge graph) provides commonsense semantic correlation and constraint between objects that are not explicit in the image and video, serving as useful guidance to build semantic graph for sentence generation. Particularly, we present a joint reasoning method that incorporates 1) commonsense reasoning for embedding image or video regions into semantic space to build semantic graph and 2) relational reasoning for encoding semantic graph to generate sentences. Extensive experiments on the MS-COCO image captioning benchmark and the MSVD video captioning benchmark validate the superiority of our method on leveraging prior commonsense knowledge to enhance relational reasoning for visual captioning.