 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Yin
AMERICANO: Argument Generation with Discourse-driven Decomposition and Agent Interaction
Oct 31, 2023
Argument generation is a challenging task in natural language processing, which requires rigorous reasoning and proper content organization. Inspired by recent chain-of-thought prompting that breaks down a complex task into intermediate steps, we propose Americano, a novel framework with agent interaction for argument generation. Our approach decomposes the generation process into sequential actions grounded on argumentation theory, which first executes actions sequentially to generate argumentative discourse components, and then produces a final argument conditioned on the components. To further mimic the human writing process and improve the left-to-right generation paradigm of current autoregressive language models, we introduce an argument refinement module which automatically evaluates and refines argument drafts based on feedback received. We evaluate our framework on the task of counterargument generation using a subset of Reddit/CMV dataset. The results show that our method outperforms both end-to-end and chain-of-thought prompting methods and can generate more coherent and persuasive arguments with diverse and rich contents.
Camouflaged Image Synthesis Is All You Need to Boost Camouflaged Detection
Aug 13, 2023
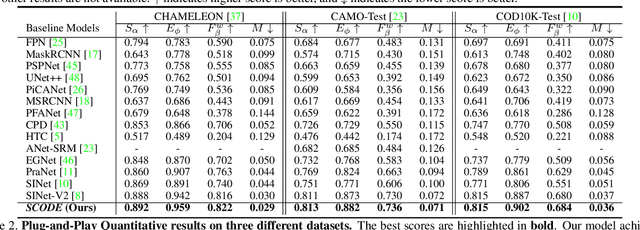

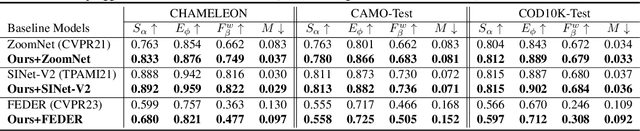
Camouflaged objects that blend into natural scenes pose significant challenges for deep-learning models to detect and synthesize. While camouflaged object detection is a crucial task in computer vision with diverse real-world applications, this research topic has been constrained by limited data availability. We propose a framework for synthesizing camouflage data to enhance the detection of camouflaged objects in natural scenes. Our approach employs a generative model to produce realistic camouflage images, which can be used to train existing object detection models. Specifically, we use a camouflage environment generator supervised by a camouflage distribution classifier to synthesize the camouflage images, which are then fed into our generator to expand the dataset. Our framework outperforms the current state-of-the-art method on three datasets (COD10k, CAMO, and CHAMELEON), demonstrating its effectiveness in improving camouflaged object detection. This approach can serve as a plug-and-play data generation and augmentation module for existing camouflaged object detection tasks and provides a novel way to introduce more diversity and distributions into current camouflage datasets.
NeRFInvertor: High Fidelity NeRF-GAN Inversion for Single-shot Real Image Animation
Nov 30, 2022


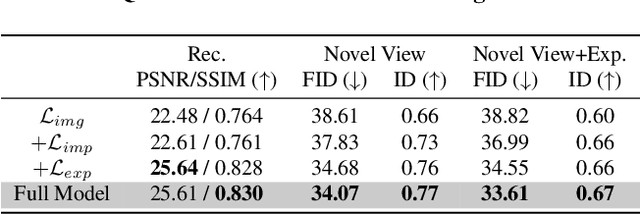
Nerf-based Generative models have shown impressive capacity in generating high-quality images with consistent 3D geometry. Despite successful synthesis of fake identity images randomly sampled from latent space, adopting these models for generating face images of real subjects is still a challenging task due to its so-called inversion issue. In this paper, we propose a universal method to surgically fine-tune these NeRF-GAN models in order to achieve high-fidelity animation of real subjects only by a single image. Given the optimized latent code for an out-of-domain real image, we employ 2D loss functions on the rendered image to reduce the identity gap. Furthermore, our method leverages explicit and implicit 3D regularizations using the in-domain neighborhood samples around the optimized latent code to remove geometrical and visual artifacts. Our experiments confirm the effectiveness of our method in realistic, high-fidelity, and 3D consistent animation of real faces on multiple NeRF-GAN models across different datasets.
Semi-supervised Domain Adaptive Structure Learning
Dec 12, 2021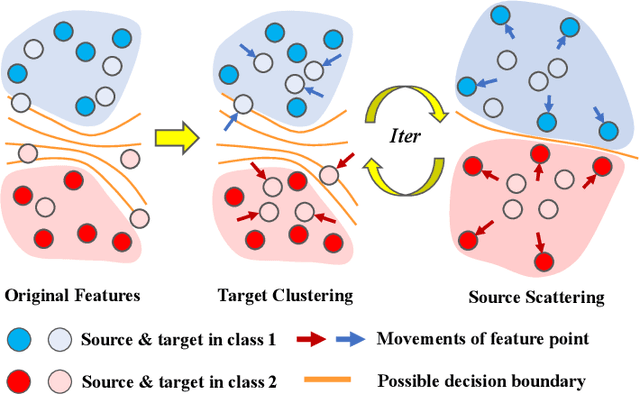
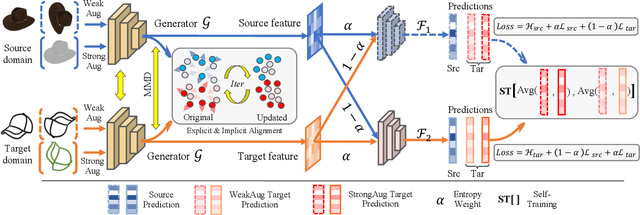
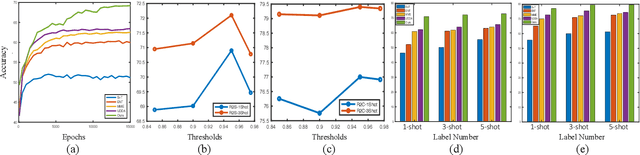

Semi-supervised domain adaptation (SSDA) is quite a challenging problem requiring methods to overcome both 1) overfitting towards poorly annotated data and 2) distribution shift across domains. Unfortunately, a simple combination of domain adaptation (DA) and semi-supervised learning (SSL) methods often fail to address such two objects because of training data bias towards labeled samples. In this paper, we introduce an adaptive structure learning method to regularize the cooperation of SSL and DA. Inspired by the multi-views learning, our proposed framework is composed of a shared feature encoder network and two classifier networks, trained for contradictory purposes. Among them, one of the classifiers is applied to group target features to improve intra-class density, enlarging the gap of categorical clusters for robust representation learning. Meanwhile, the other classifier, serviced as a regularizer, attempts to scatter the source features to enhance the smoothness of the decision boundary. The iterations of target clustering and source expansion make the target features being well-enclosed inside the dilated boundary of the corresponding source points. For the joint address of cross-domain features alignment and partially labeled data learning, we apply the maximum mean discrepancy (MMD) distance minimization and self-training (ST) to project the contradictory structures into a shared view to make the reliable final decision. The experimental results over the standard SSDA benchmarks, including DomainNet and Office-home, demonstrate both the accuracy and robustness of our method over the state-of-the-art approaches.
Context-Aware Interaction Network for Question Matching
Apr 17, 2021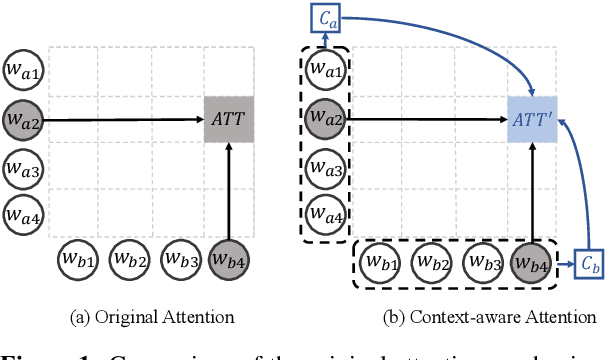
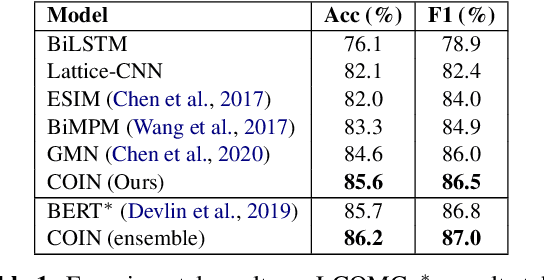
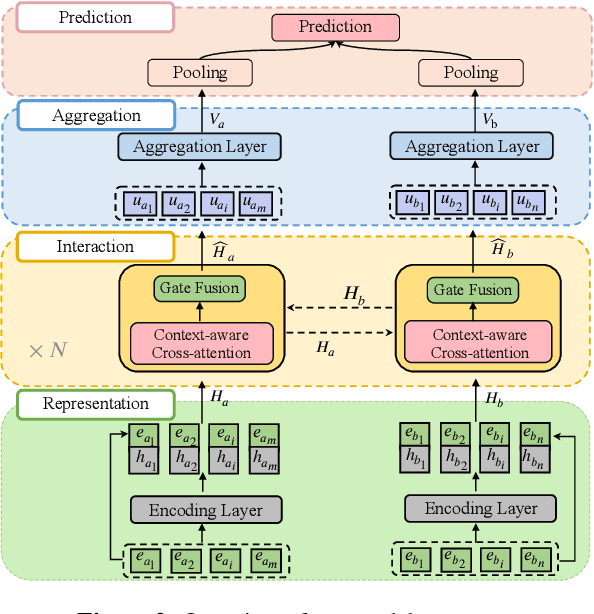

Impressive milestones have been achieved in text matching by adopting a cross-attention mechanism to capture pertinent semantic connections between two sentences. However, these cross-attention mechanisms focus on word-level links between the two inputs, neglecting the importance of contextual information. We propose a context-aware interaction network (COIN) to properly align two sequences and infer their semantic relationship. Specifically, each interaction block includes (1) a context-aware cross-attention mechanism to effectively integrate contextual information, and (2) a gate fusion layer to flexibly interpolate aligned representations. We apply multiple stacked interaction blocks to produce alignments at different levels and gradually refine the attention results. Experiments on two question matching datasets and detailed analyses confirm the effectiveness of our model.
Quality meets Diversity: A Model-Agnostic Framework for Computerized Adaptive Testing
Jan 15, 2021
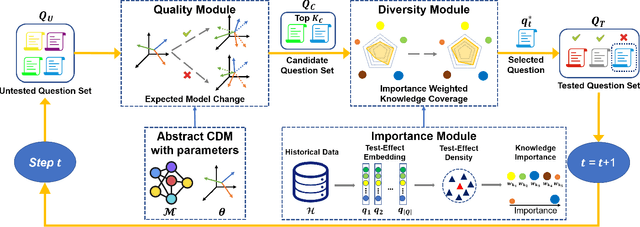
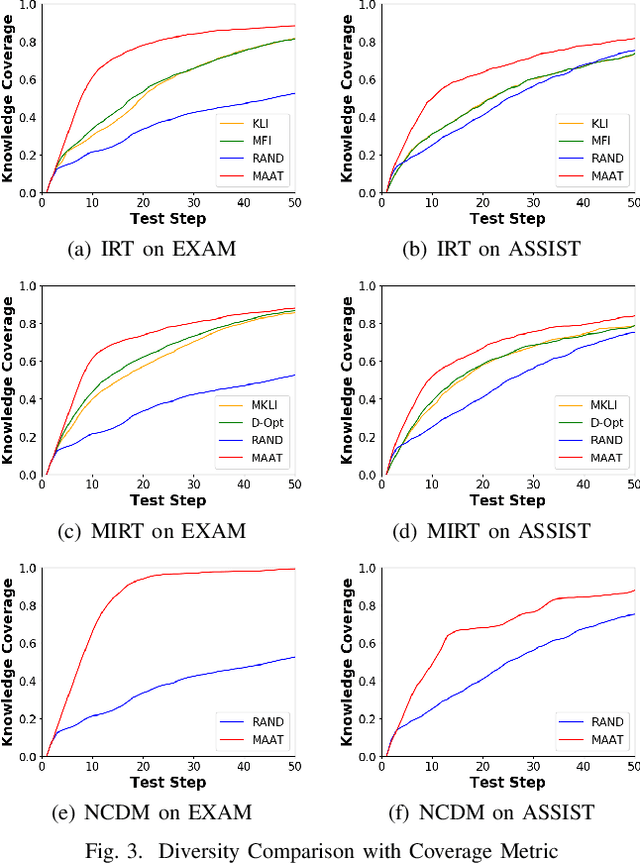
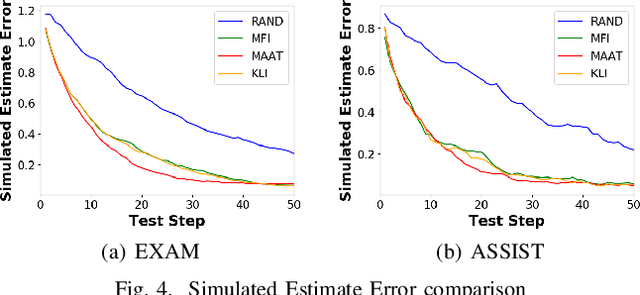
Computerized Adaptive Testing (CAT) is emerging as a promising testing application in many scenarios, such as education, game and recruitment, which targets at diagnosing the knowledge mastery levels of examinees on required concepts. It shows the advantage of tailoring a personalized testing procedure for each examinee, which selects questions step by step, depending on her performance. While there are many efforts on developing CAT systems, existing solutions generally follow an inflexible model-specific fashion. That is, they need to observe a specific cognitive model which can estimate examinee's knowledge levels and design the selection strategy according to the model estimation. In this paper, we study a novel model-agnostic CAT problem, where we aim to propose a flexible framework that can adapt to different cognitive models. Meanwhile, this work also figures out CAT solution with addressing the problem of how to generate both high-quality and diverse questions simultaneously, which can give a comprehensive knowledge diagnosis for each examinee. Inspired by Active Learning, we propose a novel framework, namely Model-Agnostic Adaptive Testing (MAAT) for CAT solution, where we design three sophisticated modules including Quality Module, Diversity Module and Importance Module. Extensive experimental results on two real-world datasets clearly demonstrate that our MAAT can support CAT with guaranteeing both quality and diversity perspectives.
Multimodal In-bed Pose and Shape Estimation under the Blankets
Dec 12, 2020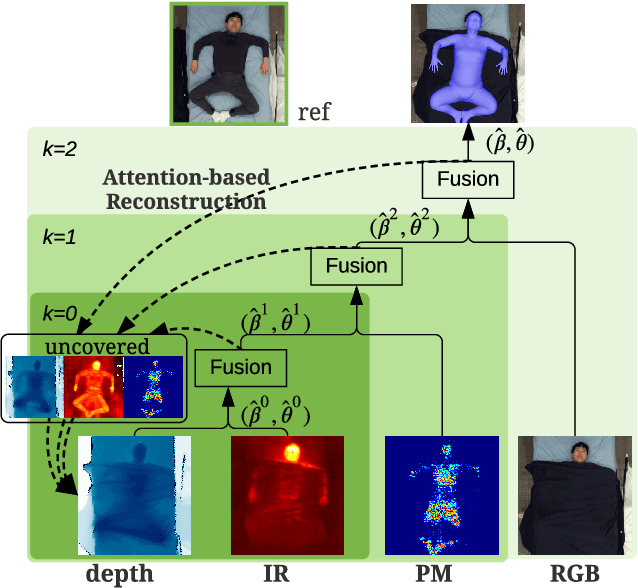
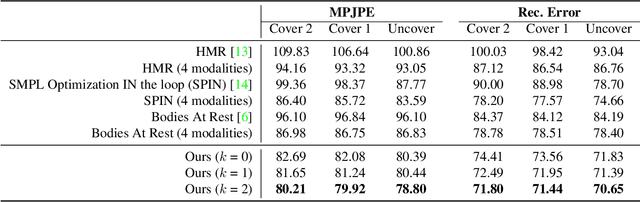
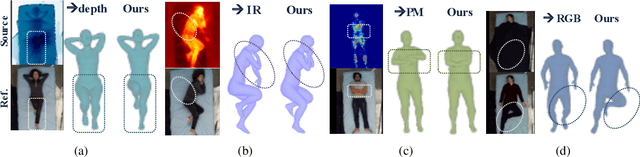

Humans spend vast hours in bed -- about one-third of the lifetime on average. Besides, a human at rest is vital in many healthcare applications. Typically, humans are covered by a blanket when resting, for which we propose a multimodal approach to uncover the subjects so their bodies at rest can be viewed without the occlusion of the blankets above. We propose a pyramid scheme to effectively fuse the different modalities in a way that best leverages the knowledge captured by the multimodal sensors. Specifically, the two most informative modalities (i.e., depth and infrared images) are first fused to generate good initial pose and shape estimation. Then pressure map and RGB images are further fused one by one to refine the result by providing occlusion-invariant information for the covered part, and accurate shape information for the uncovered part, respectively. However, even with multimodal data, the task of detecting human bodies at rest is still very challenging due to the extreme occlusion of bodies. To further reduce the negative effects of the occlusion from blankets, we employ an attention-based reconstruction module to generate uncovered modalities, which are further fused to update current estimation via a cyclic fashion. Extensive experiments validate the superiority of the proposed model over others.
SuperFront: From Low-resolution to High-resolution Frontal Face Synthesis
Dec 07, 2020

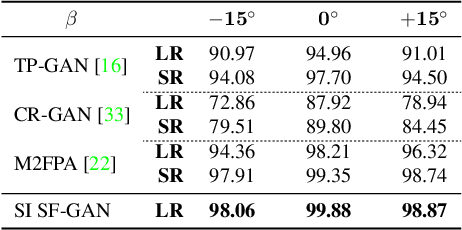

Advances in face rotation, along with other face-based generative tasks, are more frequent as we advance further in topics of deep learning. Even as impressive milestones are achieved in synthesizing faces, the importance of preserving identity is needed in practice and should not be overlooked. Also, the difficulty should not be more for data with obscured faces, heavier poses, and lower quality. Existing methods tend to focus on samples with variation in pose, but with the assumption data is high in quality. We propose a generative adversarial network (GAN) -based model to generate high-quality, identity preserving frontal faces from one or multiple low-resolution (LR) faces with extreme poses. Specifically, we propose SuperFront-GAN (SF-GAN) to synthesize a high-resolution (HR), frontal face from one-to-many LR faces with various poses and with the identity-preserved. We integrate a super-resolution (SR) side-view module into SF-GAN to preserve identity information and fine details of the side-views in HR space, which helps model reconstruct high-frequency information of faces (i.e., periocular, nose, and mouth regions). Moreover, SF-GAN accepts multiple LR faces as input, and improves each added sample. We squeeze additional gain in performance with an orthogonal constraint in the generator to penalize redundant latent representations and, hence, diversify the learned features space. Quantitative and qualitative results demonstrate the superiority of SF-GAN over others.
Collaborative Attention Mechanism for Multi-View Action Recognition
Sep 14, 2020
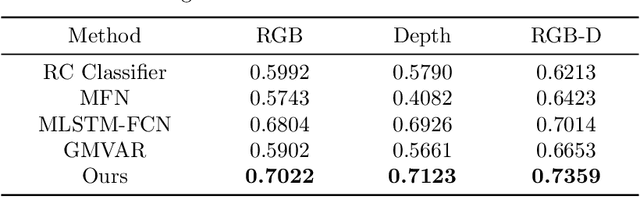
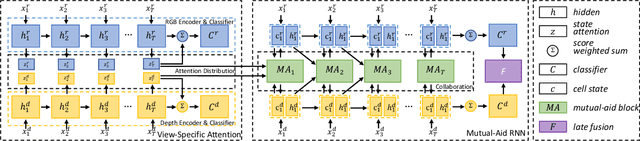
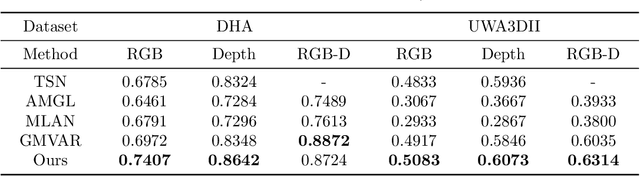
Multi-view action recognition (MVAR) leverages complementary temporal information from different views to enhance the learning process. Attention is an effective mechanism which has been extensively adopted for modeling temporal data. However, most existing MVAR methods only utilize attention to extract view-specific patterns. They ignore the potential to dig latent mutual-support information inattention space. To fully take the advantage of the multi-view cooperation, we propose a collaborative attention mechanism (CAM). It detects the attention differences among multi-view inputs, and adaptively integrates complementary frame-level information to benefit each other. Specifically, we utilize recurrent neural network (RNN) by expanding long short-term memory (LSTM) as a Mutual-Aid RNN (MAR). CAM takes advantages of view-specific attention pattern to guide another view and unlock potential information which is hard to explore by itself. Extensive experiments on three action datasets illustrate our CAM achieves better result for each single view, and also boosts the multi-view performance.
Families In Wild Multimedia (FIW-MM): A Multi-Modal Database for Recognizing Kinship
Jul 28, 2020
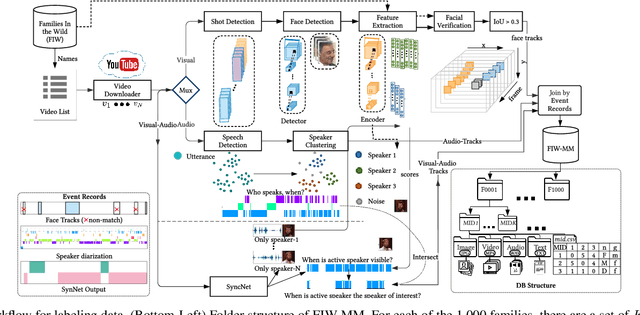


Recognizing kinship - a soft biometric with vast applications - in photos has piqued the interest of many machine vision researchers. The large-scale Families In the Wild (FIW) database promoted the problem by supporting annual kinship-based vision challenges that saw consistent performance improvements. We have now begun to approach performance levels for image-based systems acceptable for practical use - something unforeseeable a decade ago. However, biometric systems can benefit from multi-modal perspectives, as information contained in multimedia can add to and complement that of still images. Thus, we aim to narrow the gap from research-to-reality by extending FIW with multimedia data (i.e., video, audio, and contextual transcripts). Specifically, we introduce the first large-scale dataset for recognizing kinship in multimedia, the FIW in Multimedia (FIW-MM) database. We utilize automated machinery to collect, annotate, and prepare the data with minimal human input and no financial cost. This large-scale, multimedia corpus allows problem formulations to follow more realistic template-based protocols. We show significant improvements in benchmarks for multiple kin-based tasks when additional media-types are added. Experiments provide insights by highlighting edge cases to inspire future research and areas of improvement. Emphasis is put on short and long-term research directions, with the overarching intent to increase the potential of systems built to automatically detect kinship in multimedia. Furthermore, we expect a broader range of researchers with recognition tasks, generative modeling, speech understanding, and nature-based narratives.