 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiaolong Yang
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
Apr 16, 2024
We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos. Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method not only delivers high video quality with realistic facial and head dynamics but also supports the online generation of 512x512 videos at up to 40 FPS with negligible starting latency. It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
GaussianCube: Structuring Gaussian Splatting using Optimal Transport for 3D Generative Modeling
Apr 05, 2024

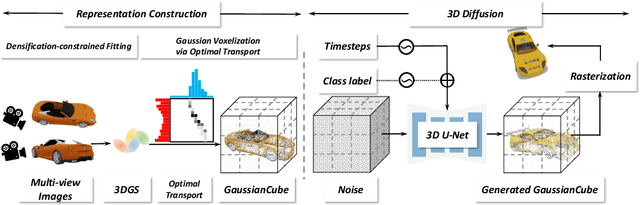
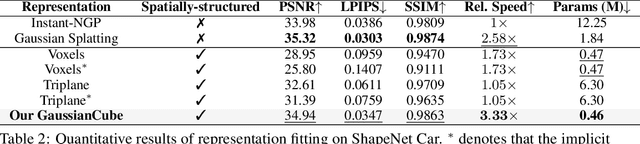
3D Gaussian Splatting (GS) have achieved considerable improvement over Neural Radiance Fields in terms of 3D fitting fidelity and rendering speed. However, this unstructured representation with scattered Gaussians poses a significant challenge for generative modeling. To address the problem, we introduce GaussianCube, a structured GS representation that is both powerful and efficient for generative modeling. We achieve this by first proposing a modified densification-constrained GS fitting algorithm which can yield high-quality fitting results using a fixed number of free Gaussians, and then re-arranging the Gaussians into a predefined voxel grid via Optimal Transport. The structured grid representation allows us to use standard 3D U-Net as our backbone in diffusion generative modeling without elaborate designs. Extensive experiments conducted on ShapeNet and OmniObject3D show that our model achieves state-of-the-art generation results both qualitatively and quantitatively, underscoring the potential of GaussianCube as a powerful and versatile 3D representation.
Diffusion Models are Geometry Critics: Single Image 3D Editing Using Pre-Trained Diffusion Priors
Mar 18, 2024
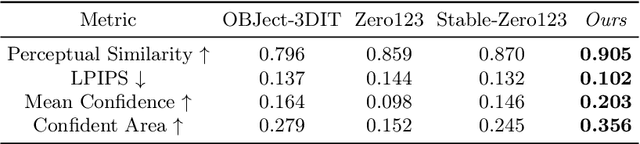
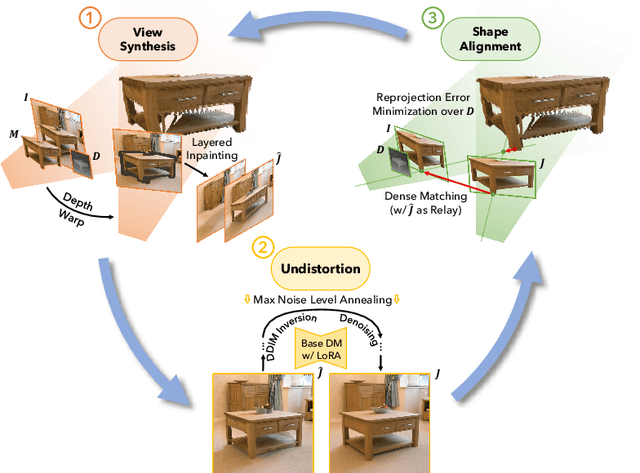

We propose a novel image editing technique that enables 3D manipulations on single images, such as object rotation and translation. Existing 3D-aware image editing approaches typically rely on synthetic multi-view datasets for training specialized models, thus constraining their effectiveness on open-domain images featuring significantly more varied layouts and styles. In contrast, our method directly leverages powerful image diffusion models trained on a broad spectrum of text-image pairs and thus retain their exceptional generalization abilities. This objective is realized through the development of an iterative novel view synthesis and geometry alignment algorithm. The algorithm harnesses diffusion models for dual purposes: they provide appearance prior by predicting novel views of the selected object using estimated depth maps, and they act as a geometry critic by correcting misalignments in 3D shapes across the sampled views. Our method can generate high-quality 3D-aware image edits with large viewpoint transformations and high appearance and shape consistency with the input image, pushing the boundaries of what is possible with single-image 3D-aware editing.
A Simple Baseline for Spoken Language to Sign Language Translation with 3D Avatars
Jan 09, 2024The objective of this paper is to develop a functional system for translating spoken languages into sign languages, referred to as Spoken2Sign translation. The Spoken2Sign task is orthogonal and complementary to traditional sign language to spoken language (Sign2Spoken) translation. To enable Spoken2Sign translation, we present a simple baseline consisting of three steps: 1) creating a gloss-video dictionary using existing Sign2Spoken benchmarks; 2) estimating a 3D sign for each sign video in the dictionary; 3) training a Spoken2Sign model, which is composed of a Text2Gloss translator, a sign connector, and a rendering module, with the aid of the yielded gloss-3D sign dictionary. The translation results are then displayed through a sign avatar. As far as we know, we are the first to present the Spoken2Sign task in an output format of 3D signs. In addition to its capability of Spoken2Sign translation, we also demonstrate that two by-products of our approach-3D keypoint augmentation and multi-view understanding-can assist in keypoint-based sign language understanding. Code and models will be available at https://github.com/FangyunWei/SLRT
Unifying Correspondence, Pose and NeRF for Pose-Free Novel View Synthesis from Stereo Pairs
Dec 12, 2023This work delves into the task of pose-free novel view synthesis from stereo pairs, a challenging and pioneering task in 3D vision. Our innovative framework, unlike any before, seamlessly integrates 2D correspondence matching, camera pose estimation, and NeRF rendering, fostering a synergistic enhancement of these tasks. We achieve this through designing an architecture that utilizes a shared representation, which serves as a foundation for enhanced 3D geometry understanding. Capitalizing on the inherent interplay between the tasks, our unified framework is trained end-to-end with the proposed training strategy to improve overall model accuracy. Through extensive evaluations across diverse indoor and outdoor scenes from two real-world datasets, we demonstrate that our approach achieves substantial improvement over previous methodologies, especially in scenarios characterized by extreme viewpoint changes and the absence of accurate camera poses.
AniPortraitGAN: Animatable 3D Portrait Generation from 2D Image Collections
Sep 05, 2023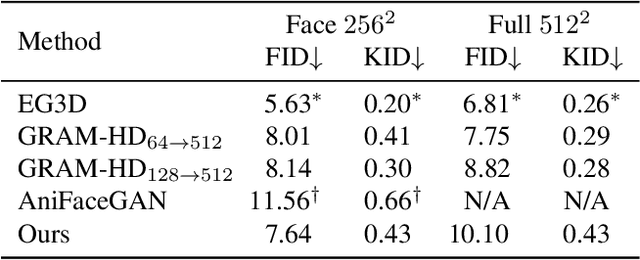
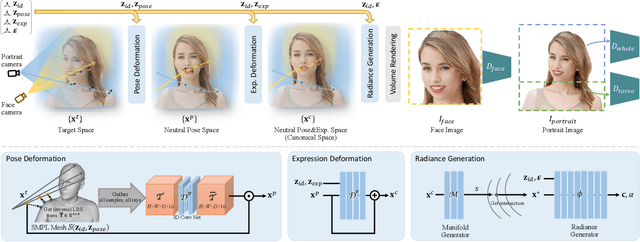


Previous animatable 3D-aware GANs for human generation have primarily focused on either the human head or full body. However, head-only videos are relatively uncommon in real life, and full body generation typically does not deal with facial expression control and still has challenges in generating high-quality results. Towards applicable video avatars, we present an animatable 3D-aware GAN that generates portrait images with controllable facial expression, head pose, and shoulder movements. It is a generative model trained on unstructured 2D image collections without using 3D or video data. For the new task, we base our method on the generative radiance manifold representation and equip it with learnable facial and head-shoulder deformations. A dual-camera rendering and adversarial learning scheme is proposed to improve the quality of the generated faces, which is critical for portrait images. A pose deformation processing network is developed to generate plausible deformations for challenging regions such as long hair. Experiments show that our method, trained on unstructured 2D images, can generate diverse and high-quality 3D portraits with desired control over different properties.
3D-aware Image Generation using 2D Diffusion Models
Mar 31, 2023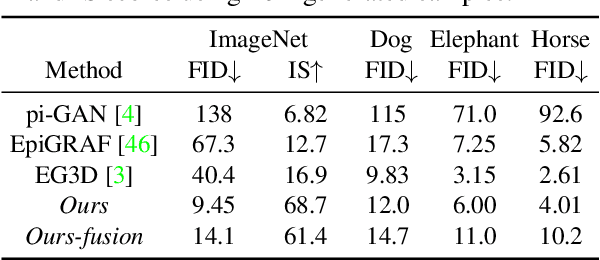
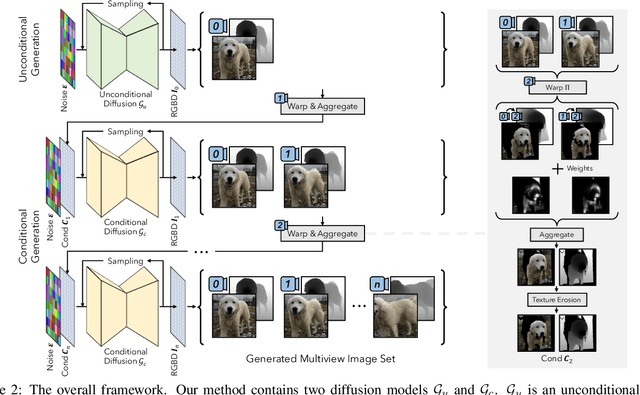
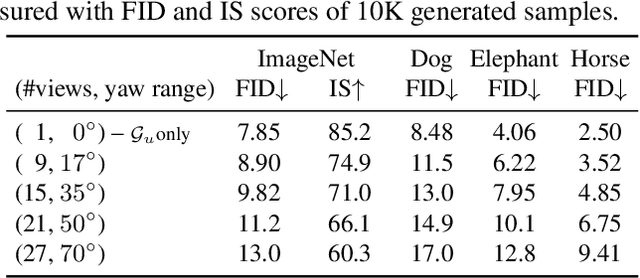
In this paper, we introduce a novel 3D-aware image generation method that leverages 2D diffusion models. We formulate the 3D-aware image generation task as multiview 2D image set generation, and further to a sequential unconditional-conditional multiview image generation process. This allows us to utilize 2D diffusion models to boost the generative modeling power of the method. Additionally, we incorporate depth information from monocular depth estimators to construct the training data for the conditional diffusion model using only still images. We train our method on a large-scale dataset, i.e., ImageNet, which is not addressed by previous methods. It produces high-quality images that significantly outperform prior methods. Furthermore, our approach showcases its capability to generate instances with large view angles, even though the training images are diverse and unaligned, gathered from "in-the-wild" real-world environments.
RemoteTouch: Enhancing Immersive 3D Video Communication with Hand Touch
Feb 28, 2023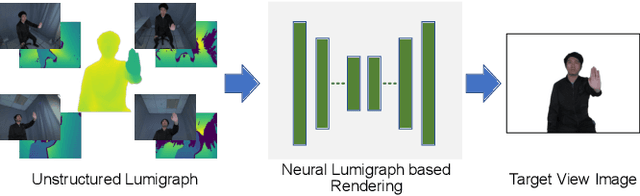

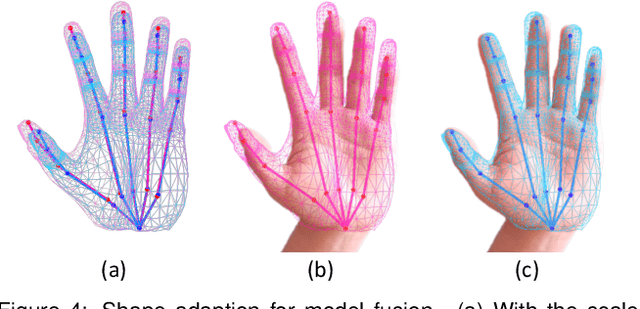

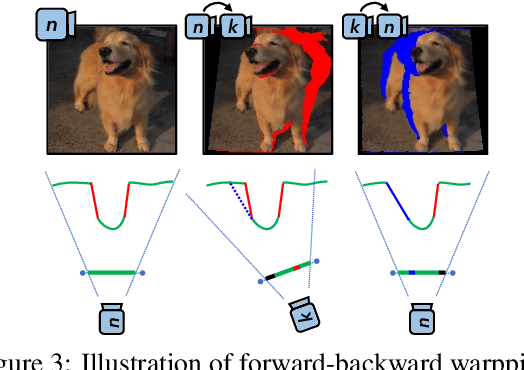
Recent research advance has significantly improved the visual realism of immersive 3D video communication. In this work we present a method to further enhance this immersive experience by adding the hand touch capability ("remote hand clapping"). In our system, each meeting participant sits in front of a large screen with haptic feedback. The local participant can reach his hand out to the screen and perform hand clapping with the remote participant as if the two participants were only separated by a virtual glass. A key challenge in emulating the remote hand touch is the realistic rendering of the participant's hand and arm as the hand touches the screen. When the hand is very close to the screen, the RGBD data required for realistic rendering is no longer available. To tackle this challenge, we present a dual representation of the user's hand. Our dual representation not only preserves the high-quality rendering usually found in recent image-based rendering systems but also allows the hand to reach the screen. This is possible because the dual representation includes both an image-based model and a 3D geometry-based model, with the latter driven by a hand skeleton tracked by a side view camera. In addition, the dual representation provides a distance-based fusion of the image-based and 3D geometry-based models as the hand moves closer to the screen. The result is that the image-based and 3D geometry-based models mutually enhance each other, leading to realistic and seamless rendering. Our experiments demonstrate that our method provides consistent hand contact experience between remote users and improves the immersive experience of 3D video communication.
FreeEnricher: Enriching Face Landmarks without Additional Cost
Dec 19, 2022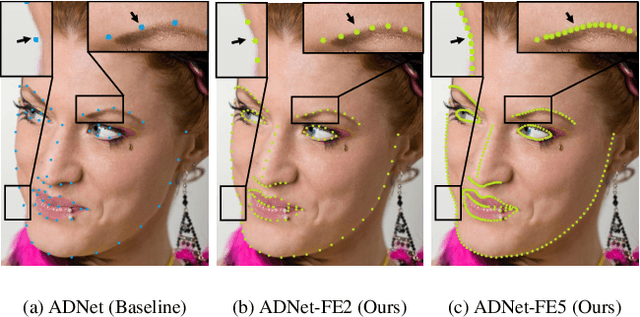
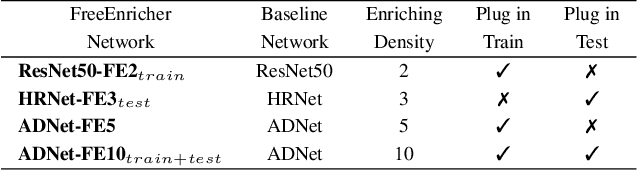

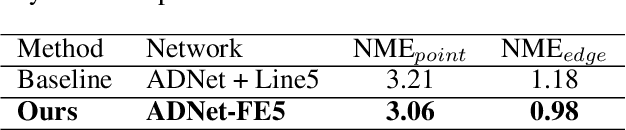
Recent years have witnessed significant growth of face alignment. Though dense facial landmark is highly demanded in various scenarios, e.g., cosmetic medicine and facial beautification, most works only consider sparse face alignment. To address this problem, we present a framework that can enrich landmark density by existing sparse landmark datasets, e.g., 300W with 68 points and WFLW with 98 points. Firstly, we observe that the local patches along each semantic contour are highly similar in appearance. Then, we propose a weakly-supervised idea of learning the refinement ability on original sparse landmarks and adapting this ability to enriched dense landmarks. Meanwhile, several operators are devised and organized together to implement the idea. Finally, the trained model is applied as a plug-and-play module to the existing face alignment networks. To evaluate our method, we manually label the dense landmarks on 300W testset. Our method yields state-of-the-art accuracy not only in newly-constructed dense 300W testset but also in the original sparse 300W and WFLW testsets without additional cost.
NeRFInvertor: High Fidelity NeRF-GAN Inversion for Single-shot Real Image Animation
Nov 30, 2022


Nerf-based Generative models have shown impressive capacity in generating high-quality images with consistent 3D geometry. Despite successful synthesis of fake identity images randomly sampled from latent space, adopting these models for generating face images of real subjects is still a challenging task due to its so-called inversion issue. In this paper, we propose a universal method to surgically fine-tune these NeRF-GAN models in order to achieve high-fidelity animation of real subjects only by a single image. Given the optimized latent code for an out-of-domain real image, we employ 2D loss functions on the rendered image to reduce the identity gap. Furthermore, our method leverages explicit and implicit 3D regularizations using the in-domain neighborhood samples around the optimized latent code to remove geometrical and visual artifacts. Our experiments confirm the effectiveness of our method in realistic, high-fidelity, and 3D consistent animation of real faces on multiple NeRF-GAN models across different datasets.