 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYichao Wang
M-scan: A Multi-Scenario Causal-driven Adaptive Network for Recommendation
Apr 15, 2024
We primarily focus on the field of multi-scenario recommendation, which poses a significant challenge in effectively leveraging data from different scenarios to enhance predictions in scenarios with limited data. Current mainstream efforts mainly center around innovative model network architectures, with the aim of enabling the network to implicitly acquire knowledge from diverse scenarios. However, the uncertainty of implicit learning in networks arises from the absence of explicit modeling, leading to not only difficulty in training but also incomplete user representation and suboptimal performance. Furthermore, through causal graph analysis, we have discovered that the scenario itself directly influences click behavior, yet existing approaches directly incorporate data from other scenarios during the training of the current scenario, leading to prediction biases when they directly utilize click behaviors from other scenarios to train models. To address these problems, we propose the Multi-Scenario Causal-driven Adaptive Network M-scan). This model incorporates a Scenario-Aware Co-Attention mechanism that explicitly extracts user interests from other scenarios that align with the current scenario. Additionally, it employs a Scenario Bias Eliminator module utilizing causal counterfactual inference to mitigate biases introduced by data from other scenarios. Extensive experiments on two public datasets demonstrate the efficacy of our M-scan compared to the existing baseline models.
Tired of Plugins? Large Language Models Can Be End-To-End Recommenders
Apr 07, 2024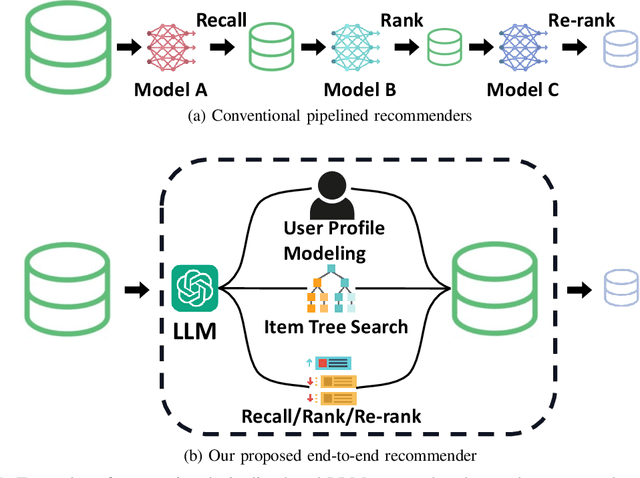
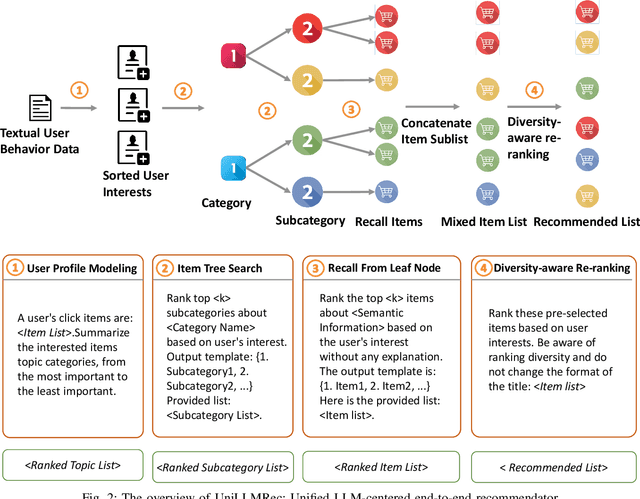
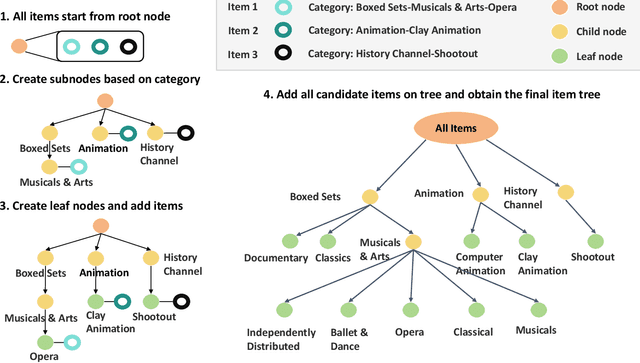
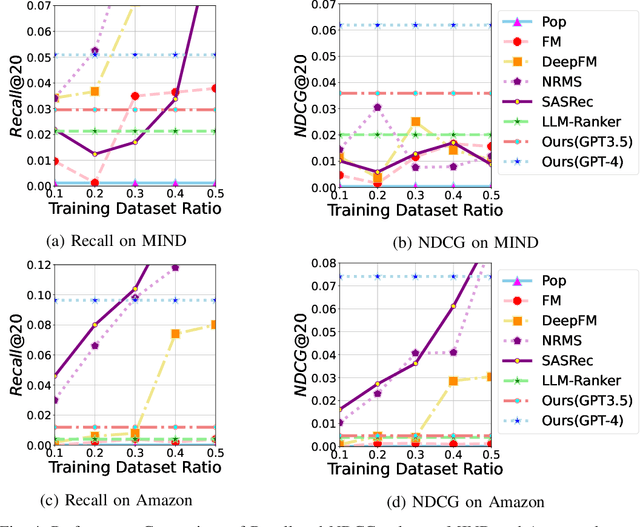
Recommender systems aim to predict user interest based on historical behavioral data. They are mainly designed in sequential pipelines, requiring lots of data to train different sub-systems, and are hard to scale to new domains. Recently, Large Language Models (LLMs) have demonstrated remarkable generalized capabilities, enabling a singular model to tackle diverse recommendation tasks across various scenarios. Nonetheless, existing LLM-based recommendation systems utilize LLM purely for a single task of the recommendation pipeline. Besides, these systems face challenges in presenting large-scale item sets to LLMs in natural language format, due to the constraint of input length. To address these challenges, we introduce an LLM-based end-to-end recommendation framework: UniLLMRec. Specifically, UniLLMRec integrates multi-stage tasks (e.g. recall, ranking, re-ranking) via chain-of-recommendations. To deal with large-scale items, we propose a novel strategy to structure all items into an item tree, which can be dynamically updated and effectively retrieved. UniLLMRec shows promising zero-shot results in comparison with conventional supervised models. Additionally, it boasts high efficiency, reducing the input token need by 86% compared to existing LLM-based models. Such efficiency not only accelerates task completion but also optimizes resource utilization. To facilitate model understanding and to ensure reproducibility, we have made our code publicly available.
ERASE: Benchmarking Feature Selection Methods for Deep Recommender Systems
Mar 20, 2024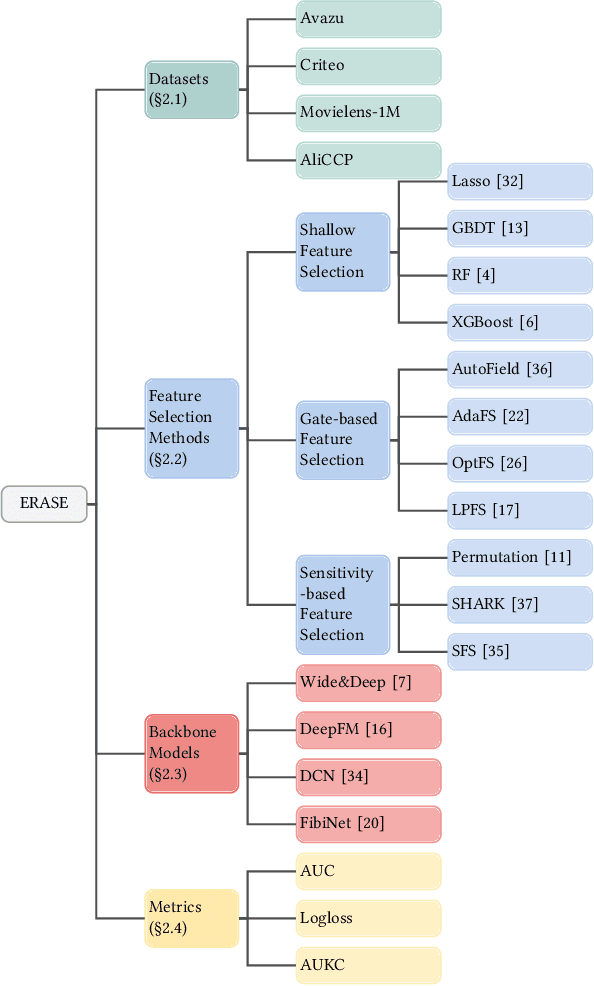
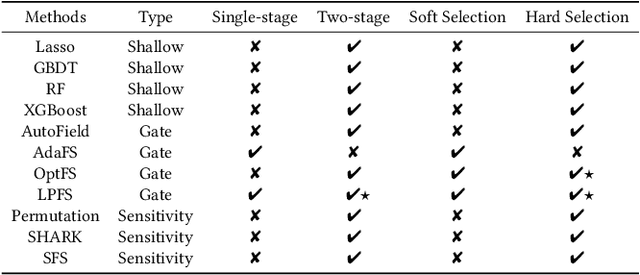
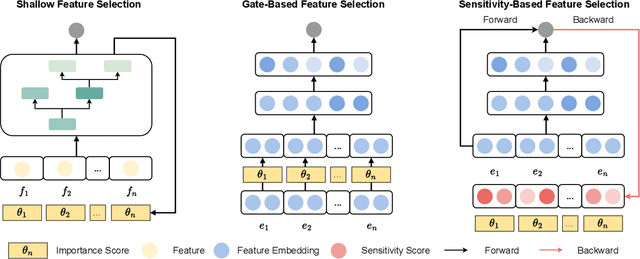
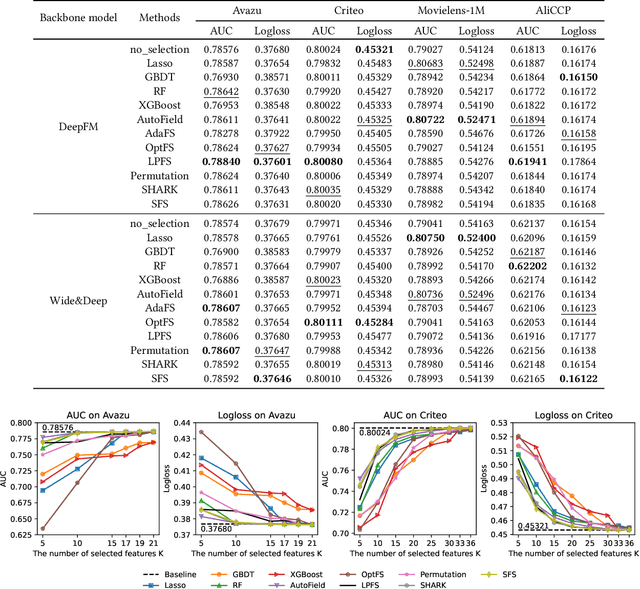
Deep Recommender Systems (DRS) are increasingly dependent on a large number of feature fields for more precise recommendations. Effective feature selection methods are consequently becoming critical for further enhancing the accuracy and optimizing storage efficiencies to align with the deployment demands. This research area, particularly in the context of DRS, is nascent and faces three core challenges. Firstly, variant experimental setups across research papers often yield unfair comparisons, obscuring practical insights. Secondly, the existing literature's lack of detailed analysis on selection attributes, based on large-scale datasets and a thorough comparison among selection techniques and DRS backbones, restricts the generalizability of findings and impedes deployment on DRS. Lastly, research often focuses on comparing the peak performance achievable by feature selection methods, an approach that is typically computationally infeasible for identifying the optimal hyperparameters and overlooks evaluating the robustness and stability of these methods. To bridge these gaps, this paper presents ERASE, a comprehensive bEnchmaRk for feAture SElection for DRS. ERASE comprises a thorough evaluation of eleven feature selection methods, covering both traditional and deep learning approaches, across four public datasets, private industrial datasets, and a real-world commercial platform, achieving significant enhancement. Our code is available online for ease of reproduction.
A Unified Framework for Multi-Domain CTR Prediction via Large Language Models
Dec 20, 2023Click-Through Rate (CTR) prediction is a crucial task in online recommendation platforms as it involves estimating the probability of user engagement with advertisements or items by clicking on them. Given the availability of various services like online shopping, ride-sharing, food delivery, and professional services on commercial platforms, recommendation systems in these platforms are required to make CTR predictions across multiple domains rather than just a single domain. However, multi-domain click-through rate (MDCTR) prediction remains a challenging task in online recommendation due to the complex mutual influence between domains. Traditional MDCTR models typically encode domains as discrete identifiers, ignoring rich semantic information underlying. Consequently, they can hardly generalize to new domains. Besides, existing models can be easily dominated by some specific domains, which results in significant performance drops in the other domains (\ie the ``seesaw phenomenon``). In this paper, we propose a novel solution Uni-CTR to address the above challenges. Uni-CTR leverages a backbone Large Language Model (LLM) to learn layer-wise semantic representations that capture commonalities between domains. Uni-CTR also uses several domain-specific networks to capture the characteristics of each domain. Note that we design a masked loss strategy so that these domain-specific networks are decoupled from backbone LLM. This allows domain-specific networks to remain unchanged when incorporating new or removing domains, thereby enhancing the flexibility and scalability of the system significantly. Experimental results on three public datasets show that Uni-CTR outperforms the state-of-the-art (SOTA) MDCTR models significantly. Furthermore, Uni-CTR demonstrates remarkable effectiveness in zero-shot prediction. We have applied Uni-CTR in industrial scenarios, confirming its efficiency.
Optimal Transport for Treatment Effect Estimation
Oct 27, 2023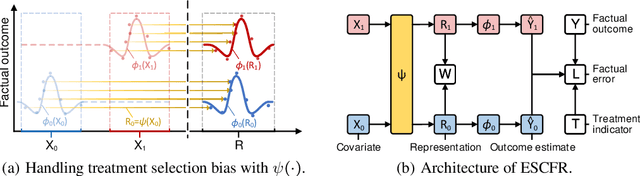
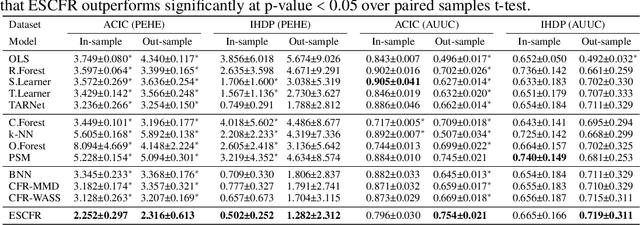
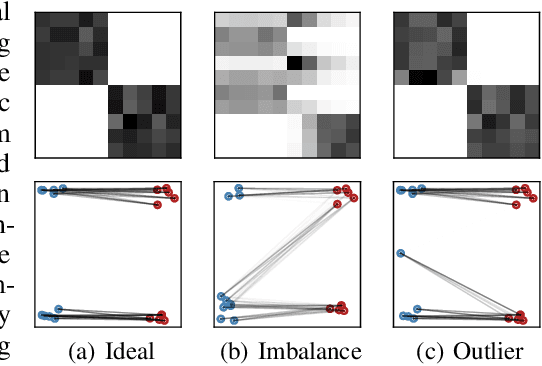

Estimating conditional average treatment effect from observational data is highly challenging due to the existence of treatment selection bias. Prevalent methods mitigate this issue by aligning distributions of different treatment groups in the latent space. However, there are two critical problems that these methods fail to address: (1) mini-batch sampling effects (MSE), which causes misalignment in non-ideal mini-batches with outcome imbalance and outliers; (2) unobserved confounder effects (UCE), which results in inaccurate discrepancy calculation due to the neglect of unobserved confounders. To tackle these problems, we propose a principled approach named Entire Space CounterFactual Regression (ESCFR), which is a new take on optimal transport in the context of causality. Specifically, based on the framework of stochastic optimal transport, we propose a relaxed mass-preserving regularizer to address the MSE issue and design a proximal factual outcome regularizer to handle the UCE issue. Extensive experiments demonstrate that our proposed ESCFR can successfully tackle the treatment selection bias and achieve significantly better performance than state-of-the-art methods.
HAMUR: Hyper Adapter for Multi-Domain Recommendation
Sep 12, 2023

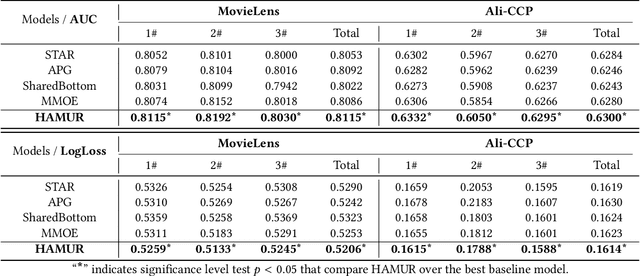
Multi-Domain Recommendation (MDR) has gained significant attention in recent years, which leverages data from multiple domains to enhance their performance concurrently.However, current MDR models are confronted with two limitations. Firstly, the majority of these models adopt an approach that explicitly shares parameters between domains, leading to mutual interference among them. Secondly, due to the distribution differences among domains, the utilization of static parameters in existing methods limits their flexibility to adapt to diverse domains. To address these challenges, we propose a novel model Hyper Adapter for Multi-Domain Recommendation (HAMUR). Specifically, HAMUR consists of two components: (1). Domain-specific adapter, designed as a pluggable module that can be seamlessly integrated into various existing multi-domain backbone models, and (2). Domain-shared hyper-network, which implicitly captures shared information among domains and dynamically generates the parameters for the adapter. We conduct extensive experiments on two public datasets using various backbone networks. The experimental results validate the effectiveness and scalability of the proposed model.
Scenario-Aware Hierarchical Dynamic Network for Multi-Scenario Recommendation
Sep 05, 2023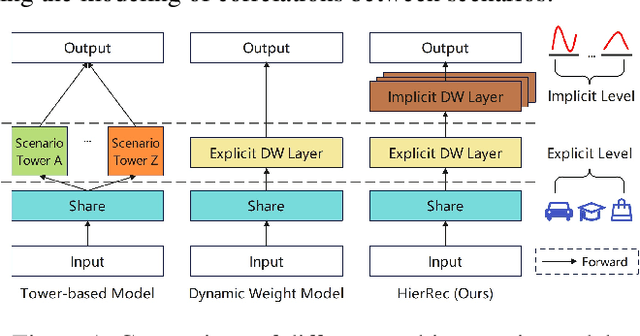

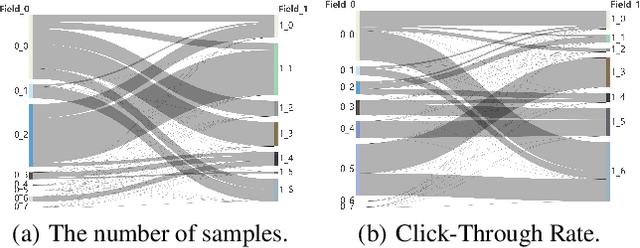
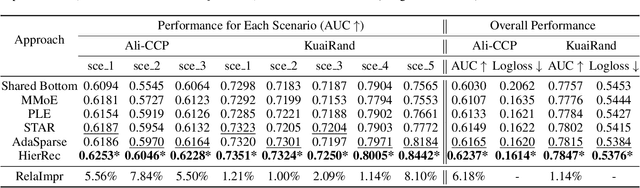
Click-Through Rate (CTR) prediction is a fundamental technique in recommendation and advertising systems. Recent studies have shown that implementing multi-scenario recommendations contributes to strengthening information sharing and improving overall performance. However, existing multi-scenario models only consider coarse-grained explicit scenario modeling that depends on pre-defined scenario identification from manual prior rules, which is biased and sub-optimal. To address these limitations, we propose a Scenario-Aware Hierarchical Dynamic Network for Multi-Scenario Recommendations (HierRec), which perceives implicit patterns adaptively and conducts explicit and implicit scenario modeling jointly. In particular, HierRec designs a basic scenario-oriented module based on the dynamic weight to capture scenario-specific information. Then the hierarchical explicit and implicit scenario-aware modules are proposed to model hybrid-grained scenario information. The multi-head implicit modeling design contributes to perceiving distinctive patterns from different perspectives. Our experiments on two public datasets and real-world industrial applications on a mainstream online advertising platform demonstrate that our HierRec outperforms existing models significantly.
Multi-Task Deep Recommender Systems: A Survey
Feb 09, 2023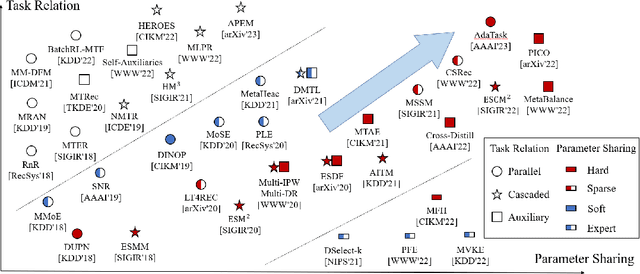
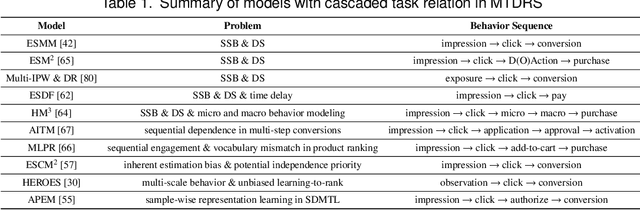

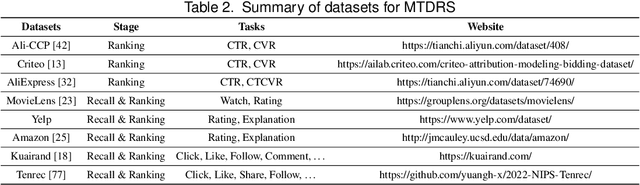
Multi-task learning (MTL) aims at learning related tasks in a unified model to achieve mutual improvement among tasks considering their shared knowledge. It is an important topic in recommendation due to the demand for multi-task prediction considering performance and efficiency. Although MTL has been well studied and developed, there is still a lack of systematic review in the recommendation community. To fill the gap, we provide a comprehensive review of existing multi-task deep recommender systems (MTDRS) in this survey. To be specific, the problem definition of MTDRS is first given, and it is compared with other related areas. Next, the development of MTDRS is depicted and the taxonomy is introduced from the task relation and methodology aspects. Specifically, the task relation is categorized into parallel, cascaded, and auxiliary with main, while the methodology is grouped into parameter sharing, optimization, and training mechanism. The survey concludes by summarizing the application and public datasets of MTDRS and highlighting the challenges and future directions of the field.
IntTower: the Next Generation of Two-Tower Model for Pre-Ranking System
Oct 18, 2022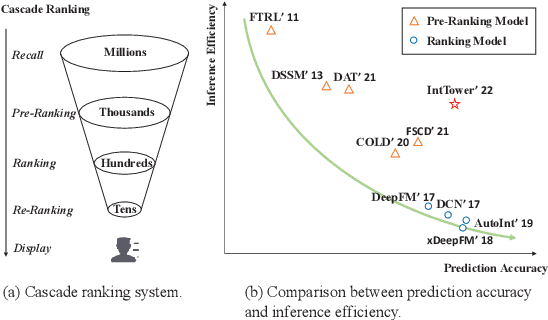
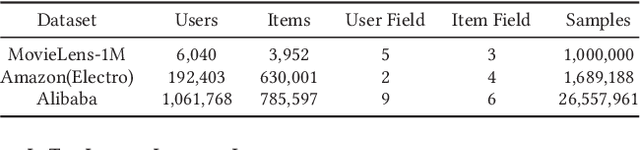
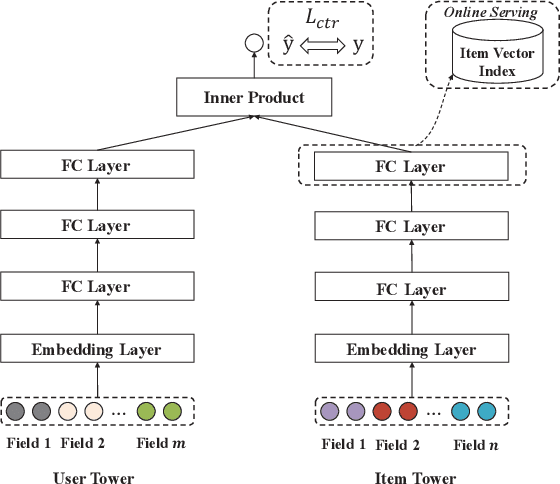
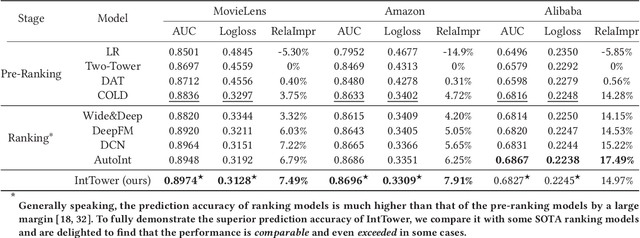
Scoring a large number of candidates precisely in several milliseconds is vital for industrial pre-ranking systems. Existing pre-ranking systems primarily adopt the \textbf{two-tower} model since the ``user-item decoupling architecture'' paradigm is able to balance the \textit{efficiency} and \textit{effectiveness}. However, the cost of high efficiency is the neglect of the potential information interaction between user and item towers, hindering the prediction accuracy critically. In this paper, we show it is possible to design a two-tower model that emphasizes both information interactions and inference efficiency. The proposed model, IntTower (short for \textit{Interaction enhanced Two-Tower}), consists of Light-SE, FE-Block and CIR modules. Specifically, lightweight Light-SE module is used to identify the importance of different features and obtain refined feature representations in each tower. FE-Block module performs fine-grained and early feature interactions to capture the interactive signals between user and item towers explicitly and CIR module leverages a contrastive interaction regularization to further enhance the interactions implicitly. Experimental results on three public datasets show that IntTower outperforms the SOTA pre-ranking models significantly and even achieves comparable performance in comparison with the ranking models. Moreover, we further verify the effectiveness of IntTower on a large-scale advertisement pre-ranking system. The code of IntTower is publicly available\footnote{https://github.com/archersama/IntTower}
A Comprehensive Survey of Natural Language Generation Advances from the Perspective of Digital Deception
Aug 11, 2022


In recent years there has been substantial growth in the capabilities of systems designed to generate text that mimics the fluency and coherence of human language. From this, there has been considerable research aimed at examining the potential uses of these natural language generators (NLG) towards a wide number of tasks. The increasing capabilities of powerful text generators to mimic human writing convincingly raises the potential for deception and other forms of dangerous misuse. As these systems improve, and it becomes ever harder to distinguish between human-written and machine-generated text, malicious actors could leverage these powerful NLG systems to a wide variety of ends, including the creation of fake news and misinformation, the generation of fake online product reviews, or via chatbots as means of convincing users to divulge private information. In this paper, we provide an overview of the NLG field via the identification and examination of 119 survey-like papers focused on NLG research. From these identified papers, we outline a proposed high-level taxonomy of the central concepts that constitute NLG, including the methods used to develop generalised NLG systems, the means by which these systems are evaluated, and the popular NLG tasks and subtasks that exist. In turn, we provide an overview and discussion of each of these items with respect to current research and offer an examination of the potential roles of NLG in deception and detection systems to counteract these threats. Moreover, we discuss the broader challenges of NLG, including the risks of bias that are often exhibited by existing text generation systems. This work offers a broad overview of the field of NLG with respect to its potential for misuse, aiming to provide a high-level understanding of this rapidly developing area of research.