 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYun Fu
Consistency and Uncertainty: Identifying Unreliable Responses From Black-Box Vision-Language Models for Selective Visual Question Answering
Apr 16, 2024
The goal of selective prediction is to allow an a model to abstain when it may not be able to deliver a reliable prediction, which is important in safety-critical contexts. Existing approaches to selective prediction typically require access to the internals of a model, require retraining a model or study only unimodal models. However, the most powerful models (e.g. GPT-4) are typically only available as black boxes with inaccessible internals, are not retrainable by end-users, and are frequently used for multimodal tasks. We study the possibility of selective prediction for vision-language models in a realistic, black-box setting. We propose using the principle of \textit{neighborhood consistency} to identify unreliable responses from a black-box vision-language model in question answering tasks. We hypothesize that given only a visual question and model response, the consistency of the model's responses over the neighborhood of a visual question will indicate reliability. It is impossible to directly sample neighbors in feature space in a black-box setting. Instead, we show that it is possible to use a smaller proxy model to approximately sample from the neighborhood. We find that neighborhood consistency can be used to identify model responses to visual questions that are likely unreliable, even in adversarial settings or settings that are out-of-distribution to the proxy model.
Self-Training Large Language Models for Improved Visual Program Synthesis With Visual Reinforcement
Apr 06, 2024Visual program synthesis is a promising approach to exploit the reasoning abilities of large language models for compositional computer vision tasks. Previous work has used few-shot prompting with frozen LLMs to synthesize visual programs. Training an LLM to write better visual programs is an attractive prospect, but it is unclear how to accomplish this. No dataset of visual programs for training exists, and acquisition of a visual program dataset cannot be easily crowdsourced due to the need for expert annotators. To get around the lack of direct supervision, we explore improving the program synthesis abilities of an LLM using feedback from interactive experience. We propose a method where we exploit existing annotations for a vision-language task to improvise a coarse reward signal for that task, treat the LLM as a policy, and apply reinforced self-training to improve the visual program synthesis ability of the LLM for that task. We describe a series of experiments on object detection, compositional visual question answering, and image-text retrieval, and show that in each case, the self-trained LLM outperforms or performs on par with few-shot frozen LLMs that are an order of magnitude larger. Website: https://zaidkhan.me/ViReP
OOSTraj: Out-of-Sight Trajectory Prediction With Vision-Positioning Denoising
Apr 02, 2024Trajectory prediction is fundamental in computer vision and autonomous driving, particularly for understanding pedestrian behavior and enabling proactive decision-making. Existing approaches in this field often assume precise and complete observational data, neglecting the challenges associated with out-of-view objects and the noise inherent in sensor data due to limited camera range, physical obstructions, and the absence of ground truth for denoised sensor data. Such oversights are critical safety concerns, as they can result in missing essential, non-visible objects. To bridge this gap, we present a novel method for out-of-sight trajectory prediction that leverages a vision-positioning technique. Our approach denoises noisy sensor observations in an unsupervised manner and precisely maps sensor-based trajectories of out-of-sight objects into visual trajectories. This method has demonstrated state-of-the-art performance in out-of-sight noisy sensor trajectory denoising and prediction on the Vi-Fi and JRDB datasets. By enhancing trajectory prediction accuracy and addressing the challenges of out-of-sight objects, our work significantly contributes to improving the safety and reliability of autonomous driving in complex environments. Our work represents the first initiative towards Out-Of-Sight Trajectory prediction (OOSTraj), setting a new benchmark for future research. The code is available at \url{https://github.com/Hai-chao-Zhang/OOSTraj}.
Adapting to Length Shift: FlexiLength Network for Trajectory Prediction
Mar 31, 2024Trajectory prediction plays an important role in various applications, including autonomous driving, robotics, and scene understanding. Existing approaches mainly focus on developing compact neural networks to increase prediction precision on public datasets, typically employing a standardized input duration. However, a notable issue arises when these models are evaluated with varying observation lengths, leading to a significant performance drop, a phenomenon we term the Observation Length Shift. To address this issue, we introduce a general and effective framework, the FlexiLength Network (FLN), to enhance the robustness of existing trajectory prediction techniques against varying observation periods. Specifically, FLN integrates trajectory data with diverse observation lengths, incorporates FlexiLength Calibration (FLC) to acquire temporal invariant representations, and employs FlexiLength Adaptation (FLA) to further refine these representations for more accurate future trajectory predictions. Comprehensive experiments on multiple datasets, ie, ETH/UCY, nuScenes, and Argoverse 1, demonstrate the effectiveness and flexibility of our proposed FLN framework.
Rewrite the Stars
Mar 29, 2024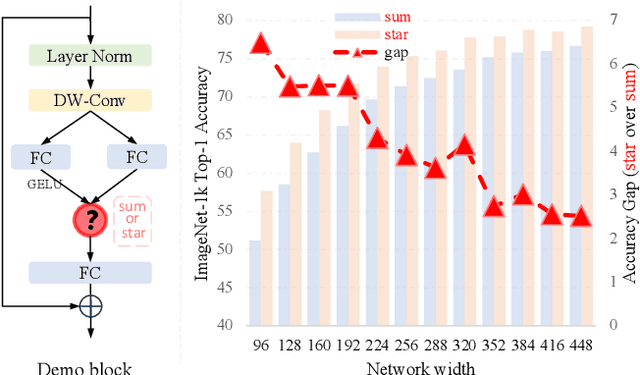
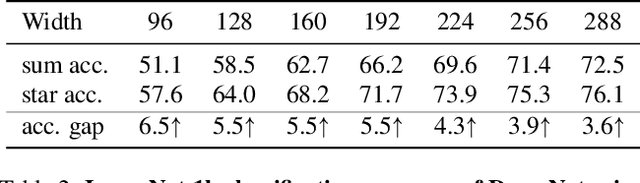
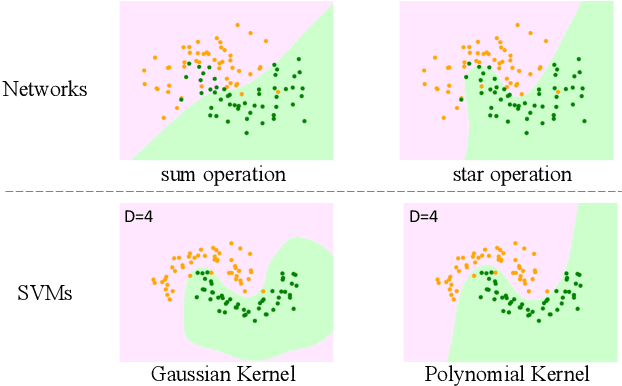
Recent studies have drawn attention to the untapped potential of the "star operation" (element-wise multiplication) in network design. While intuitive explanations abound, the foundational rationale behind its application remains largely unexplored. Our study attempts to reveal the star operation's ability to map inputs into high-dimensional, non-linear feature spaces -- akin to kernel tricks -- without widening the network. We further introduce StarNet, a simple yet powerful prototype, demonstrating impressive performance and low latency under compact network structure and efficient budget. Like stars in the sky, the star operation appears unremarkable but holds a vast universe of potential. Our work encourages further exploration across tasks, with codes available at https://github.com/ma-xu/Rewrite-the-Stars.
Efficient Modulation for Vision Networks
Mar 29, 2024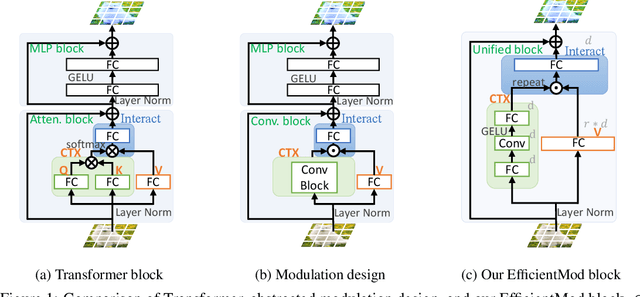
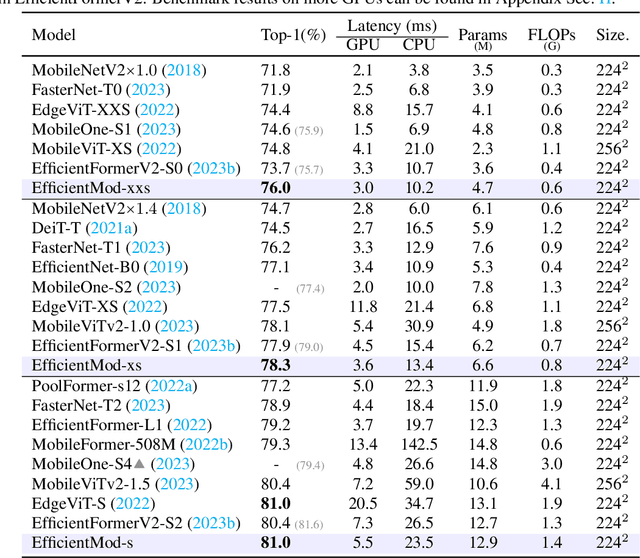
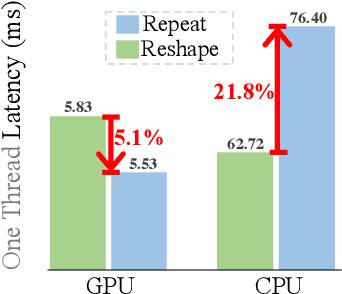
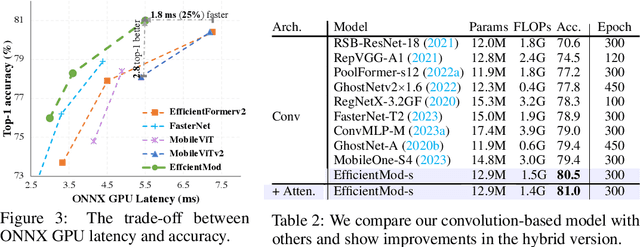
In this work, we present efficient modulation, a novel design for efficient vision networks. We revisit the modulation mechanism, which operates input through convolutional context modeling and feature projection layers, and fuses features via element-wise multiplication and an MLP block. We demonstrate that the modulation mechanism is particularly well suited for efficient networks and further tailor the modulation design by proposing the efficient modulation (EfficientMod) block, which is considered the essential building block for our networks. Benefiting from the prominent representational ability of modulation mechanism and the proposed efficient design, our network can accomplish better trade-offs between accuracy and efficiency and set new state-of-the-art performance in the zoo of efficient networks. When integrating EfficientMod with the vanilla self-attention block, we obtain the hybrid architecture which further improves the performance without loss of efficiency. We carry out comprehensive experiments to verify EfficientMod's performance. With fewer parameters, our EfficientMod-s performs 0.6 top-1 accuracy better than EfficientFormerV2-s2 and is 25% faster on GPU, and 2.9 better than MobileViTv2-1.0 at the same GPU latency. Additionally, our method presents a notable improvement in downstream tasks, outperforming EfficientFormerV2-s by 3.6 mIoU on the ADE20K benchmark. Code and checkpoints are available at https://github.com/ma-xu/EfficientMod.
Don't Judge by the Look: Towards Motion Coherent Video Representation
Mar 25, 2024

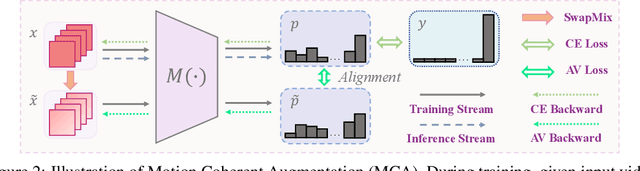

Current training pipelines in object recognition neglect Hue Jittering when doing data augmentation as it not only brings appearance changes that are detrimental to classification, but also the implementation is inefficient in practice. In this study, we investigate the effect of hue variance in the context of video understanding and find this variance to be beneficial since static appearances are less important in videos that contain motion information. Based on this observation, we propose a data augmentation method for video understanding, named Motion Coherent Augmentation (MCA), that introduces appearance variation in videos and implicitly encourages the model to prioritize motion patterns, rather than static appearances. Concretely, we propose an operation SwapMix to efficiently modify the appearance of video samples, and introduce Variation Alignment (VA) to resolve the distribution shift caused by SwapMix, enforcing the model to learn appearance invariant representations. Comprehensive empirical evaluation across various architectures and different datasets solidly validates the effectiveness and generalization ability of MCA, and the application of VA in other augmentation methods. Code is available at https://github.com/BeSpontaneous/MCA-pytorch.
Don't Judge by the Look: A Motion Coherent Augmentation for Video Recognition
Mar 14, 2024Current training pipelines in object recognition neglect Hue Jittering when doing data augmentation as it not only brings appearance changes that are detrimental to classification, but also the implementation is inefficient in practice. In this study, we investigate the effect of hue variance in the context of video recognition and find this variance to be beneficial since static appearances are less important in videos that contain motion information. Based on this observation, we propose a data augmentation method for video recognition, named Motion Coherent Augmentation (MCA), that introduces appearance variation in videos and implicitly encourages the model to prioritize motion patterns, rather than static appearances. Concretely, we propose an operation SwapMix to efficiently modify the appearance of video samples, and introduce Variation Alignment (VA) to resolve the distribution shift caused by SwapMix, enforcing the model to learn appearance invariant representations. Comprehensive empirical evaluation across various architectures and different datasets solidly validates the effectiveness and generalization ability of MCA, and the application of VA in other augmentation methods. Code is available at https://github.com/BeSpontaneous/MCA-pytorch.
VaQuitA: Enhancing Alignment in LLM-Assisted Video Understanding
Dec 04, 2023Recent advancements in language-model-based video understanding have been progressing at a remarkable pace, spurred by the introduction of Large Language Models (LLMs). However, the focus of prior research has been predominantly on devising a projection layer that maps video features to tokens, an approach that is both rudimentary and inefficient. In our study, we introduce a cutting-edge framework, VaQuitA, designed to refine the synergy between video and textual information. At the data level, instead of sampling frames uniformly, we implement a sampling method guided by CLIP-score rankings, which enables a more aligned selection of frames with the given question. At the feature level, we integrate a trainable Video Perceiver alongside a Visual-Query Transformer (abbreviated as VQ-Former), which bolsters the interplay between the input question and the video features. We also discover that incorporating a simple prompt, "Please be critical", into the LLM input can substantially enhance its video comprehension capabilities. Our experimental results indicate that VaQuitA consistently sets a new benchmark for zero-shot video question-answering tasks and is adept at producing high-quality, multi-turn video dialogues with users.
Exploring Question Decomposition for Zero-Shot VQA
Oct 25, 2023Visual question answering (VQA) has traditionally been treated as a single-step task where each question receives the same amount of effort, unlike natural human question-answering strategies. We explore a question decomposition strategy for VQA to overcome this limitation. We probe the ability of recently developed large vision-language models to use human-written decompositions and produce their own decompositions of visual questions, finding they are capable of learning both tasks from demonstrations alone. However, we show that naive application of model-written decompositions can hurt performance. We introduce a model-driven selective decomposition approach for second-guessing predictions and correcting errors, and validate its effectiveness on eight VQA tasks across three domains, showing consistent improvements in accuracy, including improvements of >20% on medical VQA datasets and boosting the zero-shot performance of BLIP-2 above chance on a VQA reformulation of the challenging Winoground task. Project Site: https://zaidkhan.me/decomposition-0shot-vqa/