 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiachen Zhu
M-scan: A Multi-Scenario Causal-driven Adaptive Network for Recommendation
Apr 15, 2024
We primarily focus on the field of multi-scenario recommendation, which poses a significant challenge in effectively leveraging data from different scenarios to enhance predictions in scenarios with limited data. Current mainstream efforts mainly center around innovative model network architectures, with the aim of enabling the network to implicitly acquire knowledge from diverse scenarios. However, the uncertainty of implicit learning in networks arises from the absence of explicit modeling, leading to not only difficulty in training but also incomplete user representation and suboptimal performance. Furthermore, through causal graph analysis, we have discovered that the scenario itself directly influences click behavior, yet existing approaches directly incorporate data from other scenarios during the training of the current scenario, leading to prediction biases when they directly utilize click behaviors from other scenarios to train models. To address these problems, we propose the Multi-Scenario Causal-driven Adaptive Network M-scan). This model incorporates a Scenario-Aware Co-Attention mechanism that explicitly extracts user interests from other scenarios that align with the current scenario. Additionally, it employs a Scenario Bias Eliminator module utilizing causal counterfactual inference to mitigate biases introduced by data from other scenarios. Extensive experiments on two public datasets demonstrate the efficacy of our M-scan compared to the existing baseline models.
Variance-Covariance Regularization Improves Representation Learning
Jun 23, 2023



Transfer learning has emerged as a key approach in the machine learning domain, enabling the application of knowledge derived from one domain to improve performance on subsequent tasks. Given the often limited information about these subsequent tasks, a strong transfer learning approach calls for the model to capture a diverse range of features during the initial pretraining stage. However, recent research suggests that, without sufficient regularization, the network tends to concentrate on features that primarily reduce the pretraining loss function. This tendency can result in inadequate feature learning and impaired generalization capability for target tasks. To address this issue, we propose Variance-Covariance Regularization (VCR), a regularization technique aimed at fostering diversity in the learned network features. Drawing inspiration from recent advancements in the self-supervised learning approach, our approach promotes learned representations that exhibit high variance and minimal covariance, thus preventing the network from focusing solely on loss-reducing features. We empirically validate the efficacy of our method through comprehensive experiments coupled with in-depth analytical studies on the learned representations. In addition, we develop an efficient implementation strategy that assures minimal computational overhead associated with our method. Our results indicate that VCR is a powerful and efficient method for enhancing transfer learning performance for both supervised learning and self-supervised learning, opening new possibilities for future research in this domain.
VoLTA: Vision-Language Transformer with Weakly-Supervised Local-Feature Alignment
Oct 09, 2022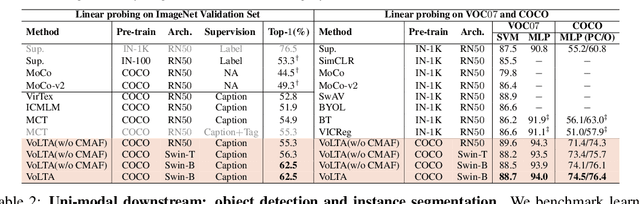
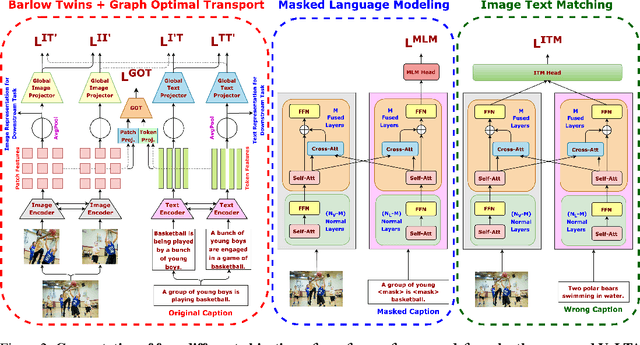
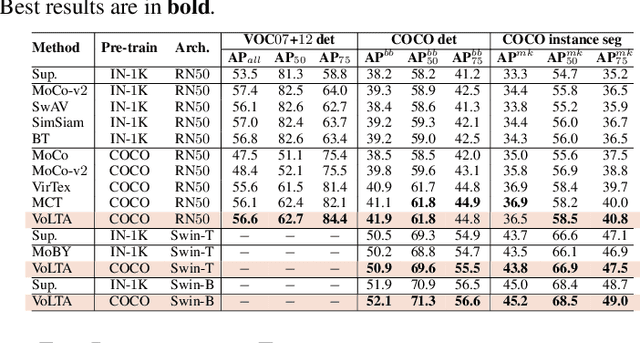

Vision-language pre-training (VLP) has recently proven highly effective for various uni- and multi-modal downstream applications. However, most existing end-to-end VLP methods use high-resolution image-text box data to perform well on fine-grained region-level tasks, such as object detection, segmentation, and referring expression comprehension. Unfortunately, such high-resolution images with accurate bounding box annotations are expensive to collect and use for supervision at scale. In this work, we propose VoLTA (Vision-Language Transformer with weakly-supervised local-feature Alignment), a new VLP paradigm that only utilizes image-caption data but achieves fine-grained region-level image understanding, eliminating the use of expensive box annotations. VoLTA adopts graph optimal transport-based weakly-supervised alignment on local image patches and text tokens to germinate an explicit, self-normalized, and interpretable low-level matching criterion. In addition, VoLTA pushes multi-modal fusion deep into the uni-modal backbones during pre-training and removes fusion-specific transformer layers, further reducing memory requirements. Extensive experiments on a wide range of vision- and vision-language downstream tasks demonstrate the effectiveness of VoLTA on fine-grained applications without compromising the coarse-grained downstream performance, often outperforming methods using significantly more caption and box annotations.
TiCo: Transformation Invariance and Covariance Contrast for Self-Supervised Visual Representation Learning
Jun 23, 2022



We present Transformation Invariance and Covariance Contrast (TiCo) for self-supervised visual representation learning. Similar to other recent self-supervised learning methods, our method is based on maximizing the agreement among embeddings of different distorted versions of the same image, which pushes the encoder to produce transformation invariant representations. To avoid the trivial solution where the encoder generates constant vectors, we regularize the covariance matrix of the embeddings from different images by penalizing low rank solutions. By jointly minimizing the transformation invariance loss and covariance contrast loss, we get an encoder that is able to produce useful representations for downstream tasks. We analyze our method and show that it can be viewed as a variant of MoCo with an implicit memory bank of unlimited size at no extra memory cost. This makes our method perform better than alternative methods when using small batch sizes. TiCo can also be seen as a modification of Barlow Twins. By connecting the contrastive and redundancy-reduction methods together, TiCo gives us new insights into how joint embedding methods work.
Masked Siamese ConvNets
Jun 15, 2022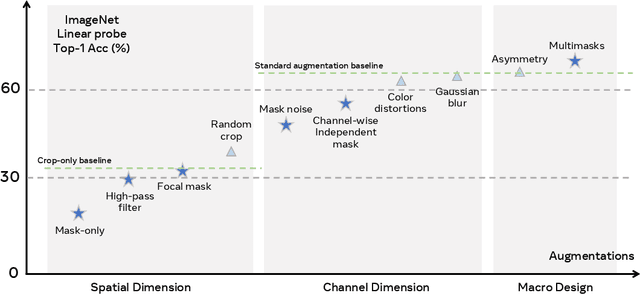
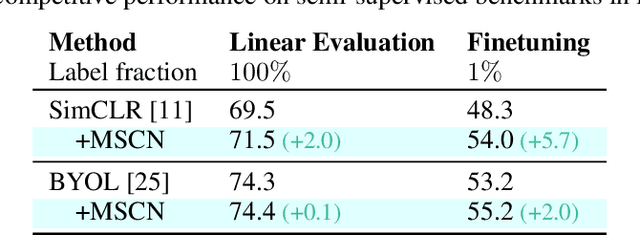

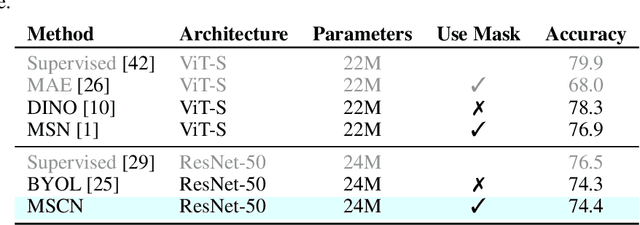
Self-supervised learning has shown superior performances over supervised methods on various vision benchmarks. The siamese network, which encourages embeddings to be invariant to distortions, is one of the most successful self-supervised visual representation learning approaches. Among all the augmentation methods, masking is the most general and straightforward method that has the potential to be applied to all kinds of input and requires the least amount of domain knowledge. However, masked siamese networks require particular inductive bias and practically only work well with Vision Transformers. This work empirically studies the problems behind masked siamese networks with ConvNets. We propose several empirical designs to overcome these problems gradually. Our method performs competitively on low-shot image classification and outperforms previous methods on object detection benchmarks. We discuss several remaining issues and hope this work can provide useful data points for future general-purpose self-supervised learning.