 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYejing Wang
ERASE: Benchmarking Feature Selection Methods for Deep Recommender Systems
Mar 20, 2024
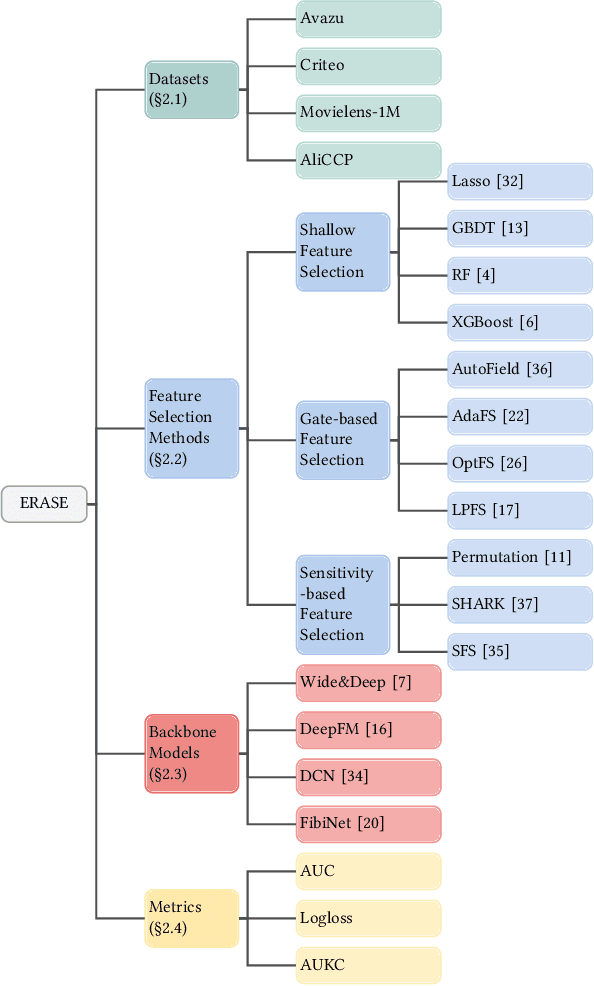
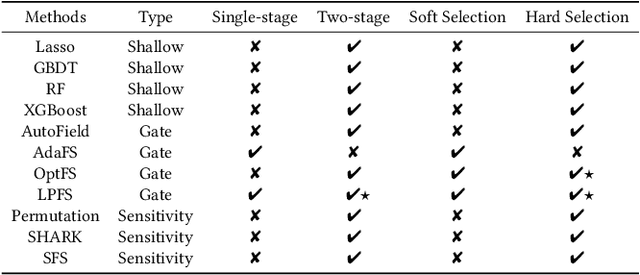
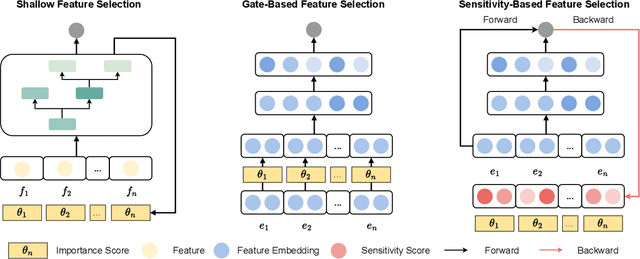
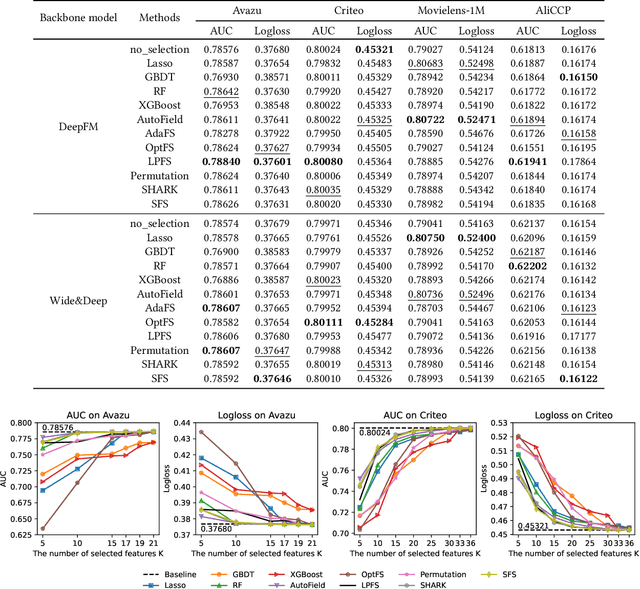
Deep Recommender Systems (DRS) are increasingly dependent on a large number of feature fields for more precise recommendations. Effective feature selection methods are consequently becoming critical for further enhancing the accuracy and optimizing storage efficiencies to align with the deployment demands. This research area, particularly in the context of DRS, is nascent and faces three core challenges. Firstly, variant experimental setups across research papers often yield unfair comparisons, obscuring practical insights. Secondly, the existing literature's lack of detailed analysis on selection attributes, based on large-scale datasets and a thorough comparison among selection techniques and DRS backbones, restricts the generalizability of findings and impedes deployment on DRS. Lastly, research often focuses on comparing the peak performance achievable by feature selection methods, an approach that is typically computationally infeasible for identifying the optimal hyperparameters and overlooks evaluating the robustness and stability of these methods. To bridge these gaps, this paper presents ERASE, a comprehensive bEnchmaRk for feAture SElection for DRS. ERASE comprises a thorough evaluation of eleven feature selection methods, covering both traditional and deep learning approaches, across four public datasets, private industrial datasets, and a real-world commercial platform, achieving significant enhancement. Our code is available online for ease of reproduction.
OpenSiteRec: An Open Dataset for Site Recommendation
Jul 03, 2023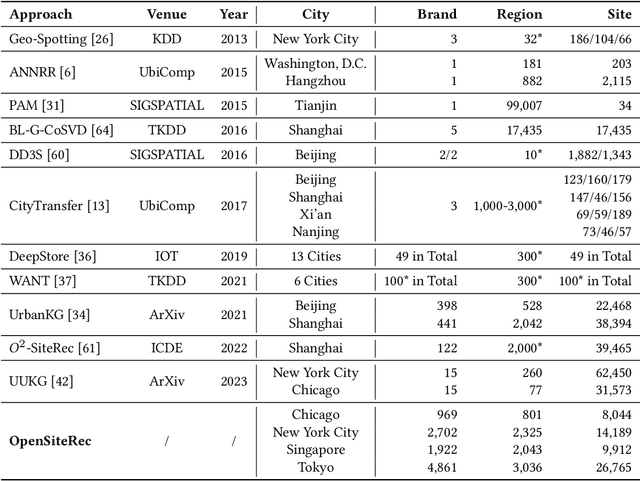



As a representative information retrieval task, site recommendation, which aims at predicting the optimal sites for a brand or an institution to open new branches in an automatic data-driven way, is beneficial and crucial for brand development in modern business. However, there is no publicly available dataset so far and most existing approaches are limited to an extremely small scope of brands, which seriously hinders the research on site recommendation. Therefore, we collect, construct and release an open comprehensive dataset, namely OpenSiteRec, to facilitate and promote the research on site recommendation. Specifically, OpenSiteRec leverages a heterogeneous graph schema to represent various types of real-world entities and relations in four international metropolises. To evaluate the performance of the existing general methods on the site recommendation task, we conduct benchmarking experiments of several representative recommendation models on OpenSiteRec. Furthermore, we also highlight the potential application directions to demonstrate the wide applicability of OpenSiteRec. We believe that our OpenSiteRec dataset is significant and anticipated to encourage the development of advanced methods for site recommendation. OpenSiteRec is available online at https://OpenSiteRec.github.io/.
AutoDenoise: Automatic Data Instance Denoising for Recommendations
Mar 12, 2023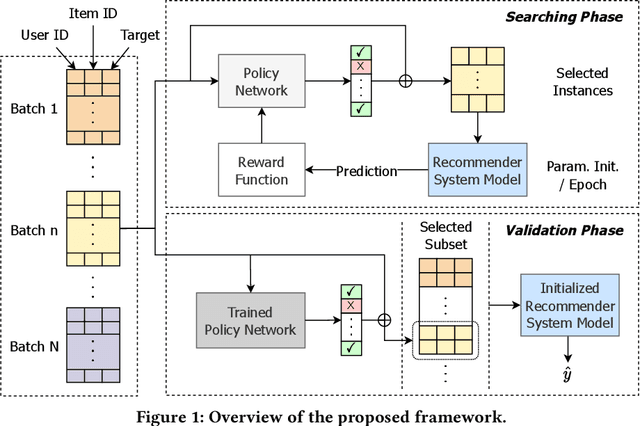

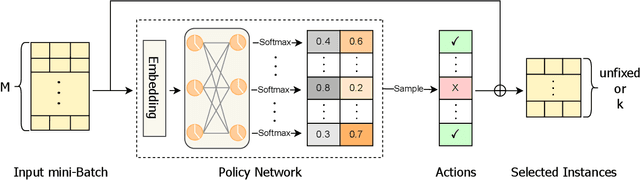

Historical user-item interaction datasets are essential in training modern recommender systems for predicting user preferences. However, the arbitrary user behaviors in most recommendation scenarios lead to a large volume of noisy data instances being recorded, which cannot fully represent their true interests. While a large number of denoising studies are emerging in the recommender system community, all of them suffer from highly dynamic data distributions. In this paper, we propose a Deep Reinforcement Learning (DRL) based framework, AutoDenoise, with an Instance Denoising Policy Network, for denoising data instances with an instance selection manner in deep recommender systems. To be specific, AutoDenoise serves as an agent in DRL to adaptively select noise-free and predictive data instances, which can then be utilized directly in training representative recommendation models. In addition, we design an alternate two-phase optimization strategy to train and validate the AutoDenoise properly. In the searching phase, we aim to train the policy network with the capacity of instance denoising; in the validation phase, we find out and evaluate the denoised subset of data instances selected by the trained policy network, so as to validate its denoising ability. We conduct extensive experiments to validate the effectiveness of AutoDenoise combined with multiple representative recommender system models.
AutoField: Automating Feature Selection in Deep Recommender Systems
Apr 19, 2022



Feature quality has an impactful effect on recommendation performance. Thereby, feature selection is a critical process in developing deep learning-based recommender systems. Most existing deep recommender systems, however, focus on designing sophisticated neural networks, while neglecting the feature selection process. Typically, they just feed all possible features into their proposed deep architectures, or select important features manually by human experts. The former leads to non-trivial embedding parameters and extra inference time, while the latter requires plenty of expert knowledge and human labor effort. In this work, we propose an AutoML framework that can adaptively select the essential feature fields in an automatic manner. Specifically, we first design a differentiable controller network, which is capable of automatically adjusting the probability of selecting a particular feature field; then, only selected feature fields are utilized to retrain the deep recommendation model. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our framework. We conduct further experiments to investigate its properties, including the transferability, key components, and parameter sensitivity.
Automated Machine Learning for Deep Recommender Systems: A Survey
Apr 04, 2022


Deep recommender systems (DRS) are critical for current commercial online service providers, which address the issue of information overload by recommending items that are tailored to the user's interests and preferences. They have unprecedented feature representations effectiveness and the capacity of modeling the non-linear relationships between users and items. Despite their advancements, DRS models, like other deep learning models, employ sophisticated neural network architectures and other vital components that are typically designed and tuned by human experts. This article will give a comprehensive summary of automated machine learning (AutoML) for developing DRS models. We first provide an overview of AutoML for DRS models and the related techniques. Then we discuss the state-of-the-art AutoML approaches that automate the feature selection, feature embeddings, feature interactions, and system design in DRS. Finally, we discuss appealing research directions and summarize the survey.