 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRama Chellappa
The 8th AI City Challenge
Apr 15, 2024
The eighth AI City Challenge highlighted the convergence of computer vision and artificial intelligence in areas like retail, warehouse settings, and Intelligent Traffic Systems (ITS), presenting significant research opportunities. The 2024 edition featured five tracks, attracting unprecedented interest from 726 teams in 47 countries and regions. Track 1 dealt with multi-target multi-camera (MTMC) people tracking, highlighting significant enhancements in camera count, character number, 3D annotation, and camera matrices, alongside new rules for 3D tracking and online tracking algorithm encouragement. Track 2 introduced dense video captioning for traffic safety, focusing on pedestrian accidents using multi-camera feeds to improve insights for insurance and prevention. Track 3 required teams to classify driver actions in a naturalistic driving analysis. Track 4 explored fish-eye camera analytics using the FishEye8K dataset. Track 5 focused on motorcycle helmet rule violation detection. The challenge utilized two leaderboards to showcase methods, with participants setting new benchmarks, some surpassing existing state-of-the-art achievements.
Generating Potent Poisons and Backdoors from Scratch with Guided Diffusion
Mar 25, 2024Modern neural networks are often trained on massive datasets that are web scraped with minimal human inspection. As a result of this insecure curation pipeline, an adversary can poison or backdoor the resulting model by uploading malicious data to the internet and waiting for a victim to scrape and train on it. Existing approaches for creating poisons and backdoors start with randomly sampled clean data, called base samples, and then modify those samples to craft poisons. However, some base samples may be significantly more amenable to poisoning than others. As a result, we may be able to craft more potent poisons by carefully choosing the base samples. In this work, we use guided diffusion to synthesize base samples from scratch that lead to significantly more potent poisons and backdoors than previous state-of-the-art attacks. Our Guided Diffusion Poisoning (GDP) base samples can be combined with any downstream poisoning or backdoor attack to boost its effectiveness. Our implementation code is publicly available at: https://github.com/hsouri/GDP .
FaceXFormer: A Unified Transformer for Facial Analysis
Mar 19, 2024
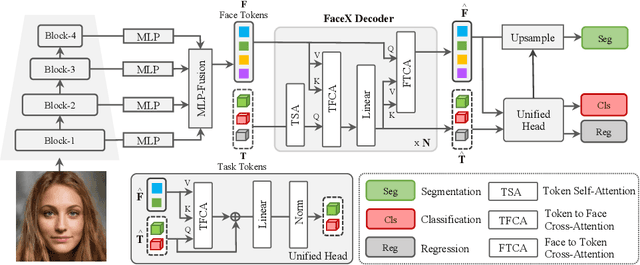
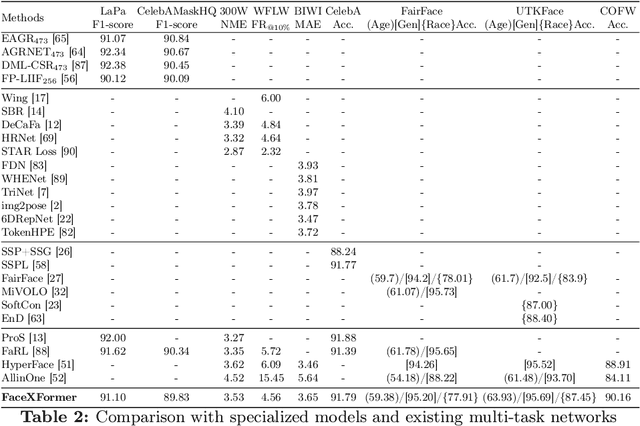
In this work, we introduce FaceXformer, an end-to-end unified transformer model for a comprehensive range of facial analysis tasks such as face parsing, landmark detection, head pose estimation, attributes recognition, and estimation of age, gender, race, and landmarks visibility. Conventional methods in face analysis have often relied on task-specific designs and preprocessing techniques, which limit their approach to a unified architecture. Unlike these conventional methods, our FaceXformer leverages a transformer-based encoder-decoder architecture where each task is treated as a learnable token, enabling the integration of multiple tasks within a single framework. Moreover, we propose a parameter-efficient decoder, FaceX, which jointly processes face and task tokens, thereby learning generalized and robust face representations across different tasks. To the best of our knowledge, this is the first work to propose a single model capable of handling all these facial analysis tasks using transformers. We conducted a comprehensive analysis of effective backbones for unified face task processing and evaluated different task queries and the synergy between them. We conduct experiments against state-of-the-art specialized models and previous multi-task models in both intra-dataset and cross-dataset evaluations across multiple benchmarks. Additionally, our model effectively handles images "in-the-wild," demonstrating its robustness and generalizability across eight different tasks, all while maintaining the real-time performance of 37 FPS.
BAGS: Blur Agnostic Gaussian Splatting through Multi-Scale Kernel Modeling
Mar 07, 2024
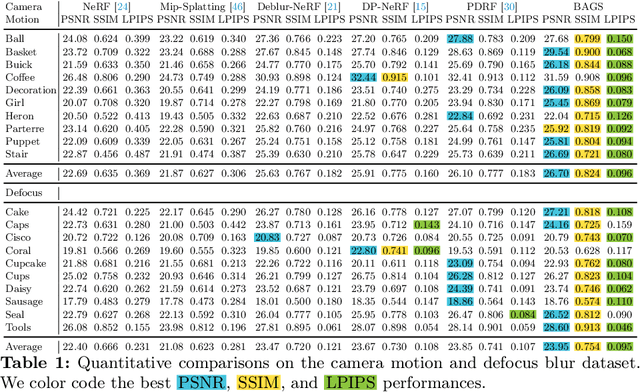
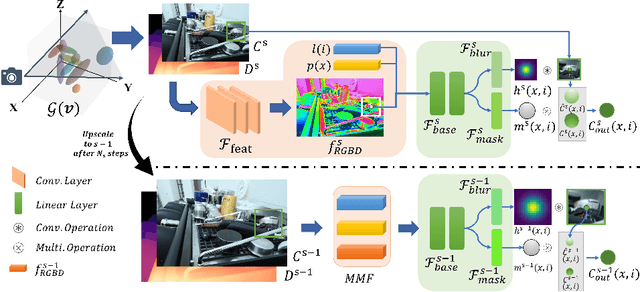

Recent efforts in using 3D Gaussians for scene reconstruction and novel view synthesis can achieve impressive results on curated benchmarks; however, images captured in real life are often blurry. In this work, we analyze the robustness of Gaussian-Splatting-based methods against various image blur, such as motion blur, defocus blur, downscaling blur, \etc. Under these degradations, Gaussian-Splatting-based methods tend to overfit and produce worse results than Neural-Radiance-Field-based methods. To address this issue, we propose Blur Agnostic Gaussian Splatting (BAGS). BAGS introduces additional 2D modeling capacities such that a 3D-consistent and high quality scene can be reconstructed despite image-wise blur. Specifically, we model blur by estimating per-pixel convolution kernels from a Blur Proposal Network (BPN). BPN is designed to consider spatial, color, and depth variations of the scene to maximize modeling capacity. Additionally, BPN also proposes a quality-assessing mask, which indicates regions where blur occur. Finally, we introduce a coarse-to-fine kernel optimization scheme; this optimization scheme is fast and avoids sub-optimal solutions due to a sparse point cloud initialization, which often occurs when we apply Structure-from-Motion on blurry images. We demonstrate that BAGS achieves photorealistic renderings under various challenging blur conditions and imaging geometry, while significantly improving upon existing approaches.
Addressing cognitive bias in medical language models
Feb 20, 2024There is increasing interest in the application large language models (LLMs) to the medical field, in part because of their impressive performance on medical exam questions. While promising, exam questions do not reflect the complexity of real patient-doctor interactions. In reality, physicians' decisions are shaped by many complex factors, such as patient compliance, personal experience, ethical beliefs, and cognitive bias. Taking a step toward understanding this, our hypothesis posits that when LLMs are confronted with clinical questions containing cognitive biases, they will yield significantly less accurate responses compared to the same questions presented without such biases. In this study, we developed BiasMedQA, a benchmark for evaluating cognitive biases in LLMs applied to medical tasks. Using BiasMedQA we evaluated six LLMs, namely GPT-4, Mixtral-8x70B, GPT-3.5, PaLM-2, Llama 2 70B-chat, and the medically specialized PMC Llama 13B. We tested these models on 1,273 questions from the US Medical Licensing Exam (USMLE) Steps 1, 2, and 3, modified to replicate common clinically-relevant cognitive biases. Our analysis revealed varying effects for biases on these LLMs, with GPT-4 standing out for its resilience to bias, in contrast to Llama 2 70B-chat and PMC Llama 13B, which were disproportionately affected by cognitive bias. Our findings highlight the critical need for bias mitigation in the development of medical LLMs, pointing towards safer and more reliable applications in healthcare.
CLR-Face: Conditional Latent Refinement for Blind Face Restoration Using Score-Based Diffusion Models
Feb 08, 2024Recent generative-prior-based methods have shown promising blind face restoration performance. They usually project the degraded images to the latent space and then decode high-quality faces either by single-stage latent optimization or directly from the encoding. Generating fine-grained facial details faithful to inputs remains a challenging problem. Most existing methods produce either overly smooth outputs or alter the identity as they attempt to balance between generation and reconstruction. This may be attributed to the typical trade-off between quality and resolution in the latent space. If the latent space is highly compressed, the decoded output is more robust to degradations but shows worse fidelity. On the other hand, a more flexible latent space can capture intricate facial details better, but is extremely difficult to optimize for highly degraded faces using existing techniques. To address these issues, we introduce a diffusion-based-prior inside a VQGAN architecture that focuses on learning the distribution over uncorrupted latent embeddings. With such knowledge, we iteratively recover the clean embedding conditioning on the degraded counterpart. Furthermore, to ensure the reverse diffusion trajectory does not deviate from the underlying identity, we train a separate Identity Recovery Network and use its output to constrain the reverse diffusion process. Specifically, using a learnable latent mask, we add gradients from a face-recognition network to a subset of latent features that correlates with the finer identity-related details in the pixel space, leaving the other features untouched. Disentanglement between perception and fidelity in the latent space allows us to achieve the best of both worlds. We perform extensive evaluations on multiple real and synthetic datasets to validate the superiority of our approach.
MV2MAE: Multi-View Video Masked Autoencoders
Jan 29, 2024Videos captured from multiple viewpoints can help in perceiving the 3D structure of the world and benefit computer vision tasks such as action recognition, tracking, etc. In this paper, we present a method for self-supervised learning from synchronized multi-view videos. We use a cross-view reconstruction task to inject geometry information in the model. Our approach is based on the masked autoencoder (MAE) framework. In addition to the same-view decoder, we introduce a separate cross-view decoder which leverages cross-attention mechanism to reconstruct a target viewpoint video using a video from source viewpoint, to help representations robust to viewpoint changes. For videos, static regions can be reconstructed trivially which hinders learning meaningful representations. To tackle this, we introduce a motion-weighted reconstruction loss which improves temporal modeling. We report state-of-the-art results on the NTU-60, NTU-120 and ETRI datasets, as well as in the transfer learning setting on NUCLA, PKU-MMD-II and ROCOG-v2 datasets, demonstrating the robustness of our approach. Code will be made available.
Gaussian Harmony: Attaining Fairness in Diffusion-based Face Generation Models
Dec 21, 2023Diffusion models have achieved great progress in face generation. However, these models amplify the bias in the generation process, leading to an imbalance in distribution of sensitive attributes such as age, gender and race. This paper proposes a novel solution to this problem by balancing the facial attributes of the generated images. We mitigate the bias by localizing the means of the facial attributes in the latent space of the diffusion model using Gaussian mixture models (GMM). Our motivation for choosing GMMs over other clustering frameworks comes from the flexible latent structure of diffusion model. Since each sampling step in diffusion models follows a Gaussian distribution, we show that fitting a GMM model helps us to localize the subspace responsible for generating a specific attribute. Furthermore, our method does not require retraining, we instead localize the subspace on-the-fly and mitigate the bias for generating a fair dataset. We evaluate our approach on multiple face attribute datasets to demonstrate the effectiveness of our approach. Our results demonstrate that our approach leads to a more fair data generation in terms of representational fairness while preserving the quality of generated samples.
Jack of All Tasks, Master of Many: Designing General-purpose Coarse-to-Fine Vision-Language Model
Dec 19, 2023The ability of large language models (LLMs) to process visual inputs has given rise to general-purpose vision systems, unifying various vision-language (VL) tasks by instruction tuning. However, due to the enormous diversity in input-output formats in the vision domain, existing general-purpose models fail to successfully integrate segmentation and multi-image inputs with coarse-level tasks into a single framework. In this work, we introduce VistaLLM, a powerful visual system that addresses coarse- and fine-grained VL tasks over single and multiple input images using a unified framework. VistaLLM utilizes an instruction-guided image tokenizer that filters global embeddings using task descriptions to extract compressed and refined features from numerous images. Moreover, VistaLLM employs a gradient-aware adaptive sampling technique to represent binary segmentation masks as sequences, significantly improving over previously used uniform sampling. To bolster the desired capability of VistaLLM, we curate CoinIt, a comprehensive coarse-to-fine instruction tuning dataset with 6.8M samples. We also address the lack of multi-image grounding datasets by introducing a novel task, AttCoSeg (Attribute-level Co-Segmentation), which boosts the model's reasoning and grounding capability over multiple input images. Extensive experiments on a wide range of V- and VL tasks demonstrate the effectiveness of VistaLLM by achieving consistent state-of-the-art performance over strong baselines across all downstream tasks. Our project page can be found at https://shramanpramanick.github.io/VistaLLM/.
Unsupervised Video Domain Adaptation with Masked Pre-Training and Collaborative Self-Training
Dec 06, 2023In this work, we tackle the problem of unsupervised domain adaptation (UDA) for video action recognition. Our approach, which we call UNITE, uses an image teacher model to adapt a video student model to the target domain. UNITE first employs self-supervised pre-training to promote discriminative feature learning on target domain videos using a teacher-guided masked distillation objective. We then perform self-training on masked target data, using the video student model and image teacher model together to generate improved pseudolabels for unlabeled target videos. Our self-training process successfully leverages the strengths of both models to achieve strong transfer performance across domains. We evaluate our approach on multiple video domain adaptation benchmarks and observe significant improvements upon previously reported results.