 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunjia Xi
Play to Your Strengths: Collaborative Intelligence of Conventional Recommender Models and Large Language Models
Mar 25, 2024
The rise of large language models (LLMs) has opened new opportunities in Recommender Systems (RSs) by enhancing user behavior modeling and content understanding. However, current approaches that integrate LLMs into RSs solely utilize either LLM or conventional recommender model (CRM) to generate final recommendations, without considering which data segments LLM or CRM excel in. To fill in this gap, we conduct experiments on MovieLens-1M and Amazon-Books datasets, and compare the performance of a representative CRM (DCNv2) and an LLM (LLaMA2-7B) on various groups of data samples. Our findings reveal that LLMs excel in data segments where CRMs exhibit lower confidence and precision, while samples where CRM excels are relatively challenging for LLM, requiring substantial training data and a long training time for comparable performance. This suggests potential synergies in the combination between LLM and CRM. Motivated by these insights, we propose Collaborative Recommendation with conventional Recommender and Large Language Model (dubbed \textit{CoReLLa}). In this framework, we first jointly train LLM and CRM and address the issue of decision boundary shifts through alignment loss. Then, the resource-efficient CRM, with a shorter inference time, handles simple and moderate samples, while LLM processes the small subset of challenging samples for CRM. Our experimental results demonstrate that CoReLLa outperforms state-of-the-art CRM and LLM methods significantly, underscoring its effectiveness in recommendation tasks.
ClickPrompt: CTR Models are Strong Prompt Generators for Adapting Language Models to CTR Prediction
Oct 17, 2023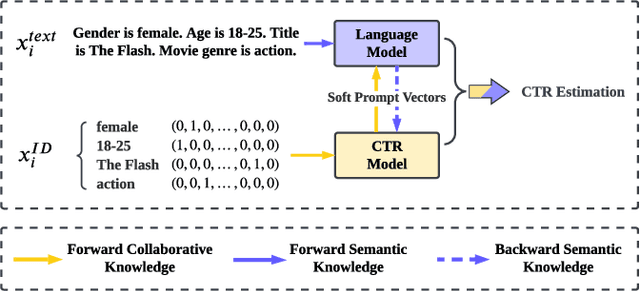
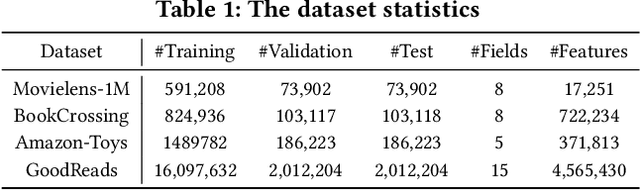
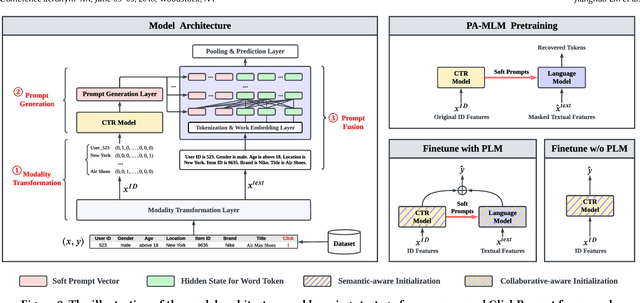
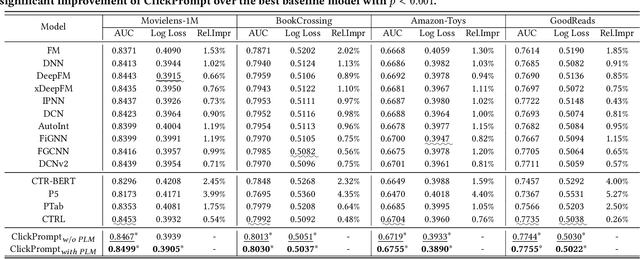
Click-through rate (CTR) prediction has become increasingly indispensable for various Internet applications. Traditional CTR models convert the multi-field categorical data into ID features via one-hot encoding, and extract the collaborative signals among features. Such a paradigm suffers from the problem of semantic information loss. Another line of research explores the potential of pretrained language models (PLMs) for CTR prediction by converting input data into textual sentences through hard prompt templates. Although semantic signals are preserved, they generally fail to capture the collaborative information (e.g., feature interactions, pure ID features), not to mention the unacceptable inference overhead brought by the huge model size. In this paper, we aim to model both the semantic knowledge and collaborative knowledge for accurate CTR estimation, and meanwhile address the inference inefficiency issue. To benefit from both worlds and close their gaps, we propose a novel model-agnostic framework (i.e., ClickPrompt), where we incorporate CTR models to generate interaction-aware soft prompts for PLMs. We design a prompt-augmented masked language modeling (PA-MLM) pretraining task, where PLM has to recover the masked tokens based on the language context, as well as the soft prompts generated by CTR model. The collaborative and semantic knowledge from ID and textual features would be explicitly aligned and interacted via the prompt interface. Then, we can either tune the CTR model with PLM for superior performance, or solely tune the CTR model without PLM for inference efficiency. Experiments on four real-world datasets validate the effectiveness of ClickPrompt compared with existing baselines.
How Can Recommender Systems Benefit from Large Language Models: A Survey
Jun 28, 2023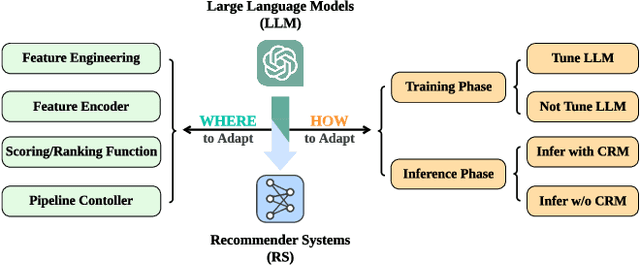
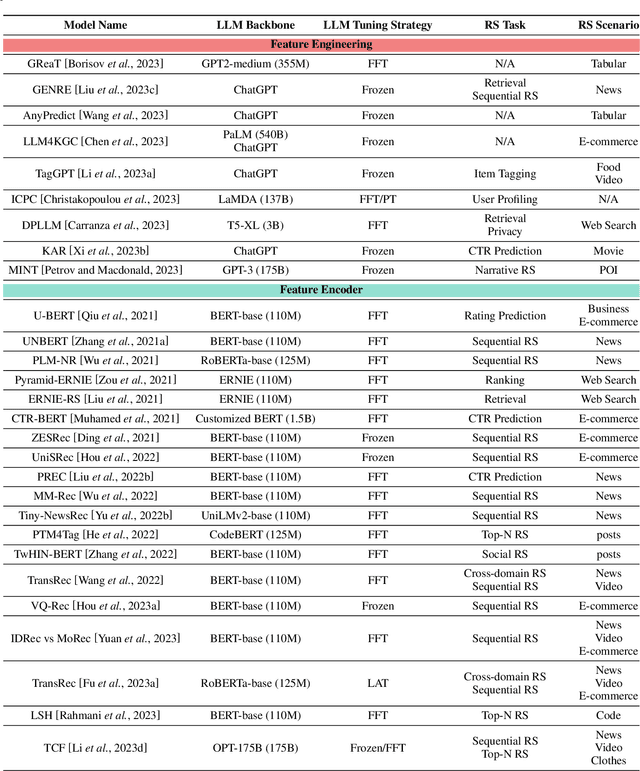
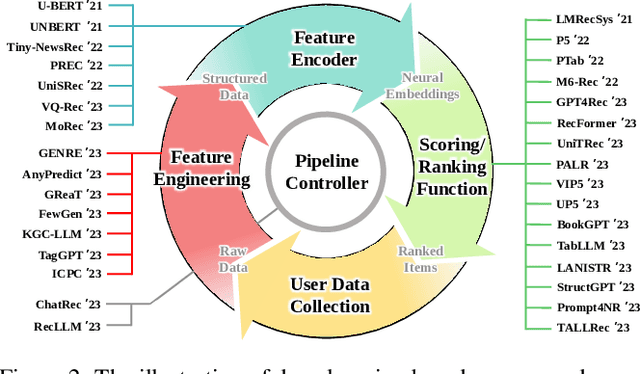
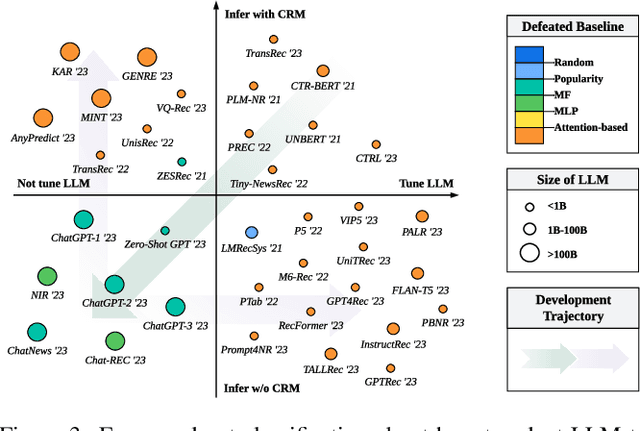
Recommender systems (RS) play important roles to match users' information needs for Internet applications. In natural language processing (NLP) domains, large language model (LLM) has shown astonishing emergent abilities (e.g., instruction following, reasoning), thus giving rise to the promising research direction of adapting LLM to RS for performance enhancements and user experience improvements. In this paper, we conduct a comprehensive survey on this research direction from an application-oriented view. We first summarize existing research works from two orthogonal perspectives: where and how to adapt LLM to RS. For the "WHERE" question, we discuss the roles that LLM could play in different stages of the recommendation pipeline, i.e., feature engineering, feature encoder, scoring/ranking function, and pipeline controller. For the "HOW" question, we investigate the training and inference strategies, resulting in two fine-grained taxonomy criteria, i.e., whether to tune LLMs or not, and whether to involve conventional recommendation model (CRM) for inference. Detailed analysis and general development trajectories are provided for both questions, respectively. Then, we highlight key challenges in adapting LLM to RS from three aspects, i.e., efficiency, effectiveness, and ethics. Finally, we summarize the survey and discuss the future prospects. We also actively maintain a GitHub repository for papers and other related resources in this rising direction: https://github.com/CHIANGEL/Awesome-LLM-for-RecSys.
Towards Open-World Recommendation with Knowledge Augmentation from Large Language Models
Jun 25, 2023



Recommender systems play a vital role in various online services. However, the insulated nature of training and deploying separately within a specific domain limits their access to open-world knowledge. Recently, the emergence of large language models (LLMs) has shown promise in bridging this gap by encoding extensive world knowledge and demonstrating reasoning capability. Nevertheless, previous attempts to directly use LLMs as recommenders have not achieved satisfactory results. In this work, we propose an Open-World Knowledge Augmented Recommendation Framework with Large Language Models, dubbed KAR, to acquire two types of external knowledge from LLMs -- the reasoning knowledge on user preferences and the factual knowledge on items. We introduce factorization prompting to elicit accurate reasoning on user preferences. The generated reasoning and factual knowledge are effectively transformed and condensed into augmented vectors by a hybrid-expert adaptor in order to be compatible with the recommendation task. The obtained vectors can then be directly used to enhance the performance of any recommendation model. We also ensure efficient inference by preprocessing and prestoring the knowledge from the LLM. Extensive experiments show that KAR significantly outperforms the state-of-the-art baselines and is compatible with a wide range of recommendation algorithms.
A Bird's-eye View of Reranking: from List Level to Page Level
Nov 17, 2022



Reranking, as the final stage of multi-stage recommender systems, refines the initial lists to maximize the total utility. With the development of multimedia and user interface design, the recommendation page has evolved to a multi-list style. Separately employing traditional list-level reranking methods for different lists overlooks the inter-list interactions and the effect of different page formats, thus yielding suboptimal reranking performance. Moreover, simply applying a shared network for all the lists fails to capture the commonalities and distinctions in user behaviors on different lists. To this end, we propose to draw a bird's-eye view of \textbf{page-level reranking} and design a novel Page-level Attentional Reranking (PAR) model. We introduce a hierarchical dual-side attention module to extract personalized intra- and inter-list interactions. A spatial-scaled attention network is devised to integrate the spatial relationship into pairwise item influences, which explicitly models the page format. The multi-gated mixture-of-experts module is further applied to capture the commonalities and differences of user behaviors between different lists. Extensive experiments on a public dataset and a proprietary dataset show that PAR significantly outperforms existing baseline models.
Multi-Level Interaction Reranking with User Behavior History
Apr 20, 2022



As the final stage of the multi-stage recommender system (MRS), reranking directly affects users' experience and satisfaction, thus playing a critical role in MRS. Despite the improvement achieved in the existing work, three issues are yet to be solved. First, users' historical behaviors contain rich preference information, such as users' long and short-term interests, but are not fully exploited in reranking. Previous work typically treats items in history equally important, neglecting the dynamic interaction between the history and candidate items. Second, existing reranking models focus on learning interactions at the item level while ignoring the fine-grained feature-level interactions. Lastly, estimating the reranking score on the ordered initial list before reranking may lead to the early scoring problem, thereby yielding suboptimal reranking performance. To address the above issues, we propose a framework named Multi-level Interaction Reranking (MIR). MIR combines low-level cross-item interaction and high-level set-to-list interaction, where we view the candidate items to be reranked as a set and the users' behavior history in chronological order as a list. We design a novel SLAttention structure for modeling the set-to-list interactions with personalized long-short term interests. Moreover, feature-level interactions are incorporated to capture the fine-grained influence among items. We design MIR in such a way that any permutation of the input items would not change the output ranking, and we theoretically prove it. Extensive experiments on three public and proprietary datasets show that MIR significantly outperforms the state-of-the-art models using various ranking and utility metrics.
Neural Re-ranking in Multi-stage Recommender Systems: A Review
Feb 14, 2022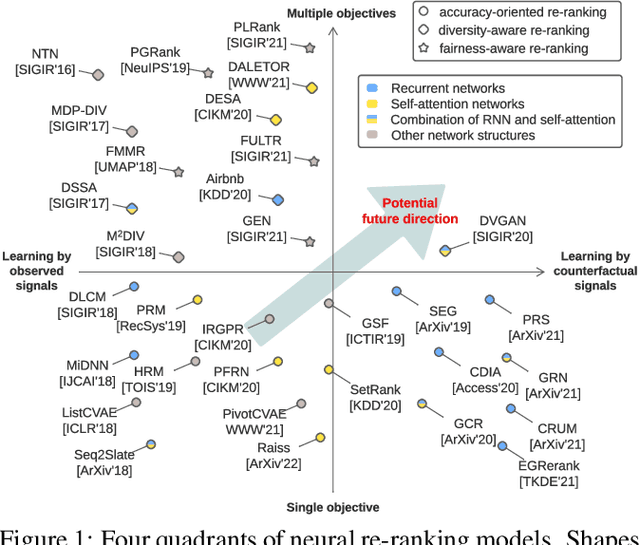
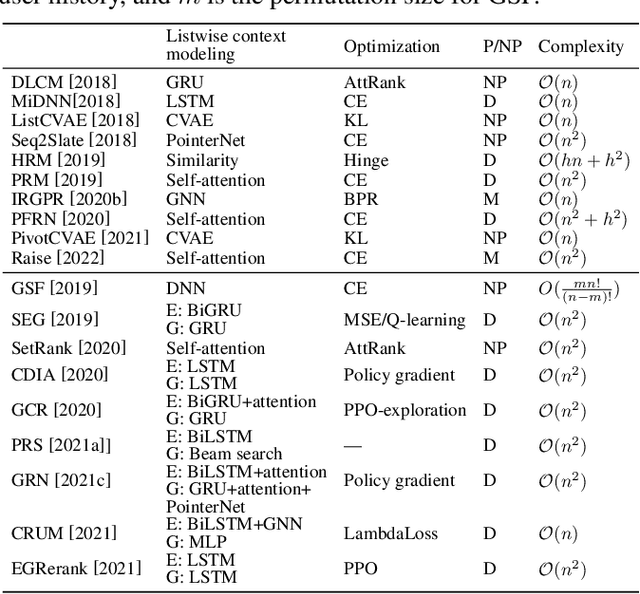
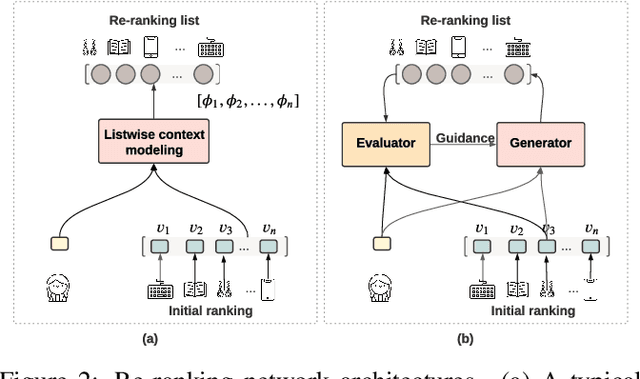
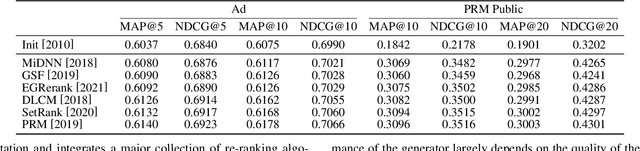
As the final stage of the multi-stage recommender system (MRS), re-ranking directly affects user experience and satisfaction by rearranging the input ranking lists, and thereby plays a critical role in MRS. With the advances in deep learning, neural re-ranking has become a trending topic and been widely applied in industrial applications. This review aims at integrating re-ranking algorithms into a broader picture, and paving ways for more comprehensive solutions for future research. For this purpose, we first present a taxonomy of current methods on neural re-ranking. Then we give a description of these methods along with the historic development according to their objectives. The network structure, personalization, and complexity are also discussed and compared. Next, we provide benchmarks of the major neural re-ranking models and quantitatively analyze their re-ranking performance. Finally, the review concludes with a discussion on future prospects of this field. A list of papers discussed in this review, the benchmark datasets, our re-ranking library LibRerank, and detailed parameter settings are publicly available at https://github.com/LibRerank-Community/LibRerank.
Context-aware Reranking with Utility Maximization for Recommendation
Oct 18, 2021



As a critical task for large-scale commercial recommender systems, reranking has shown the potential of improving recommendation results by uncovering mutual influence among items. Reranking rearranges items in the initial ranking lists from the previous ranking stage to better meet users' demands. However, rather than considering the context of initial lists as most existing methods do, an ideal reranking algorithm should consider the counterfactual context -- the position and the alignment of the items in the reranked lists. In this work, we propose a novel pairwise reranking framework, Context-aware Reranking with Utility Maximization for recommendation (CRUM), which maximizes the overall utility after reranking efficiently. Specifically, we first design a utility-oriented evaluator, which applies Bi-LSTM and graph attention mechanism to estimate the listwise utility via the counterfactual context modeling. Then, under the guidance of the evaluator, we propose a pairwise reranker model to find the most suitable position for each item by swapping misplaced item pairs. Extensive experiments on two benchmark datasets and a proprietary real-world dataset demonstrate that CRUM significantly outperforms the state-of-the-art models in terms of both relevance-based metrics and utility-based metrics.