 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYukai Miao
BClean: A Bayesian Data Cleaning System
Nov 11, 2023
There is a considerable body of work on data cleaning which employs various principles to rectify erroneous data and transform a dirty dataset into a cleaner one. One of prevalent approaches is probabilistic methods, including Bayesian methods. However, existing probabilistic methods often assume a simplistic distribution (e.g., Gaussian distribution), which is frequently underfitted in practice, or they necessitate experts to provide a complex prior distribution (e.g., via a programming language). This requirement is both labor-intensive and costly, rendering these methods less suitable for real-world applications. In this paper, we propose BClean, a Bayesian Cleaning system that features automatic Bayesian network construction and user interaction. We recast the data cleaning problem as a Bayesian inference that fully exploits the relationships between attributes in the observed dataset and any prior information provided by users. To this end, we present an automatic Bayesian network construction method that extends a structure learning-based functional dependency discovery method with similarity functions to capture the relationships between attributes. Furthermore, our system allows users to modify the generated Bayesian network in order to specify prior information or correct inaccuracies identified by the automatic generation process. We also design an effective scoring model (called the compensative scoring model) necessary for the Bayesian inference. To enhance the efficiency of data cleaning, we propose several approximation strategies for the Bayesian inference, including graph partitioning, domain pruning, and pre-detection. By evaluating on both real-world and synthetic datasets, we demonstrate that BClean is capable of achieving an F-measure of up to 0.9 in data cleaning, outperforming existing Bayesian methods by 2% and other data cleaning methods by 15%.
An Empirical Study of NetOps Capability of Pre-Trained Large Language Models
Sep 19, 2023

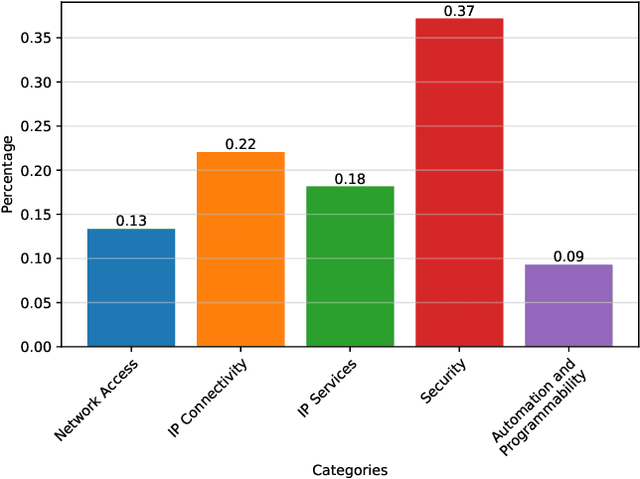
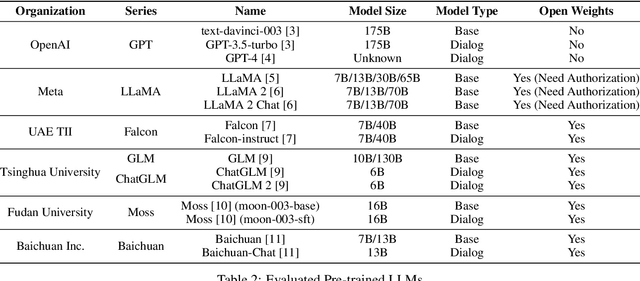
Nowadays, the versatile capabilities of Pre-trained Large Language Models (LLMs) have attracted much attention from the industry. However, some vertical domains are more interested in the in-domain capabilities of LLMs. For the Networks domain, we present NetEval, an evaluation set for measuring the comprehensive capabilities of LLMs in Network Operations (NetOps). NetEval is designed for evaluating the commonsense knowledge and inference ability in NetOps in a multi-lingual context. NetEval consists of 5,732 questions about NetOps, covering five different sub-domains of NetOps. With NetEval, we systematically evaluate the NetOps capability of 26 publicly available LLMs. The results show that only GPT-4 can achieve a performance competitive to humans. However, some open models like LLaMA 2 demonstrate significant potential.