 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaichao Zhang
OOSTraj: Out-of-Sight Trajectory Prediction With Vision-Positioning Denoising
Apr 02, 2024
Trajectory prediction is fundamental in computer vision and autonomous driving, particularly for understanding pedestrian behavior and enabling proactive decision-making. Existing approaches in this field often assume precise and complete observational data, neglecting the challenges associated with out-of-view objects and the noise inherent in sensor data due to limited camera range, physical obstructions, and the absence of ground truth for denoised sensor data. Such oversights are critical safety concerns, as they can result in missing essential, non-visible objects. To bridge this gap, we present a novel method for out-of-sight trajectory prediction that leverages a vision-positioning technique. Our approach denoises noisy sensor observations in an unsupervised manner and precisely maps sensor-based trajectories of out-of-sight objects into visual trajectories. This method has demonstrated state-of-the-art performance in out-of-sight noisy sensor trajectory denoising and prediction on the Vi-Fi and JRDB datasets. By enhancing trajectory prediction accuracy and addressing the challenges of out-of-sight objects, our work significantly contributes to improving the safety and reliability of autonomous driving in complex environments. Our work represents the first initiative towards Out-Of-Sight Trajectory prediction (OOSTraj), setting a new benchmark for future research. The code is available at \url{https://github.com/Hai-chao-Zhang/OOSTraj}.
Layout Sequence Prediction From Noisy Mobile Modality
Oct 09, 2023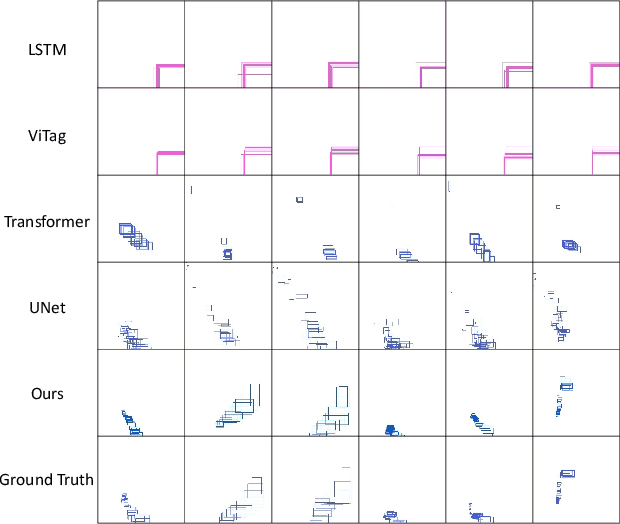
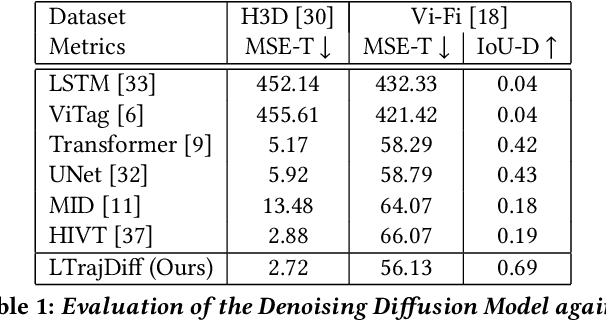
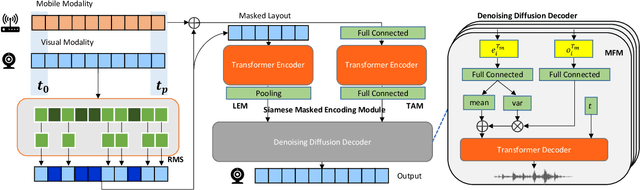
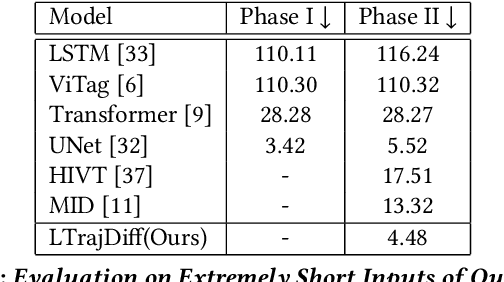
Trajectory prediction plays a vital role in understanding pedestrian movement for applications such as autonomous driving and robotics. Current trajectory prediction models depend on long, complete, and accurately observed sequences from visual modalities. Nevertheless, real-world situations often involve obstructed cameras, missed objects, or objects out of sight due to environmental factors, leading to incomplete or noisy trajectories. To overcome these limitations, we propose LTrajDiff, a novel approach that treats objects obstructed or out of sight as equally important as those with fully visible trajectories. LTrajDiff utilizes sensor data from mobile phones to surmount out-of-sight constraints, albeit introducing new challenges such as modality fusion, noisy data, and the absence of spatial layout and object size information. We employ a denoising diffusion model to predict precise layout sequences from noisy mobile data using a coarse-to-fine diffusion strategy, incorporating the RMS, Siamese Masked Encoding Module, and MFM. Our model predicts layout sequences by implicitly inferring object size and projection status from a single reference timestamp or significantly obstructed sequences. Achieving SOTA results in randomly obstructed experiments and extremely short input experiments, our model illustrates the effectiveness of leveraging noisy mobile data. In summary, our approach offers a promising solution to the challenges faced by layout sequence and trajectory prediction models in real-world settings, paving the way for utilizing sensor data from mobile phones to accurately predict pedestrian bounding box trajectories. To the best of our knowledge, this is the first work that addresses severely obstructed and extremely short layout sequences by combining vision with noisy mobile modality, making it the pioneering work in the field of layout sequence trajectory prediction.
Camouflaged Image Synthesis Is All You Need to Boost Camouflaged Detection
Aug 13, 2023
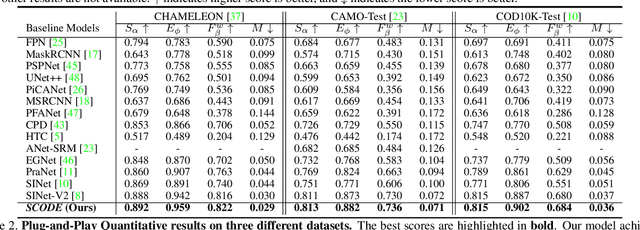

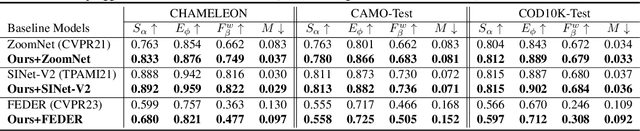
Camouflaged objects that blend into natural scenes pose significant challenges for deep-learning models to detect and synthesize. While camouflaged object detection is a crucial task in computer vision with diverse real-world applications, this research topic has been constrained by limited data availability. We propose a framework for synthesizing camouflage data to enhance the detection of camouflaged objects in natural scenes. Our approach employs a generative model to produce realistic camouflage images, which can be used to train existing object detection models. Specifically, we use a camouflage environment generator supervised by a camouflage distribution classifier to synthesize the camouflage images, which are then fed into our generator to expand the dataset. Our framework outperforms the current state-of-the-art method on three datasets (COD10k, CAMO, and CHAMELEON), demonstrating its effectiveness in improving camouflaged object detection. This approach can serve as a plug-and-play data generation and augmentation module for existing camouflaged object detection tasks and provides a novel way to introduce more diversity and distributions into current camouflage datasets.
Imitation with Spatial-Temporal Heatmap: 2nd Place Solution for NuPlan Challenge
Jun 26, 2023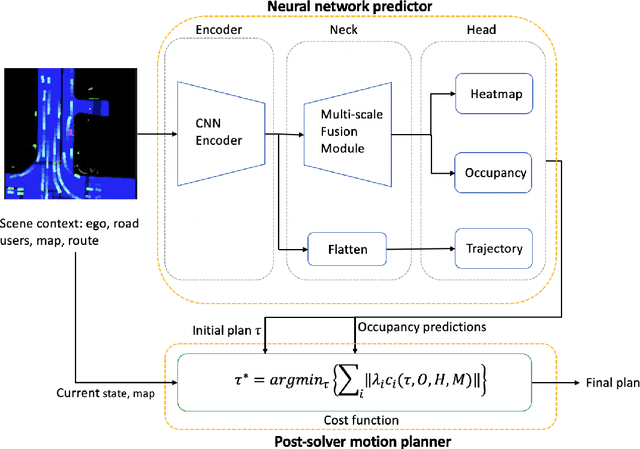



This paper presents our 2nd place solution for the NuPlan Challenge 2023. Autonomous driving in real-world scenarios is highly complex and uncertain. Achieving safe planning in the complex multimodal scenarios is a highly challenging task. Our approach, Imitation with Spatial-Temporal Heatmap, adopts the learning form of behavior cloning, innovatively predicts the future multimodal states with a heatmap representation, and uses trajectory refinement techniques to ensure final safety. The experiment shows that our method effectively balances the vehicle's progress and safety, generating safe and comfortable trajectories. In the NuPlan competition, we achieved the second highest overall score, while obtained the best scores in the ego progress and comfort metrics.
Efficient Multi-Task and Transfer Reinforcement Learning with Parameter-Compositional Framework
Jun 02, 2023
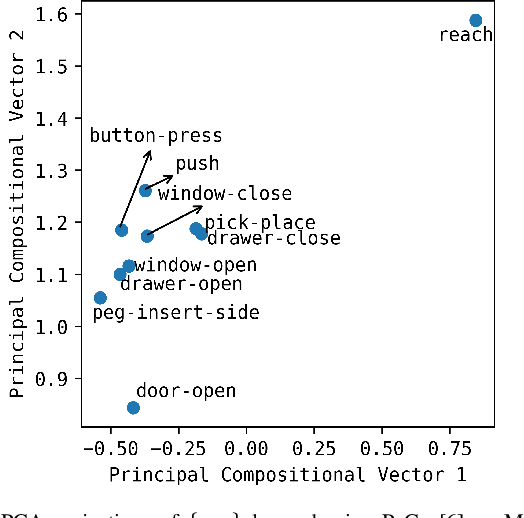
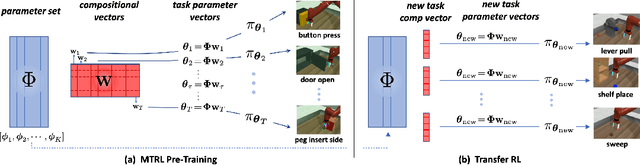
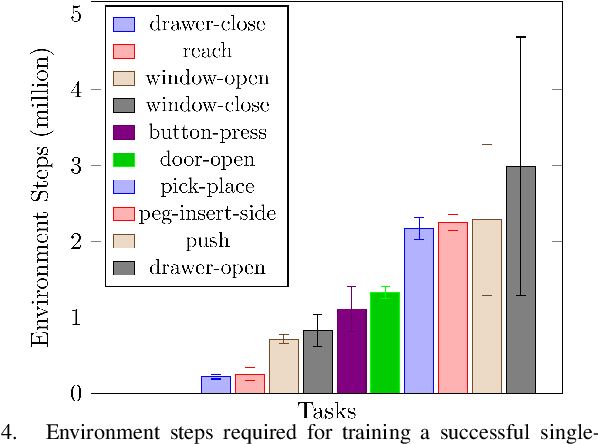
In this work, we investigate the potential of improving multi-task training and also leveraging it for transferring in the reinforcement learning setting. We identify several challenges towards this goal and propose a transferring approach with a parameter-compositional formulation. We investigate ways to improve the training of multi-task reinforcement learning which serves as the foundation for transferring. Then we conduct a number of transferring experiments on various manipulation tasks. Experimental results demonstrate that the proposed approach can have improved performance in the multi-task training stage, and further show effective transferring in terms of both sample efficiency and performance.
Policy Expansion for Bridging Offline-to-Online Reinforcement Learning
Feb 02, 2023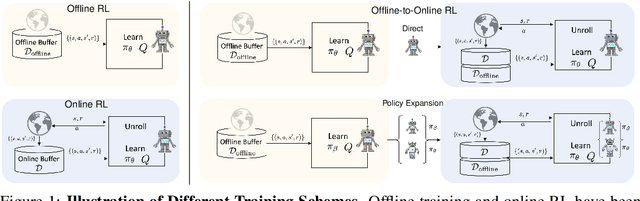
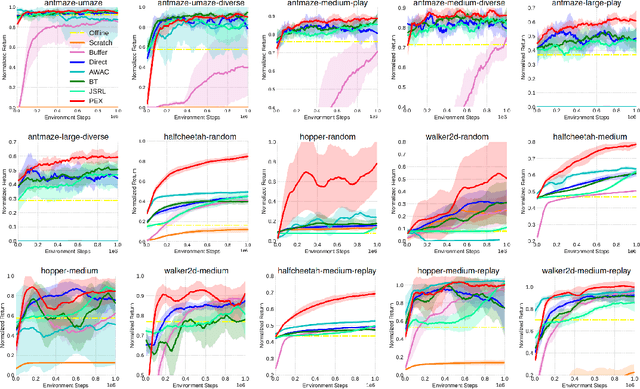
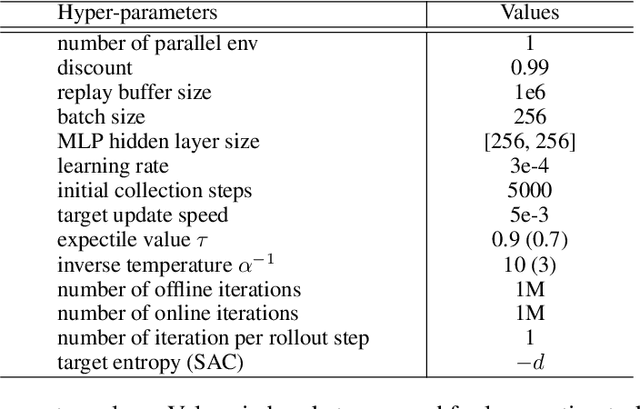
Pre-training with offline data and online fine-tuning using reinforcement learning is a promising strategy for learning control policies by leveraging the best of both worlds in terms of sample efficiency and performance. One natural approach is to initialize the policy for online learning with the one trained offline. In this work, we introduce a policy expansion scheme for this task. After learning the offline policy, we use it as one candidate policy in a policy set. We then expand the policy set with another policy which will be responsible for further learning. The two policies will be composed in an adaptive manner for interacting with the environment. With this approach, the policy previously learned offline is fully retained during online learning, thus mitigating the potential issues such as destroying the useful behaviors of the offline policy in the initial stage of online learning while allowing the offline policy participate in the exploration naturally in an adaptive manner. Moreover, new useful behaviors can potentially be captured by the newly added policy through learning. Experiments are conducted on a number of tasks and the results demonstrate the effectiveness of the proposed approach.
Multi-Objective Evolutionary for Object Detection Mobile Architectures Search
Nov 05, 2022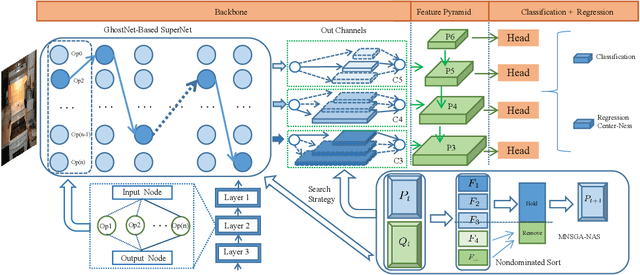
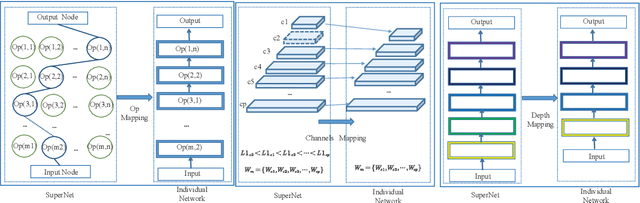
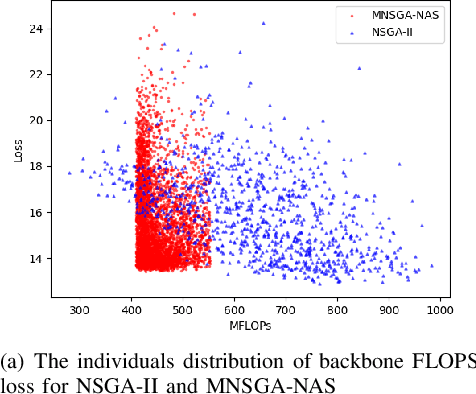

Recently, Neural architecture search has achieved great success on classification tasks for mobile devices. The backbone network for object detection is usually obtained on the image classification task. However, the architecture which is searched through the classification task is sub-optimal because of the gap between the task of image and object detection. As while work focuses on backbone network architecture search for mobile device object detection is limited, mainly because the backbone always requires expensive ImageNet pre-training. Accordingly, it is necessary to study the approach of network architecture search for mobile device object detection without expensive pre-training. In this work, we propose a mobile object detection backbone network architecture search algorithm which is a kind of evolutionary optimized method based on non-dominated sorting for NAS scenarios. It can quickly search to obtain the backbone network architecture within certain constraints. It better solves the problem of suboptimal linear combination accuracy and computational cost. The proposed approach can search the backbone networks with different depths, widths, or expansion sizes via a technique of weight mapping, making it possible to use NAS for mobile devices detection tasks a lot more efficiently. In our experiments, we verify the effectiveness of the proposed approach on YoloX-Lite, a lightweight version of the target detection framework. Under similar computational complexity, the accuracy of the backbone network architecture we search for is 2.0% mAP higher than MobileDet. Our improved backbone network can reduce the computational effort while improving the accuracy of the object detection network. To prove its effectiveness, a series of ablation studies have been carried out and the working mechanism has been analyzed in detail.
Vision Transformer with Convolutions Architecture Search
Mar 20, 2022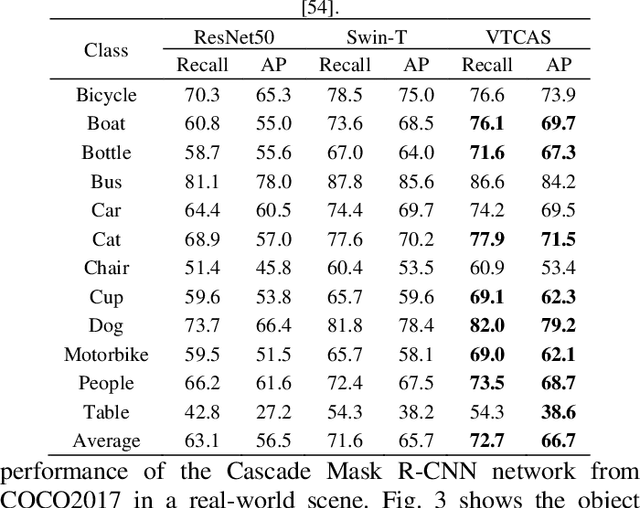

Transformers exhibit great advantages in handling computer vision tasks. They model image classification tasks by utilizing a multi-head attention mechanism to process a series of patches consisting of split images. However, for complex tasks, Transformer in computer vision not only requires inheriting a bit of dynamic attention and global context, but also needs to introduce features concerning noise reduction, shifting, and scaling invariance of objects. Therefore, here we take a step forward to study the structural characteristics of Transformer and convolution and propose an architecture search method-Vision Transformer with Convolutions Architecture Search (VTCAS). The high-performance backbone network searched by VTCAS introduces the desirable features of convolutional neural networks into the Transformer architecture while maintaining the benefits of the multi-head attention mechanism. The searched block-based backbone network can extract feature maps at different scales. These features are compatible with a wider range of visual tasks, such as image classification (32 M parameters, 82.0% Top-1 accuracy on ImageNet-1K) and object detection (50.4% mAP on COCO2017). The proposed topology based on the multi-head attention mechanism and CNN adaptively associates relational features of pixels with multi-scale features of objects. It enhances the robustness of the neural network for object recognition, especially in the low illumination indoor scene.
Generative Planning for Temporally Coordinated Exploration in Reinforcement Learning
Feb 03, 2022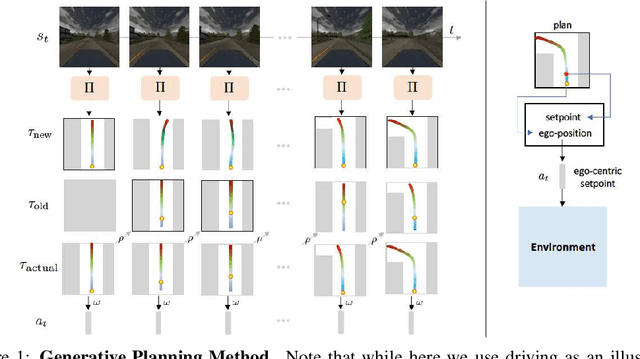

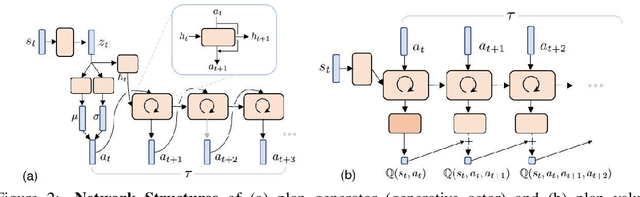
Standard model-free reinforcement learning algorithms optimize a policy that generates the action to be taken in the current time step in order to maximize expected future return. While flexible, it faces difficulties arising from the inefficient exploration due to its single step nature. In this work, we present Generative Planning method (GPM), which can generate actions not only for the current step, but also for a number of future steps (thus termed as generative planning). This brings several benefits to GPM. Firstly, since GPM is trained by maximizing value, the plans generated from it can be regarded as intentional action sequences for reaching high value regions. GPM can therefore leverage its generated multi-step plans for temporally coordinated exploration towards high value regions, which is potentially more effective than a sequence of actions generated by perturbing each action at single step level, whose consistent movement decays exponentially with the number of exploration steps. Secondly, starting from a crude initial plan generator, GPM can refine it to be adaptive to the task, which, in return, benefits future explorations. This is potentially more effective than commonly used action-repeat strategy, which is non-adaptive in its form of plans. Additionally, since the multi-step plan can be interpreted as the intent of the agent from now to a span of time period into the future, it offers a more informative and intuitive signal for interpretation. Experiments are conducted on several benchmark environments and the results demonstrated its effectiveness compared with several baseline methods.
Do You Need the Entropy Reward (in Practice)?
Jan 28, 2022
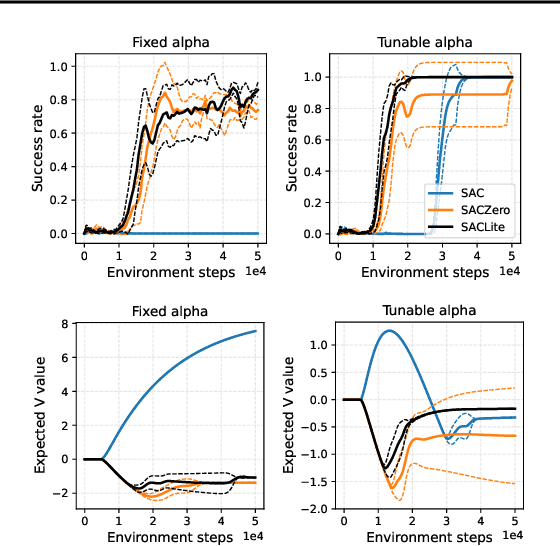

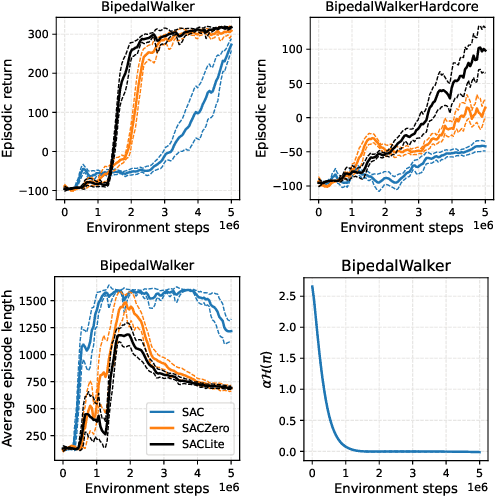
Maximum entropy (MaxEnt) RL maximizes a combination of the original task reward and an entropy reward. It is believed that the regularization imposed by entropy, on both policy improvement and policy evaluation, together contributes to good exploration, training convergence, and robustness of learned policies. This paper takes a closer look at entropy as an intrinsic reward, by conducting various ablation studies on soft actor-critic (SAC), a popular representative of MaxEnt RL. Our findings reveal that in general, entropy rewards should be applied with caution to policy evaluation. On one hand, the entropy reward, like any other intrinsic reward, could obscure the main task reward if it is not properly managed. We identify some failure cases of the entropy reward especially in episodic Markov decision processes (MDPs), where it could cause the policy to be overly optimistic or pessimistic. On the other hand, our large-scale empirical study shows that using entropy regularization alone in policy improvement, leads to comparable or even better performance and robustness than using it in both policy improvement and policy evaluation. Based on these observations, we recommend either normalizing the entropy reward to a zero mean (SACZero), or simply removing it from policy evaluation (SACLite) for better practical results.