 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Bai
Dynamic Temperature Knowledge Distillation
Apr 19, 2024
Temperature plays a pivotal role in moderating label softness in the realm of knowledge distillation (KD). Traditional approaches often employ a static temperature throughout the KD process, which fails to address the nuanced complexities of samples with varying levels of difficulty and overlooks the distinct capabilities of different teacher-student pairings. This leads to a less-than-ideal transfer of knowledge. To improve the process of knowledge propagation, we proposed Dynamic Temperature Knowledge Distillation (DTKD) which introduces a dynamic, cooperative temperature control for both teacher and student models simultaneously within each training iterafion. In particular, we proposed "\textbf{sharpness}" as a metric to quantify the smoothness of a model's output distribution. By minimizing the sharpness difference between the teacher and the student, we can derive sample-specific temperatures for them respectively. Extensive experiments on CIFAR-100 and ImageNet-2012 demonstrate that DTKD performs comparably to leading KD techniques, with added robustness in Target Class KD and None-target Class KD scenarios.The code is available at https://github.com/JinYu1998/DTKD.
Deep Learning and LLM-based Methods Applied to Stellar Lightcurve Classification
Apr 16, 2024Light curves serve as a valuable source of information on stellar formation and evolution. With the rapid advancement of machine learning techniques, it can be effectively processed to extract astronomical patterns and information. In this study, we present a comprehensive evaluation of deep-learning and large language model (LLM) based models for the automatic classification of variable star light curves, based on large datasets from the Kepler and K2 missions. Special emphasis is placed on Cepheids, RR Lyrae, and eclipsing binaries, examining the influence of observational cadence and phase distribution on classification precision. Employing AutoDL optimization, we achieve striking performance with the 1D-Convolution+BiLSTM architecture and the Swin Transformer, hitting accuracies of 94\% and 99\% correspondingly, with the latter demonstrating a notable 83\% accuracy in discerning the elusive Type II Cepheids-comprising merely 0.02\% of the total dataset.We unveil StarWhisper LightCurve (LC), an innovative Series comprising three LLM-based models: LLM, multimodal large language model (MLLM), and Large Audio Language Model (LALM). Each model is fine-tuned with strategic prompt engineering and customized training methods to explore the emergent abilities of these models for astronomical data. Remarkably, StarWhisper LC Series exhibit high accuracies around 90\%, significantly reducing the need for explicit feature engineering, thereby paving the way for streamlined parallel data processing and the progression of multifaceted multimodal models in astronomical applications. The study furnishes two detailed catalogs illustrating the impacts of phase and sampling intervals on deep learning classification accuracy, showing that a substantial decrease of up to 14\% in observation duration and 21\% in sampling points can be realized without compromising accuracy by more than 10\%.
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
Apr 08, 2024Large Language Models (LLMs) often memorize sensitive, private, or copyrighted data during pre-training. LLM unlearning aims to eliminate the influence of undesirable data from the pre-trained model while preserving the model's utilities on other tasks. Several practical methods have recently been proposed for LLM unlearning, mostly based on gradient ascent (GA) on the loss of undesirable data. However, on certain unlearning tasks, these methods either fail to effectively unlearn the target data or suffer from catastrophic collapse -- a drastic degradation of the model's utilities. In this paper, we propose Negative Preference Optimization (NPO), a simple alignment-inspired method that could efficiently and effectively unlearn a target dataset. We theoretically show that the progression toward catastrophic collapse by minimizing the NPO loss is exponentially slower than GA. Through experiments on synthetic data and the benchmark TOFU dataset, we demonstrate that NPO-based methods achieve a better balance between unlearning the undesirable data and maintaining the model's utilities. We also observe that NPO-based methods generate more sensible outputs than GA-based methods, whose outputs are often gibberish. Remarkably, on TOFU, NPO-based methods are the first to achieve reasonable unlearning results in forgetting 50% (or more) of the training data, whereas existing methods already struggle with forgetting 10% of training data.
Text2Data: Low-Resource Data Generation with Textual Control
Feb 08, 2024Natural language serves as a common and straightforward control signal for humans to interact seamlessly with machines. Recognizing the importance of this interface, the machine learning community is investing considerable effort in generating data that is semantically coherent with textual instructions. While strides have been made in text-to-data generation spanning image editing, audio synthesis, video creation, and beyond, low-resource areas characterized by expensive annotations or complex data structures, such as molecules, motion dynamics, and time series, often lack textual labels. This deficiency impedes supervised learning, thereby constraining the application of advanced generative models for text-to-data tasks. In response to these challenges in the low-resource scenario, we propose Text2Data, a novel approach that utilizes unlabeled data to understand the underlying data distribution through an unsupervised diffusion model. Subsequently, it undergoes controllable finetuning via a novel constraint optimization-based learning objective that ensures controllability and effectively counteracts catastrophic forgetting. Comprehensive experiments demonstrate that Text2Data is able to achieve enhanced performance regarding controllability across various modalities, including molecules, motions and time series, when compared to existing baselines.
Analyzing Task-Encoding Tokens in Large Language Models
Jan 20, 2024In-context learning (ICL) has become an effective solution for few-shot learning in natural language processing. Past work has found that, during this process, representations of the last prompt token are utilized to store task reasoning procedures, thereby explaining the working mechanism of in-context learning. In this paper, we seek to locate and analyze other task-encoding tokens whose representations store task reasoning procedures. Supported by experiments that ablate the representations of different token types, we find that template and stopword tokens are the most prone to be task-encoding tokens. In addition, we demonstrate experimentally that lexical cues, repetition, and text formats are the main distinguishing characteristics of these tokens. Our work provides additional insights into how large language models (LLMs) leverage task reasoning procedures in ICL and suggests that future work may involve using task-encoding tokens to improve the computational efficiency of LLMs at inference time and their ability to handle long sequences.
Is Inverse Reinforcement Learning Harder than Standard Reinforcement Learning?
Nov 29, 2023Inverse Reinforcement Learning (IRL) -- the problem of learning reward functions from demonstrations of an \emph{expert policy} -- plays a critical role in developing intelligent systems, such as those that understand and imitate human behavior. While widely used in applications, theoretical understandings of IRL admit unique challenges and remain less developed compared with standard RL theory. For example, it remains open how to do IRL efficiently in standard \emph{offline} settings with pre-collected data, where states are obtained from a \emph{behavior policy} (which could be the expert policy itself), and actions are sampled from the expert policy. This paper provides the first line of results for efficient IRL in vanilla offline and online settings using polynomial samples and runtime. We first design a new IRL algorithm for the offline setting, Reward Learning with Pessimism (RLP), and show that it achieves polynomial sample complexity in terms of the size of the MDP, a concentrability coefficient between the behavior policy and the expert policy, and the desired accuracy. Building on RLP, we further design an algorithm Reward Learning with Exploration (RLE), which operates in a natural online setting where the learner can both actively explore the environment and query the expert policy, and obtain a stronger notion of IRL guarantee from polynomial samples. We establish sample complexity lower bounds for both settings showing that RLP and RLE are nearly optimal. Finally, as an application, we show that the learned reward functions can \emph{transfer} to another target MDP with suitable guarantees when the target MDP satisfies certain similarity assumptions with the original (source) MDP.
How Do Transformers Learn In-Context Beyond Simple Functions? A Case Study on Learning with Representations
Oct 16, 2023While large language models based on the transformer architecture have demonstrated remarkable in-context learning (ICL) capabilities, understandings of such capabilities are still in an early stage, where existing theory and mechanistic understanding focus mostly on simple scenarios such as learning simple function classes. This paper takes initial steps on understanding ICL in more complex scenarios, by studying learning with representations. Concretely, we construct synthetic in-context learning problems with a compositional structure, where the label depends on the input through a possibly complex but fixed representation function, composed with a linear function that differs in each instance. By construction, the optimal ICL algorithm first transforms the inputs by the representation function, and then performs linear ICL on top of the transformed dataset. We show theoretically the existence of transformers that approximately implement such algorithms with mild depth and size. Empirically, we find trained transformers consistently achieve near-optimal ICL performance in this setting, and exhibit the desired dissection where lower layers transforms the dataset and upper layers perform linear ICL. Through extensive probing and a new pasting experiment, we further reveal several mechanisms within the trained transformers, such as concrete copying behaviors on both the inputs and the representations, linear ICL capability of the upper layers alone, and a post-ICL representation selection mechanism in a harder mixture setting. These observed mechanisms align well with our theory and may shed light on how transformers perform ICL in more realistic scenarios.
Transformers as Decision Makers: Provable In-Context Reinforcement Learning via Supervised Pretraining
Oct 12, 2023Large transformer models pretrained on offline reinforcement learning datasets have demonstrated remarkable in-context reinforcement learning (ICRL) capabilities, where they can make good decisions when prompted with interaction trajectories from unseen environments. However, when and how transformers can be trained to perform ICRL have not been theoretically well-understood. In particular, it is unclear which reinforcement-learning algorithms transformers can perform in context, and how distribution mismatch in offline training data affects the learned algorithms. This paper provides a theoretical framework that analyzes supervised pretraining for ICRL. This includes two recently proposed training methods -- algorithm distillation and decision-pretrained transformers. First, assuming model realizability, we prove the supervised-pretrained transformer will imitate the conditional expectation of the expert algorithm given the observed trajectory. The generalization error will scale with model capacity and a distribution divergence factor between the expert and offline algorithms. Second, we show transformers with ReLU attention can efficiently approximate near-optimal online reinforcement learning algorithms like LinUCB and Thompson sampling for stochastic linear bandits, and UCB-VI for tabular Markov decision processes. This provides the first quantitative analysis of the ICRL capabilities of transformers pretrained from offline trajectories.
An Empirical Study of NetOps Capability of Pre-Trained Large Language Models
Sep 19, 2023

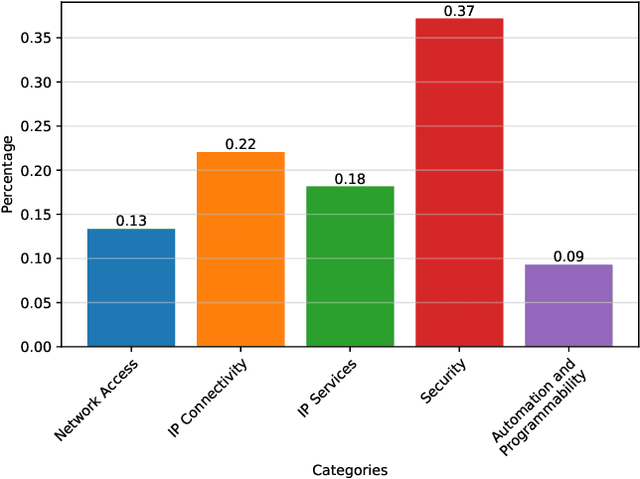
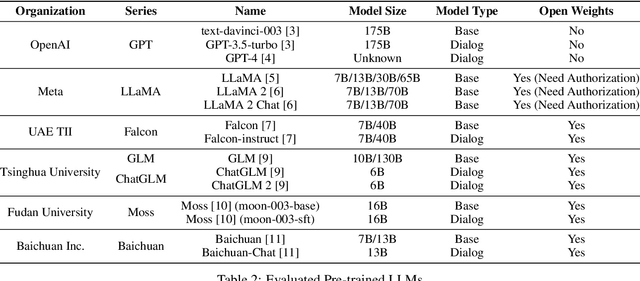
Nowadays, the versatile capabilities of Pre-trained Large Language Models (LLMs) have attracted much attention from the industry. However, some vertical domains are more interested in the in-domain capabilities of LLMs. For the Networks domain, we present NetEval, an evaluation set for measuring the comprehensive capabilities of LLMs in Network Operations (NetOps). NetEval is designed for evaluating the commonsense knowledge and inference ability in NetOps in a multi-lingual context. NetEval consists of 5,732 questions about NetOps, covering five different sub-domains of NetOps. With NetEval, we systematically evaluate the NetOps capability of 26 publicly available LLMs. The results show that only GPT-4 can achieve a performance competitive to humans. However, some open models like LLaMA 2 demonstrate significant potential.
What can a Single Attention Layer Learn? A Study Through the Random Features Lens
Jul 21, 2023
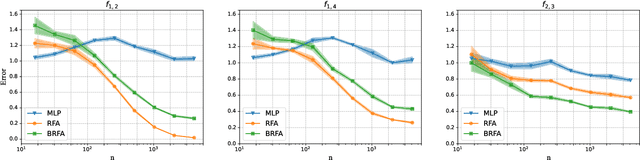
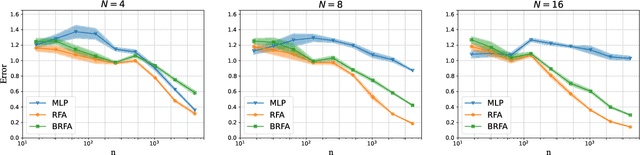
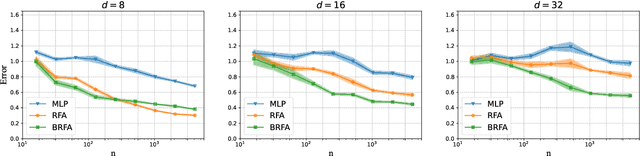
Attention layers -- which map a sequence of inputs to a sequence of outputs -- are core building blocks of the Transformer architecture which has achieved significant breakthroughs in modern artificial intelligence. This paper presents a rigorous theoretical study on the learning and generalization of a single multi-head attention layer, with a sequence of key vectors and a separate query vector as input. We consider the random feature setting where the attention layer has a large number of heads, with randomly sampled frozen query and key matrices, and trainable value matrices. We show that such a random-feature attention layer can express a broad class of target functions that are permutation invariant to the key vectors. We further provide quantitative excess risk bounds for learning these target functions from finite samples, using random feature attention with finitely many heads. Our results feature several implications unique to the attention structure compared with existing random features theory for neural networks, such as (1) Advantages in the sample complexity over standard two-layer random-feature networks; (2) Concrete and natural classes of functions that can be learned efficiently by a random-feature attention layer; and (3) The effect of the sampling distribution of the query-key weight matrix (the product of the query and key matrix), where Gaussian random weights with a non-zero mean result in better sample complexities over the zero-mean counterpart for learning certain natural target functions. Experiments on simulated data corroborate our theoretical findings and further illustrate the interplay between the sample size and the complexity of the target function.