 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJing Zhu
Index Modulation for Fluid Antenna-Assisted MIMO Communications: System Design and Performance Analysis
Dec 25, 2023
In this paper, we propose a transmission mechanism for fluid antennas (FAs) enabled multiple-input multiple-output (MIMO) communication systems based on index modulation (IM), named FA-IM, which incorporates the principle of IM into FAs-assisted MIMO system to improve the spectral efficiency (SE) without increasing the hardware complexity. In FA-IM, the information bits are mapped not only to the modulation symbols, but also the index of FA position patterns. Additionally, the FA position pattern codebook is carefully designed to further enhance the system performance by maximizing the effective channel gains. Then, a low-complexity detector, referred to efficient sparse Bayesian detector, is proposed by exploiting the inherent sparsity of the transmitted FA-IM signal vectors. Finally, a closed-form expression for the upper bound on the average bit error probability (ABEP) is derived under the finite-path and infinite-path channel condition. Simulation results show that the proposed scheme is capable of improving the SE performance compared to the existing FAs-assisted MIMO and the fixed position antennas (FPAs)-assisted MIMO systems while obviating any additional hardware costs. It has also been shown that the proposed scheme outperforms the conventional FA-assisted MIMO scheme in terms of error performance under the same transmission rate.
Design and Performance Analysis of Index Modulation Empowered AFDM System
Dec 02, 2023In this letter, we incorporate index modulation (IM) into affine frequency division multiplexing (AFDM), called AFDM-IM, to enhance the bit error rate (BER) and energy efficiency (EE) performance. In this scheme, the information bits are conveyed not only by $M$-ary constellation symbols, but also by the activation of the chirp subcarriers (SCs) indices, which are determined based on the incoming bit streams. Then, two power allocation strategies, namely power reallocation (PR) strategy and power saving (PS) strategy, are proposed to enhance BER and EE performance, respectively. Furthermore, the average bit error probability (ABEP) is theoretically analyzed. Simulation results demonstrate that the proposed AFDM-IM scheme achieves better BER performance than the conventional AFDM scheme.
BClean: A Bayesian Data Cleaning System
Nov 11, 2023There is a considerable body of work on data cleaning which employs various principles to rectify erroneous data and transform a dirty dataset into a cleaner one. One of prevalent approaches is probabilistic methods, including Bayesian methods. However, existing probabilistic methods often assume a simplistic distribution (e.g., Gaussian distribution), which is frequently underfitted in practice, or they necessitate experts to provide a complex prior distribution (e.g., via a programming language). This requirement is both labor-intensive and costly, rendering these methods less suitable for real-world applications. In this paper, we propose BClean, a Bayesian Cleaning system that features automatic Bayesian network construction and user interaction. We recast the data cleaning problem as a Bayesian inference that fully exploits the relationships between attributes in the observed dataset and any prior information provided by users. To this end, we present an automatic Bayesian network construction method that extends a structure learning-based functional dependency discovery method with similarity functions to capture the relationships between attributes. Furthermore, our system allows users to modify the generated Bayesian network in order to specify prior information or correct inaccuracies identified by the automatic generation process. We also design an effective scoring model (called the compensative scoring model) necessary for the Bayesian inference. To enhance the efficiency of data cleaning, we propose several approximation strategies for the Bayesian inference, including graph partitioning, domain pruning, and pre-detection. By evaluating on both real-world and synthetic datasets, we demonstrate that BClean is capable of achieving an F-measure of up to 0.9 in data cleaning, outperforming existing Bayesian methods by 2% and other data cleaning methods by 15%.
Spatial Attention-based Distribution Integration Network for Human Pose Estimation
Nov 09, 2023In recent years, human pose estimation has made significant progress through the implementation of deep learning techniques. However, these techniques still face limitations when confronted with challenging scenarios, including occlusion, diverse appearances, variations in illumination, and overlap. To cope with such drawbacks, we present the Spatial Attention-based Distribution Integration Network (SADI-NET) to improve the accuracy of localization in such situations. Our network consists of three efficient models: the receptive fortified module (RFM), spatial fusion module (SFM), and distribution learning module (DLM). Building upon the classic HourglassNet architecture, we replace the basic block with our proposed RFM. The RFM incorporates a dilated residual block and attention mechanism to expand receptive fields while enhancing sensitivity to spatial information. In addition, the SFM incorporates multi-scale characteristics by employing both global and local attention mechanisms. Furthermore, the DLM, inspired by residual log-likelihood estimation (RLE), reconfigures a predicted heatmap using a trainable distribution weight. For the purpose of determining the efficacy of our model, we conducted extensive experiments on the MPII and LSP benchmarks. Particularly, our model obtained a remarkable $92.10\%$ percent accuracy on the MPII test dataset, demonstrating significant improvements over existing models and establishing state-of-the-art performance.
TouchUp-G: Improving Feature Representation through Graph-Centric Finetuning
Sep 25, 2023How can we enhance the node features acquired from Pretrained Models (PMs) to better suit downstream graph learning tasks? Graph Neural Networks (GNNs) have become the state-of-the-art approach for many high-impact, real-world graph applications. For feature-rich graphs, a prevalent practice involves utilizing a PM directly to generate features, without incorporating any domain adaptation techniques. Nevertheless, this practice is suboptimal because the node features extracted from PM are graph-agnostic and prevent GNNs from fully utilizing the potential correlations between the graph structure and node features, leading to a decline in GNNs performance. In this work, we seek to improve the node features obtained from a PM for downstream graph tasks and introduce TOUCHUP-G, which has several advantages. It is (a) General: applicable to any downstream graph task, including link prediction which is often employed in recommender systems; (b) Multi-modal: able to improve raw features of any modality (e.g. images, texts, audio); (c) Principled: it is closely related to a novel metric, feature homophily, which we propose to quantify the potential correlations between the graph structure and node features and we show that TOUCHUP-G can effectively shrink the discrepancy between the graph structure and node features; (d) Effective: achieving state-of-the-art results on four real-world datasets spanning different tasks and modalities.
Full-resolution Lung Nodule Segmentation from Chest X-ray Images using Residual Encoder-Decoder Networks
Jul 13, 2023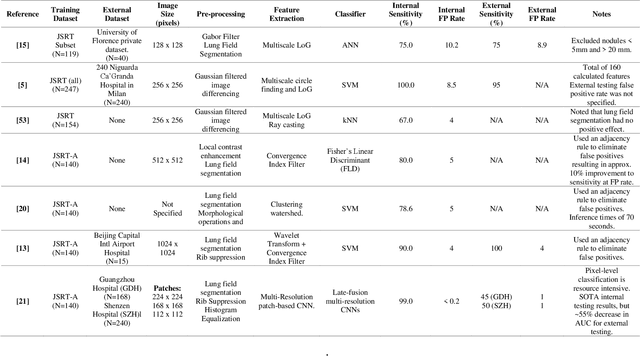
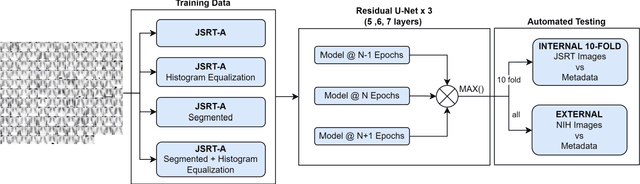
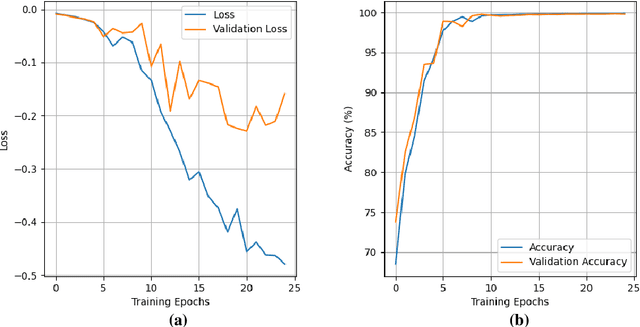

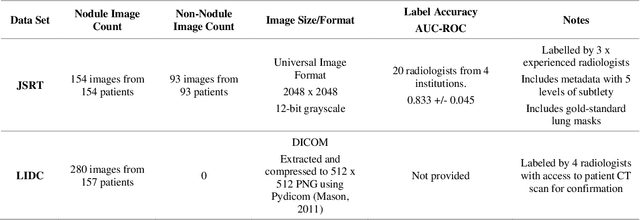
Lung cancer is the leading cause of cancer death and early diagnosis is associated with a positive prognosis. Chest X-ray (CXR) provides an inexpensive imaging mode for lung cancer diagnosis. Suspicious nodules are difficult to distinguish from vascular and bone structures using CXR. Computer vision has previously been proposed to assist human radiologists in this task, however, leading studies use down-sampled images and computationally expensive methods with unproven generalization. Instead, this study localizes lung nodules using efficient encoder-decoder neural networks that process full resolution images to avoid any signal loss resulting from down-sampling. Encoder-decoder networks are trained and tested using the JSRT lung nodule dataset. The networks are used to localize lung nodules from an independent external CXR dataset. Sensitivity and false positive rates are measured using an automated framework to eliminate any observer subjectivity. These experiments allow for the determination of the optimal network depth, image resolution and pre-processing pipeline for generalized lung nodule localization. We find that nodule localization is influenced by subtlety, with more subtle nodules being detected in earlier training epochs. Therefore, we propose a novel self-ensemble model from three consecutive epochs centered on the validation optimum. This ensemble achieved a sensitivity of 85% in 10-fold internal testing with false positives of 8 per image. A sensitivity of 81% is achieved at a false positive rate of 6 following morphological false positive reduction. This result is comparable to more computationally complex systems based on linear and spatial filtering, but with a sub-second inference time that is faster than other methods. The proposed algorithm achieved excellent generalization results against an external dataset with sensitivity of 77% at a false positive rate of 7.6.
SpotTarget: Rethinking the Effect of Target Edges for Link Prediction in Graph Neural Networks
Jun 01, 2023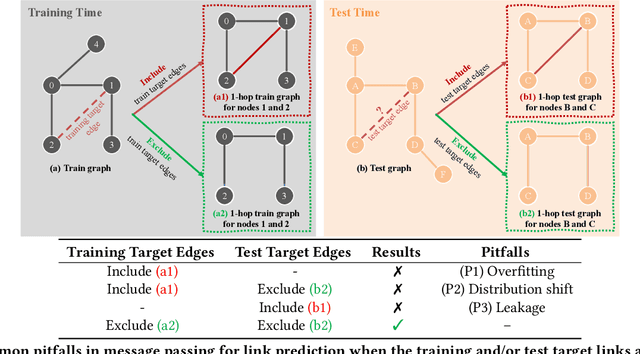

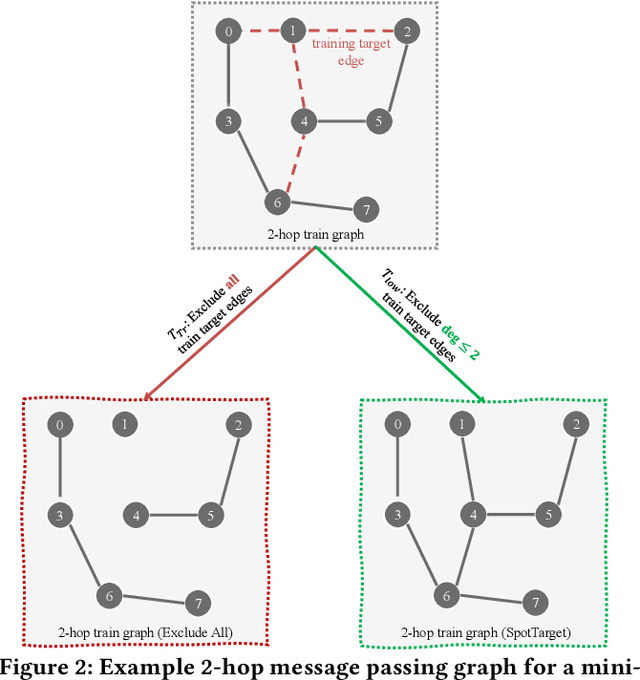
Graph Neural Networks (GNNs) have demonstrated promising outcomes across various tasks, including node classification and link prediction. Despite their remarkable success in various high-impact applications, we have identified three common pitfalls in message passing for link prediction. Particularly, in prevalent GNN frameworks (e.g., DGL and PyTorch-Geometric), the target edges (i.e., the edges being predicted) consistently exist as message passing edges in the graph during training. Consequently, this results in overfitting and distribution shift, both of which adversely impact the generalizability to test the target edges. Additionally, during test time, the failure to exclude the test target edges leads to implicit test leakage caused by neighborhood aggregation. In this paper, we analyze these three pitfalls and investigate the impact of including or excluding target edges on the performance of nodes with varying degrees during training and test phases. Our theoretical and empirical analysis demonstrates that low-degree nodes are more susceptible to these pitfalls. These pitfalls can have detrimental consequences when GNNs are implemented in production systems. To systematically address these pitfalls, we propose SpotTarget, an effective and efficient GNN training framework. During training, SpotTarget leverages our insight regarding low-degree nodes and excludes train target edges connected to at least one low-degree node. During test time, it emulates real-world scenarios of GNN usage in production and excludes all test target edges. Our experiments conducted on diverse real-world datasets, demonstrate that SpotTarget significantly enhances GNNs, achieving up to a 15x increase in accuracy in sparse graphs. Furthermore, SpotTarget consistently and dramatically improves the performance for low-degree nodes in dense graphs.
Touch and Go: Learning from Human-Collected Vision and Touch
Nov 29, 2022

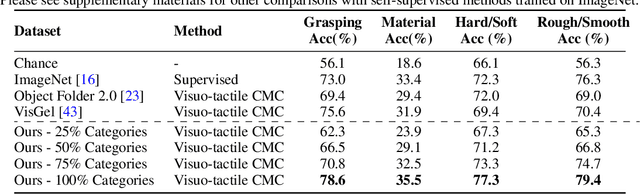

The ability to associate touch with sight is essential for tasks that require physically interacting with objects in the world. We propose a dataset with paired visual and tactile data called Touch and Go, in which human data collectors probe objects in natural environments using tactile sensors, while simultaneously recording egocentric video. In contrast to previous efforts, which have largely been confined to lab settings or simulated environments, our dataset spans a large number of "in the wild" objects and scenes. To demonstrate our dataset's effectiveness, we successfully apply it to a variety of tasks: 1) self-supervised visuo-tactile feature learning, 2) tactile-driven image stylization, i.e., making the visual appearance of an object more consistent with a given tactile signal, and 3) predicting future frames of a tactile signal from visuo-tactile inputs.
CAPER: Coarsen, Align, Project, Refine - A General Multilevel Framework for Network Alignment
Aug 23, 2022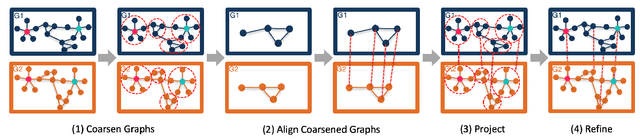

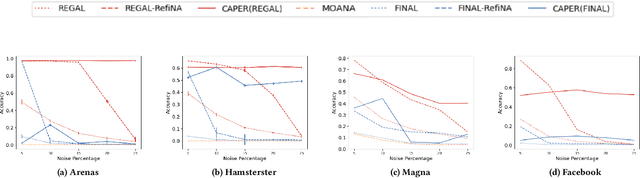
Network alignment, or the task of finding corresponding nodes in different networks, is an important problem formulation in many application domains. We propose CAPER, a multilevel alignment framework that Coarsens the input graphs, Aligns the coarsened graphs, Projects the alignment solution to finer levels and Refines the alignment solution. We show that CAPER can improve upon many different existing network alignment algorithms by enforcing alignment consistency across multiple graph resolutions: nodes matched at finer levels should also be matched at coarser levels. CAPER also accelerates the use of slower network alignment methods, at the modest cost of linear-time coarsening and refinement steps, by allowing them to be run on smaller coarsened versions of the input graphs. Experiments show that CAPER can improve upon diverse network alignment methods by an average of 33% in accuracy and/or an order of magnitude faster in runtime.
Debiasing pipeline improves deep learning model generalization for X-ray based lung nodule detection
Jan 24, 2022


Lung cancer is the leading cause of cancer death worldwide and a good prognosis depends on early diagnosis. Unfortunately, screening programs for the early diagnosis of lung cancer are uncommon. This is in-part due to the at-risk groups being located in rural areas far from medical facilities. Reaching these populations would require a scaled approach that combines mobility, low cost, speed, accuracy, and privacy. We can resolve these issues by combining the chest X-ray imaging mode with a federated deep-learning approach, provided that the federated model is trained on homogenous data to ensure that no single data source can adversely bias the model at any point in time. In this study we show that an image pre-processing pipeline that homogenizes and debiases chest X-ray images can improve both internal classification and external generalization, paving the way for a low-cost and accessible deep learning-based clinical system for lung cancer screening. An evolutionary pruning mechanism is used to train a nodule detection deep learning model on the most informative images from a publicly available lung nodule X-ray dataset. Histogram equalization is used to remove systematic differences in image brightness and contrast. Model training is performed using all combinations of lung field segmentation, close cropping, and rib suppression operators. We show that this pre-processing pipeline results in deep learning models that successfully generalize an independent lung nodule dataset using ablation studies to assess the contribution of each operator in this pipeline. In stripping chest X-ray images of known confounding variables by lung field segmentation, along with suppression of signal noise from the bone structure we can train a highly accurate deep learning lung nodule detection algorithm with outstanding generalization accuracy of 89% to nodule samples in unseen data.