 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuan Wang
Don't Judge by the Look: Towards Motion Coherent Video Representation
Mar 25, 2024


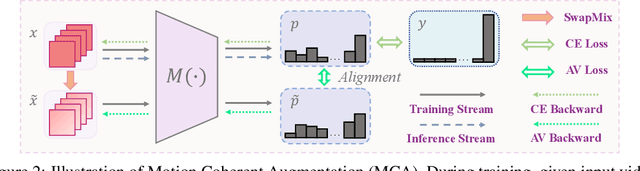

Current training pipelines in object recognition neglect Hue Jittering when doing data augmentation as it not only brings appearance changes that are detrimental to classification, but also the implementation is inefficient in practice. In this study, we investigate the effect of hue variance in the context of video understanding and find this variance to be beneficial since static appearances are less important in videos that contain motion information. Based on this observation, we propose a data augmentation method for video understanding, named Motion Coherent Augmentation (MCA), that introduces appearance variation in videos and implicitly encourages the model to prioritize motion patterns, rather than static appearances. Concretely, we propose an operation SwapMix to efficiently modify the appearance of video samples, and introduce Variation Alignment (VA) to resolve the distribution shift caused by SwapMix, enforcing the model to learn appearance invariant representations. Comprehensive empirical evaluation across various architectures and different datasets solidly validates the effectiveness and generalization ability of MCA, and the application of VA in other augmentation methods. Code is available at https://github.com/BeSpontaneous/MCA-pytorch.
AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning
Feb 26, 2024Autonomous agents powered by large language models (LLMs) have garnered significant research attention. However, fully harnessing the potential of LLMs for agent-based tasks presents inherent challenges due to the heterogeneous nature of diverse data sources featuring multi-turn trajectories. In this paper, we introduce \textbf{AgentOhana} as a comprehensive solution to address these challenges. \textit{AgentOhana} aggregates agent trajectories from distinct environments, spanning a wide array of scenarios. It meticulously standardizes and unifies these trajectories into a consistent format, streamlining the creation of a generic data loader optimized for agent training. Leveraging the data unification, our training pipeline maintains equilibrium across different data sources and preserves independent randomness across devices during dataset partitioning and model training. Additionally, we present \textbf{xLAM-v0.1}, a large action model tailored for AI agents, which demonstrates exceptional performance across various benchmarks.
AgentLite: A Lightweight Library for Building and Advancing Task-Oriented LLM Agent System
Feb 23, 2024The booming success of LLMs initiates rapid development in LLM agents. Though the foundation of an LLM agent is the generative model, it is critical to devise the optimal reasoning strategies and agent architectures. Accordingly, LLM agent research advances from the simple chain-of-thought prompting to more complex ReAct and Reflection reasoning strategy; agent architecture also evolves from single agent generation to multi-agent conversation, as well as multi-LLM multi-agent group chat. However, with the existing intricate frameworks and libraries, creating and evaluating new reasoning strategies and agent architectures has become a complex challenge, which hinders research investigation into LLM agents. Thus, we open-source a new AI agent library, AgentLite, which simplifies this process by offering a lightweight, user-friendly platform for innovating LLM agent reasoning, architectures, and applications with ease. AgentLite is a task-oriented framework designed to enhance the ability of agents to break down tasks and facilitate the development of multi-agent systems. Furthermore, we introduce multiple practical applications developed with AgentLite to demonstrate its convenience and flexibility. Get started now at: \url{https://github.com/SalesforceAIResearch/AgentLite}.
Text2Data: Low-Resource Data Generation with Textual Control
Feb 08, 2024Natural language serves as a common and straightforward control signal for humans to interact seamlessly with machines. Recognizing the importance of this interface, the machine learning community is investing considerable effort in generating data that is semantically coherent with textual instructions. While strides have been made in text-to-data generation spanning image editing, audio synthesis, video creation, and beyond, low-resource areas characterized by expensive annotations or complex data structures, such as molecules, motion dynamics, and time series, often lack textual labels. This deficiency impedes supervised learning, thereby constraining the application of advanced generative models for text-to-data tasks. In response to these challenges in the low-resource scenario, we propose Text2Data, a novel approach that utilizes unlabeled data to understand the underlying data distribution through an unsupervised diffusion model. Subsequently, it undergoes controllable finetuning via a novel constraint optimization-based learning objective that ensures controllability and effectively counteracts catastrophic forgetting. Comprehensive experiments demonstrate that Text2Data is able to achieve enhanced performance regarding controllability across various modalities, including molecules, motions and time series, when compared to existing baselines.
Causal Layering via Conditional Entropy
Jan 19, 2024Causal discovery aims to recover information about an unobserved causal graph from the observable data it generates. Layerings are orderings of the variables which place causes before effects. In this paper, we provide ways to recover layerings of a graph by accessing the data via a conditional entropy oracle, when distributions are discrete. Our algorithms work by repeatedly removing sources or sinks from the graph. Under appropriate assumptions and conditioning, we can separate the sources or sinks from the remainder of the nodes by comparing their conditional entropy to the unconditional entropy of their noise. Our algorithms are provably correct and run in worst-case quadratic time. The main assumptions are faithfulness and injective noise, and either known noise entropies or weakly monotonically increasing noise entropies along directed paths. In addition, we require one of either a very mild extension of faithfulness, or strictly monotonically increasing noise entropies, or expanding noise injectivity to include an additional single argument in the structural functions.
Editing Arbitrary Propositions in LLMs without Subject Labels
Jan 15, 2024Large Language Model (LLM) editing modifies factual information in LLMs. Locate-and-Edit (L\&E) methods accomplish this by finding where relevant information is stored within the neural network, and editing the weights at that location. The goal of editing is to modify the response of an LLM to a proposition independently of its phrasing, while not modifying its response to other related propositions. Existing methods are limited to binary propositions, which represent straightforward binary relations between a subject and an object. Furthermore, existing methods rely on semantic subject labels, which may not be available or even be well-defined in practice. In this paper, we show that both of these issues can be effectively skirted with a simple and fast localization method called Gradient Tracing (GT). This localization method allows editing arbitrary propositions instead of just binary ones, and does so without the need for subject labels. As propositions always have a truth value, our experiments prompt an LLM as a boolean classifier, and edit its T/F response to propositions. Our method applies GT for location tracing, and then edit the model at that location using a mild variant of Rank-One Model Editing (ROME). On datasets of binary propositions derived from the CounterFact dataset, we show that our method -- without access to subject labels -- performs close to state-of-the-art L\&E methods which has access subject labels. We then introduce a new dataset, Factual Accuracy Classification Test (FACT), which includes non-binary propositions and for which subject labels are not generally applicable, and therefore is beyond the scope of existing L\&E methods. Nevertheless, we show that with our method editing is possible on FACT.
Empowering ChatGPT-Like Large-Scale Language Models with Local Knowledge Base for Industrial Prognostics and Health Management
Dec 06, 2023Prognostics and health management (PHM) is essential for industrial operation and maintenance, focusing on predicting, diagnosing, and managing the health status of industrial systems. The emergence of the ChatGPT-Like large-scale language model (LLM) has begun to lead a new round of innovation in the AI field. It has extensively promoted the level of intelligence in various fields. Therefore, it is also expected further to change the application paradigm in industrial PHM and promote PHM to become intelligent. Although ChatGPT-Like LLMs have rich knowledge reserves and powerful language understanding and generation capabilities, they lack domain-specific expertise, significantly limiting their practicability in PHM applications. To this end, this study explores the ChatGPT-Like LLM empowered by the local knowledge base (LKB) in industrial PHM to solve the above limitations. In addition, we introduce the method and steps of combining the LKB with LLMs, including LKB preparation, LKB vectorization, prompt engineering, etc. Experimental analysis of real cases shows that combining the LKB with ChatGPT-Like LLM can significantly improve its performance and make ChatGPT-Like LLMs more accurate, relevant, and able to provide more insightful information. This can promote the development of ChatGPT-Like LLMs in industrial PHM and promote their efficiency and quality.
MFTCoder: Boosting Code LLMs with Multitask Fine-Tuning
Nov 04, 2023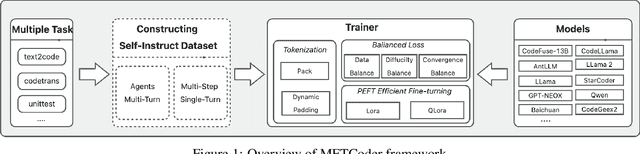

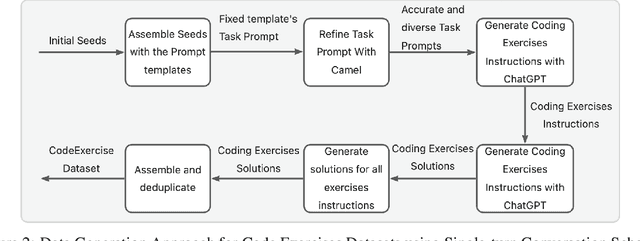
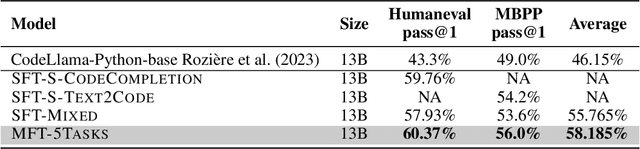
Code LLMs have emerged as a specialized research field, with remarkable studies dedicated to enhancing model's coding capabilities through fine-tuning on pre-trained models. Previous fine-tuning approaches were typically tailored to specific downstream tasks or scenarios, which meant separate fine-tuning for each task, requiring extensive training resources and posing challenges in terms of deployment and maintenance. Furthermore, these approaches failed to leverage the inherent interconnectedness among different code-related tasks. To overcome these limitations, we present a multi-task fine-tuning framework, MFTcoder, that enables simultaneous and parallel fine-tuning on multiple tasks. By incorporating various loss functions, we effectively address common challenges in multi-task learning, such as data imbalance, varying difficulty levels, and inconsistent convergence speeds. Extensive experiments have conclusively demonstrated that our multi-task fine-tuning approach outperforms both individual fine-tuning on single tasks and fine-tuning on a mixed ensemble of tasks. Moreover, MFTcoder offers efficient training capabilities, including efficient data tokenization modes and PEFT fine-tuning, resulting in significantly improved speed compared to traditional fine-tuning methods. MFTcoder seamlessly integrates with several mainstream open-source LLMs, such as CodeLLama and Qwen. Leveraging the CodeLLama foundation, our MFTcoder fine-tuned model, \textsc{CodeFuse-CodeLLama-34B}, achieves an impressive pass@1 score of 74.4\% on the HumaneEval benchmark, surpassing GPT-4 performance (67\%, zero-shot). MFTCoder is open-sourced at \url{https://github.com/codefuse-ai/MFTCOder}
How Do Transformers Learn In-Context Beyond Simple Functions? A Case Study on Learning with Representations
Oct 16, 2023While large language models based on the transformer architecture have demonstrated remarkable in-context learning (ICL) capabilities, understandings of such capabilities are still in an early stage, where existing theory and mechanistic understanding focus mostly on simple scenarios such as learning simple function classes. This paper takes initial steps on understanding ICL in more complex scenarios, by studying learning with representations. Concretely, we construct synthetic in-context learning problems with a compositional structure, where the label depends on the input through a possibly complex but fixed representation function, composed with a linear function that differs in each instance. By construction, the optimal ICL algorithm first transforms the inputs by the representation function, and then performs linear ICL on top of the transformed dataset. We show theoretically the existence of transformers that approximately implement such algorithms with mild depth and size. Empirically, we find trained transformers consistently achieve near-optimal ICL performance in this setting, and exhibit the desired dissection where lower layers transforms the dataset and upper layers perform linear ICL. Through extensive probing and a new pasting experiment, we further reveal several mechanisms within the trained transformers, such as concrete copying behaviors on both the inputs and the representations, linear ICL capability of the upper layers alone, and a post-ICL representation selection mechanism in a harder mixture setting. These observed mechanisms align well with our theory and may shed light on how transformers perform ICL in more realistic scenarios.
CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model
Oct 10, 2023
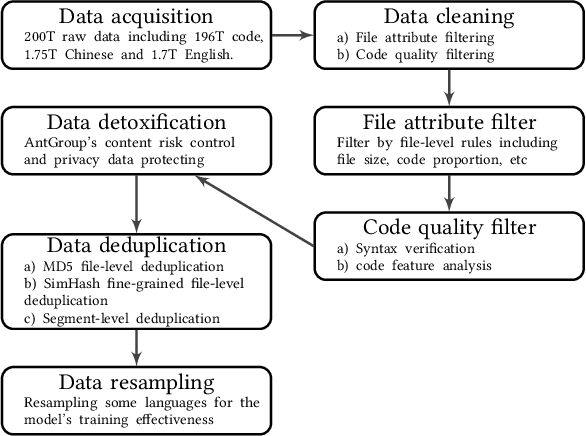
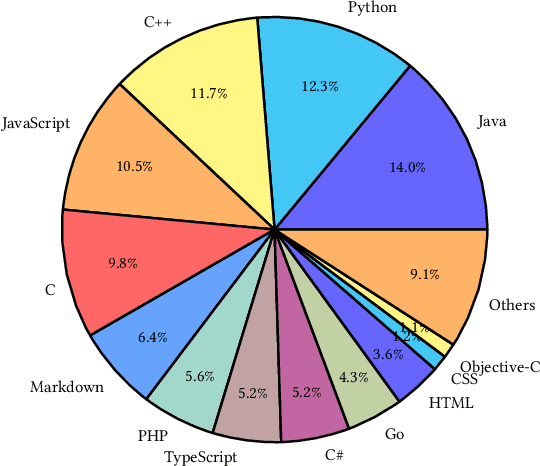

Code Large Language Models (Code LLMs) have gained significant attention in the industry due to their wide applications in the full lifecycle of software engineering. However, the effectiveness of existing models in understanding non-English inputs for multi-lingual code-related tasks is still far from well studied. This paper introduces CodeFuse-13B, an open-sourced pre-trained code LLM. It is specifically designed for code-related tasks with both English and Chinese prompts and supports over 40 programming languages. CodeFuse achieves its effectiveness by utilizing a high quality pre-training dataset that is carefully filtered by program analyzers and optimized during the training process. Extensive experiments are conducted using real-world usage scenarios, the industry-standard benchmark HumanEval-x, and the specially designed CodeFuseEval for Chinese prompts. To assess the effectiveness of CodeFuse, we actively collected valuable human feedback from the AntGroup's software development process where CodeFuse has been successfully deployed. The results demonstrate that CodeFuse-13B achieves a HumanEval pass@1 score of 37.10%, positioning it as one of the top multi-lingual code LLMs with similar parameter sizes. In practical scenarios, such as code generation, code translation, code comments, and testcase generation, CodeFuse performs better than other models when confronted with Chinese prompts.