 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNicolas Ballas
Learning and Leveraging World Models in Visual Representation Learning
Mar 01, 2024
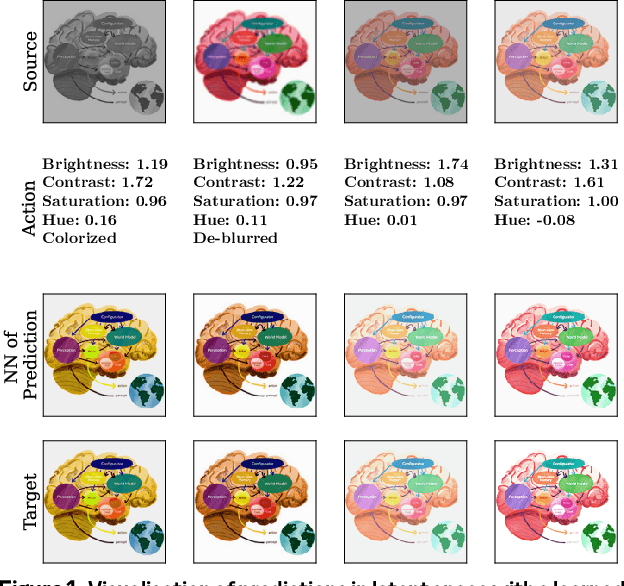

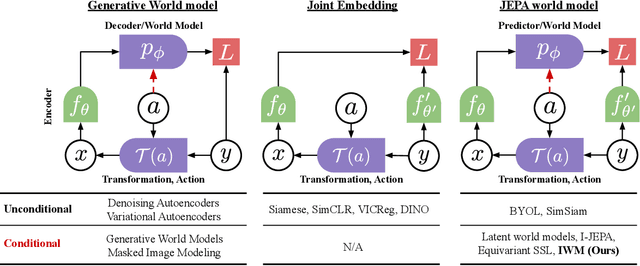
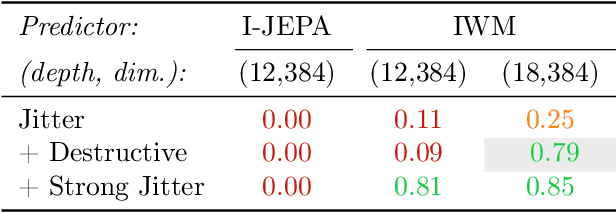
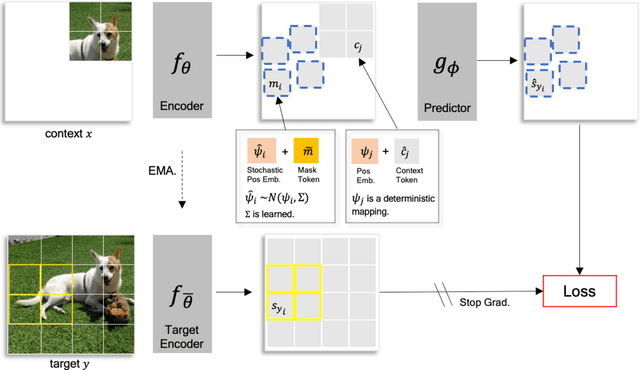
Joint-Embedding Predictive Architecture (JEPA) has emerged as a promising self-supervised approach that learns by leveraging a world model. While previously limited to predicting missing parts of an input, we explore how to generalize the JEPA prediction task to a broader set of corruptions. We introduce Image World Models, an approach that goes beyond masked image modeling and learns to predict the effect of global photometric transformations in latent space. We study the recipe of learning performant IWMs and show that it relies on three key aspects: conditioning, prediction difficulty, and capacity. Additionally, we show that the predictive world model learned by IWM can be adapted through finetuning to solve diverse tasks; a fine-tuned IWM world model matches or surpasses the performance of previous self-supervised methods. Finally, we show that learning with an IWM allows one to control the abstraction level of the learned representations, learning invariant representations such as contrastive methods, or equivariant representations such as masked image modelling.
Jack of All Tasks, Master of Many: Designing General-purpose Coarse-to-Fine Vision-Language Model
Dec 19, 2023The ability of large language models (LLMs) to process visual inputs has given rise to general-purpose vision systems, unifying various vision-language (VL) tasks by instruction tuning. However, due to the enormous diversity in input-output formats in the vision domain, existing general-purpose models fail to successfully integrate segmentation and multi-image inputs with coarse-level tasks into a single framework. In this work, we introduce VistaLLM, a powerful visual system that addresses coarse- and fine-grained VL tasks over single and multiple input images using a unified framework. VistaLLM utilizes an instruction-guided image tokenizer that filters global embeddings using task descriptions to extract compressed and refined features from numerous images. Moreover, VistaLLM employs a gradient-aware adaptive sampling technique to represent binary segmentation masks as sequences, significantly improving over previously used uniform sampling. To bolster the desired capability of VistaLLM, we curate CoinIt, a comprehensive coarse-to-fine instruction tuning dataset with 6.8M samples. We also address the lack of multi-image grounding datasets by introducing a novel task, AttCoSeg (Attribute-level Co-Segmentation), which boosts the model's reasoning and grounding capability over multiple input images. Extensive experiments on a wide range of V- and VL tasks demonstrate the effectiveness of VistaLLM by achieving consistent state-of-the-art performance over strong baselines across all downstream tasks. Our project page can be found at https://shramanpramanick.github.io/VistaLLM/.
Discovering environments with XRM
Sep 28, 2023Successful out-of-distribution generalization requires environment annotations. Unfortunately, these are resource-intensive to obtain, and their relevance to model performance is limited by the expectations and perceptual biases of human annotators. Therefore, to enable robust AI systems across applications, we must develop algorithms to automatically discover environments inducing broad generalization. Current proposals, which divide examples based on their training error, suffer from one fundamental problem. These methods add hyper-parameters and early-stopping criteria that are impossible to tune without a validation set with human-annotated environments, the very information subject to discovery. In this paper, we propose Cross-Risk-Minimization (XRM) to address this issue. XRM trains two twin networks, each learning from one random half of the training data, while imitating confident held-out mistakes made by its sibling. XRM provides a recipe for hyper-parameter tuning, does not require early-stopping, and can discover environments for all training and validation data. Domain generalization algorithms built on top of XRM environments achieve oracle worst-group-accuracy, solving a long-standing problem in out-of-distribution generalization.
Predicting masked tokens in stochastic locations improves masked image modeling
Jul 31, 2023
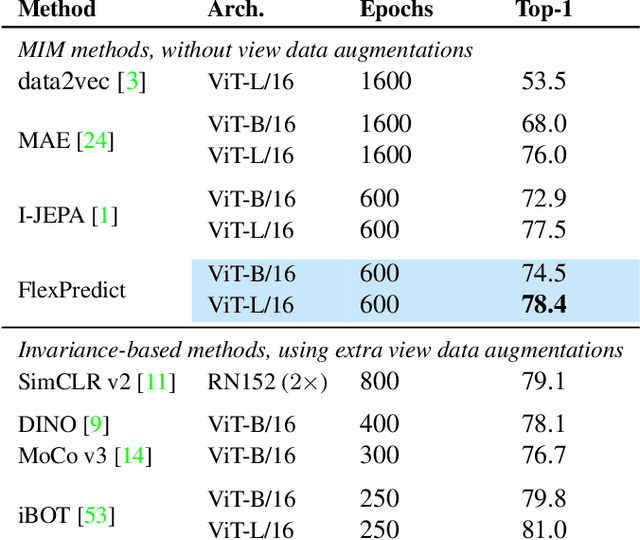
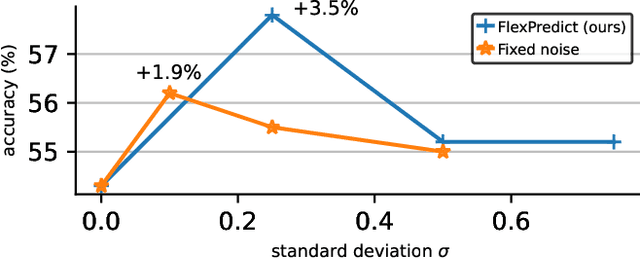
Self-supervised learning is a promising paradigm in deep learning that enables learning from unlabeled data by constructing pretext tasks that require learning useful representations. In natural language processing, the dominant pretext task has been masked language modeling (MLM), while in computer vision there exists an equivalent called Masked Image Modeling (MIM). However, MIM is challenging because it requires predicting semantic content in accurate locations. E.g, given an incomplete picture of a dog, we can guess that there is a tail, but we cannot determine its exact location. In this work, we propose FlexPredict, a stochastic model that addresses this challenge by incorporating location uncertainty into the model. Specifically, we condition the model on stochastic masked token positions to guide the model toward learning features that are more robust to location uncertainties. Our approach improves downstream performance on a range of tasks, e.g, compared to MIM baselines, FlexPredict boosts ImageNet linear probing by 1.6% with ViT-B and by 2.5% for semi-supervised video segmentation using ViT-L.
DINOv2: Learning Robust Visual Features without Supervision
Apr 14, 2023
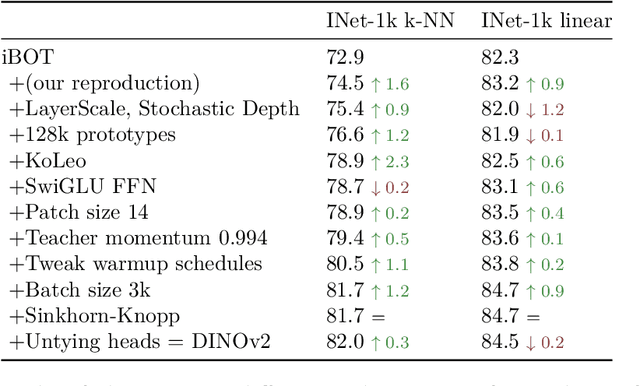
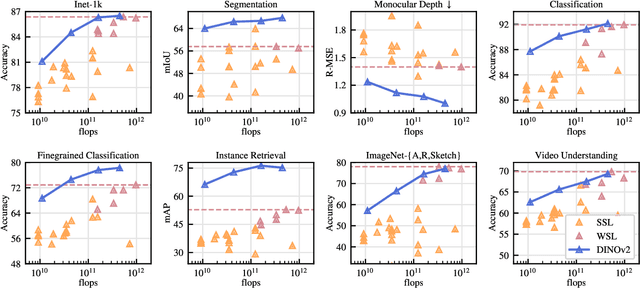
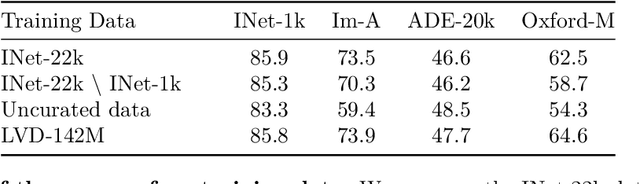
The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning. This work shows that existing pretraining methods, especially self-supervised methods, can produce such features if trained on enough curated data from diverse sources. We revisit existing approaches and combine different techniques to scale our pretraining in terms of data and model size. Most of the technical contributions aim at accelerating and stabilizing the training at scale. In terms of data, we propose an automatic pipeline to build a dedicated, diverse, and curated image dataset instead of uncurated data, as typically done in the self-supervised literature. In terms of models, we train a ViT model (Dosovitskiy et al., 2020) with 1B parameters and distill it into a series of smaller models that surpass the best available all-purpose features, OpenCLIP (Ilharco et al., 2021) on most of the benchmarks at image and pixel levels.
A surprisingly simple technique to control the pretraining bias for better transfer: Expand or Narrow your representation
Apr 11, 2023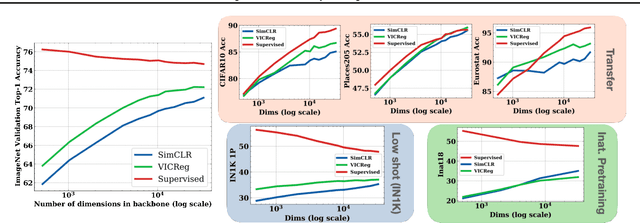

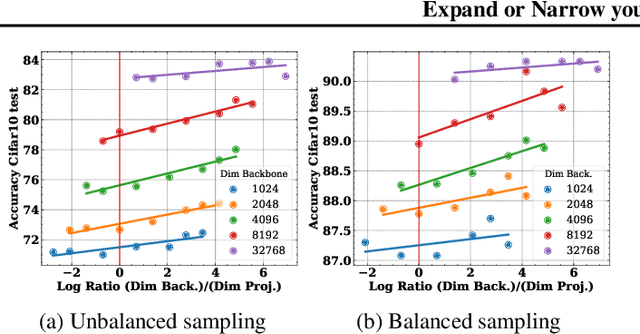
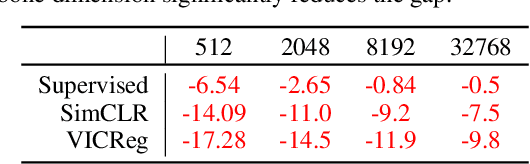
Self-Supervised Learning (SSL) models rely on a pretext task to learn representations. Because this pretext task differs from the downstream tasks used to evaluate the performance of these models, there is an inherent misalignment or pretraining bias. A commonly used trick in SSL, shown to make deep networks more robust to such bias, is the addition of a small projector (usually a 2 or 3 layer multi-layer perceptron) on top of a backbone network during training. In contrast to previous work that studied the impact of the projector architecture, we here focus on a simpler, yet overlooked lever to control the information in the backbone representation. We show that merely changing its dimensionality -- by changing only the size of the backbone's very last block -- is a remarkably effective technique to mitigate the pretraining bias. It significantly improves downstream transfer performance for both Self-Supervised and Supervised pretrained models.
A Simple Recipe for Competitive Low-compute Self supervised Vision Models
Jan 23, 2023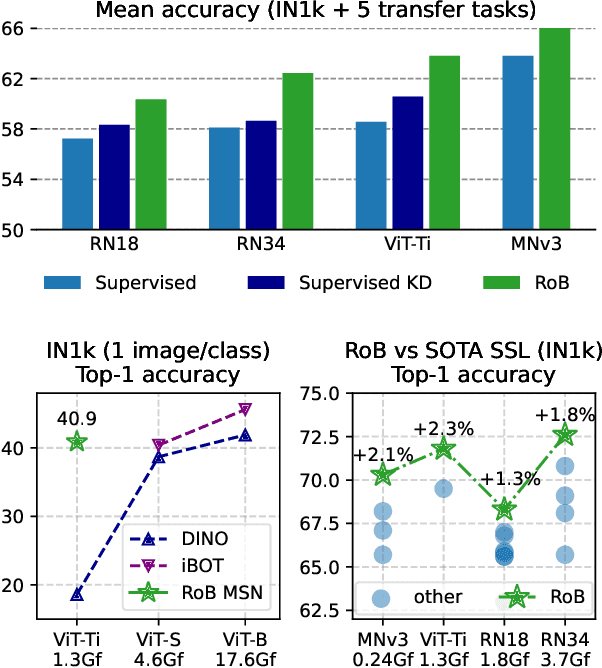
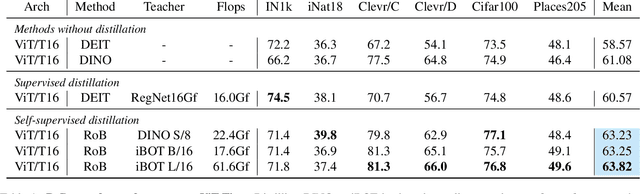
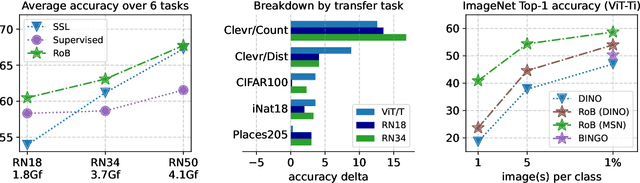
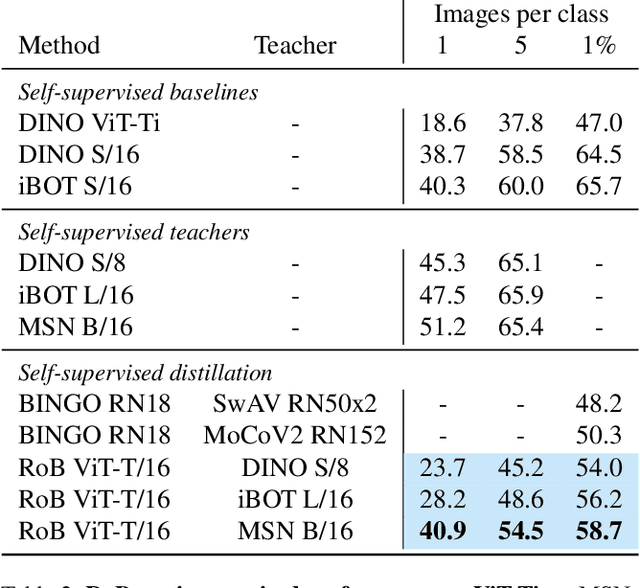
Self-supervised methods in vision have been mostly focused on large architectures as they seem to suffer from a significant performance drop for smaller architectures. In this paper, we propose a simple self-supervised distillation technique that can train high performance low-compute neural networks. Our main insight is that existing joint-embedding based SSL methods can be repurposed for knowledge distillation from a large self-supervised teacher to a small student model. Thus, we call our method Replace one Branch (RoB) as it simply replaces one branch of the joint-embedding training with a large teacher model. RoB is widely applicable to a number of architectures such as small ResNets, MobileNets and ViT, and pretrained models such as DINO, SwAV or iBOT. When pretraining on the ImageNet dataset, RoB yields models that compete with supervised knowledge distillation. When applied to MSN, RoB produces students with strong semi-supervised capabilities. Finally, our best ViT-Tiny models improve over prior SSL state-of-the-art on ImageNet by $2.3\%$ and are on par or better than a supervised distilled DeiT on five downstream transfer tasks (iNaturalist, CIFAR, Clevr/Count, Clevr/Dist and Places). We hope RoB enables practical self-supervision at smaller scale.
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Jan 19, 2023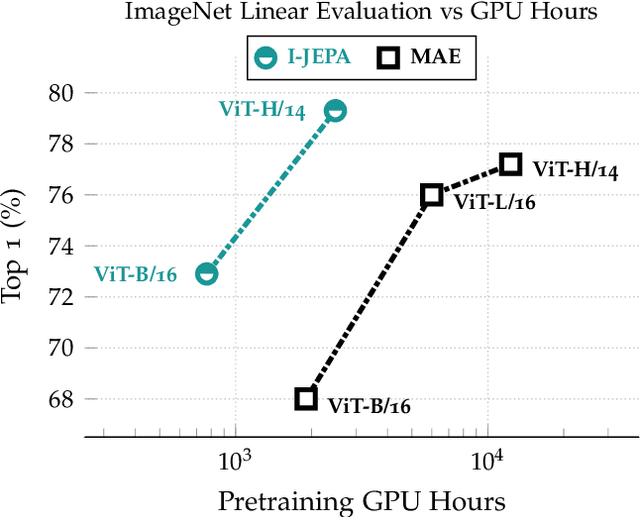
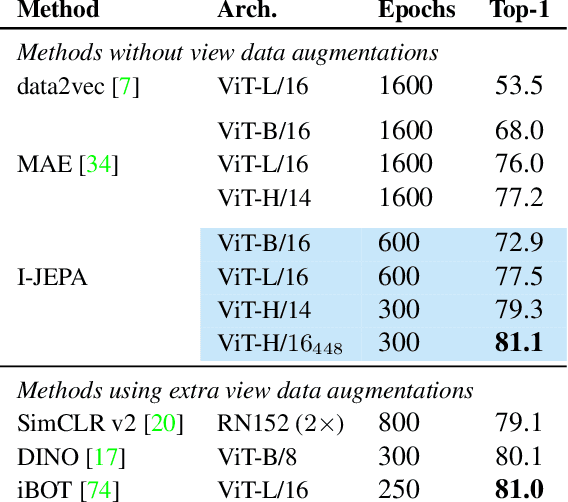


This paper demonstrates an approach for learning highly semantic image representations without relying on hand-crafted data-augmentations. We introduce the Image-based Joint-Embedding Predictive Architecture (I-JEPA), a non-generative approach for self-supervised learning from images. The idea behind I-JEPA is simple: from a single context block, predict the representations of various target blocks in the same image. A core design choice to guide I-JEPA towards producing semantic representations is the masking strategy; specifically, it is crucial to (a) predict several target blocks in the image, (b) sample target blocks with sufficiently large scale (occupying 15%-20% of the image), and (c) use a sufficiently informative (spatially distributed) context block. Empirically, when combined with Vision Transformers, we find I-JEPA to be highly scalable. For instance, we train a ViT-Huge/16 on ImageNet using 32 A100 GPUs in under 38 hours to achieve strong downstream performance across a wide range of tasks requiring various levels of abstraction, from linear classification to object counting and depth prediction.
Uniform Masking Prevails in Vision-Language Pretraining
Dec 10, 2022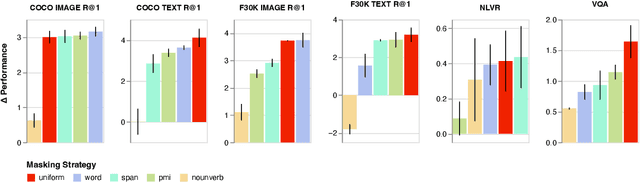
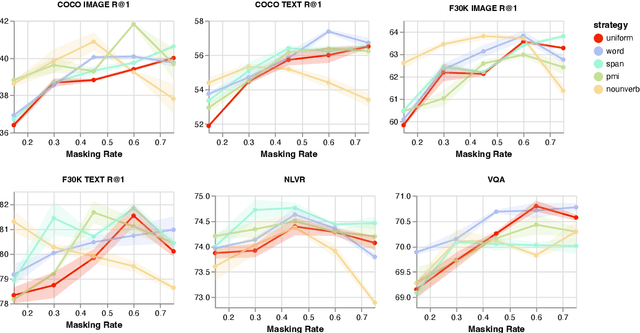
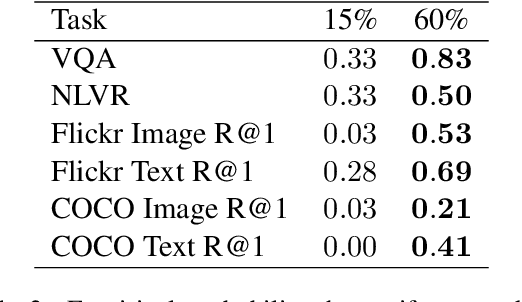
Masked Language Modeling (MLM) has proven to be an essential component of Vision-Language (VL) pretraining. To implement MLM, the researcher must make two design choices: the masking strategy, which determines which tokens to mask, and the masking rate, which determines how many tokens to mask. Previous work has focused primarily on the masking strategy while setting the masking rate at a default of 15\%. In this paper, we show that increasing this masking rate improves downstream performance while simultaneously reducing performance gap among different masking strategies, rendering the uniform masking strategy competitive to other more complex ones. Surprisingly, we also discover that increasing the masking rate leads to gains in Image-Text Matching (ITM) tasks, suggesting that the role of MLM goes beyond language modeling in VL pretraining.
ImageNet-X: Understanding Model Mistakes with Factor of Variation Annotations
Nov 03, 2022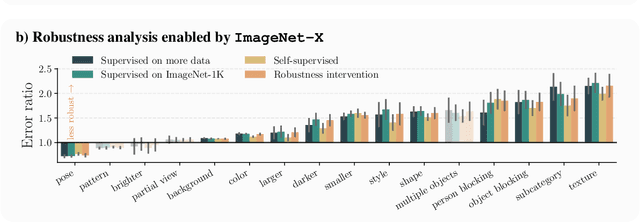
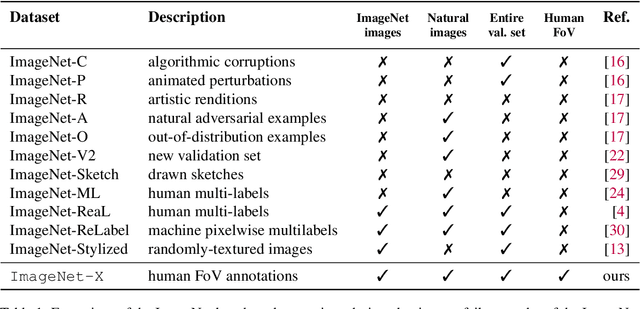
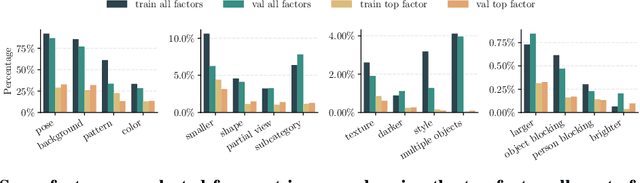
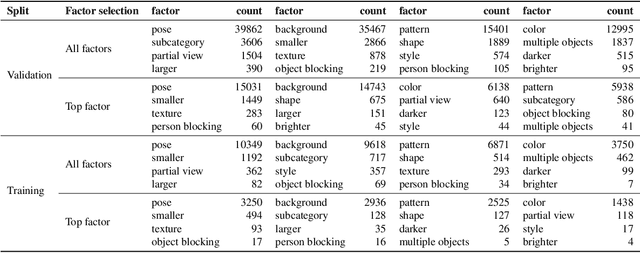
Deep learning vision systems are widely deployed across applications where reliability is critical. However, even today's best models can fail to recognize an object when its pose, lighting, or background varies. While existing benchmarks surface examples challenging for models, they do not explain why such mistakes arise. To address this need, we introduce ImageNet-X, a set of sixteen human annotations of factors such as pose, background, or lighting the entire ImageNet-1k validation set as well as a random subset of 12k training images. Equipped with ImageNet-X, we investigate 2,200 current recognition models and study the types of mistakes as a function of model's (1) architecture, e.g. transformer vs. convolutional, (2) learning paradigm, e.g. supervised vs. self-supervised, and (3) training procedures, e.g., data augmentation. Regardless of these choices, we find models have consistent failure modes across ImageNet-X categories. We also find that while data augmentation can improve robustness to certain factors, they induce spill-over effects to other factors. For example, strong random cropping hurts robustness on smaller objects. Together, these insights suggest to advance the robustness of modern vision models, future research should focus on collecting additional data and understanding data augmentation schemes. Along with these insights, we release a toolkit based on ImageNet-X to spur further study into the mistakes image recognition systems make.