 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVasu Sharma
Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
Mar 12, 2024
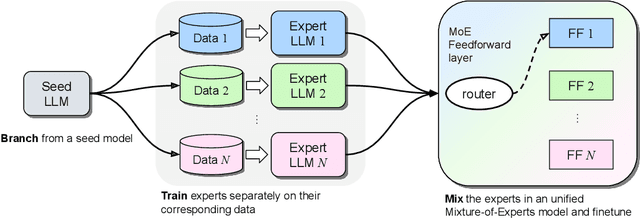
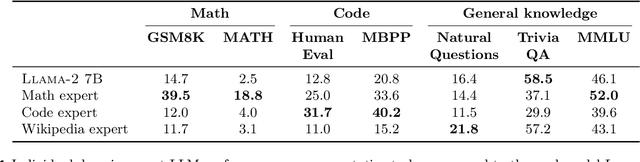
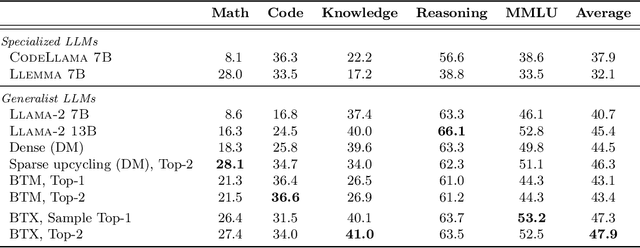
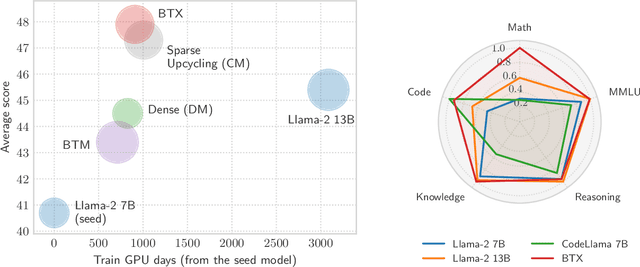
We investigate efficient methods for training Large Language Models (LLMs) to possess capabilities in multiple specialized domains, such as coding, math reasoning and world knowledge. Our method, named Branch-Train-MiX (BTX), starts from a seed model, which is branched to train experts in embarrassingly parallel fashion with high throughput and reduced communication cost. After individual experts are asynchronously trained, BTX brings together their feedforward parameters as experts in Mixture-of-Expert (MoE) layers and averages the remaining parameters, followed by an MoE-finetuning stage to learn token-level routing. BTX generalizes two special cases, the Branch-Train-Merge method, which does not have the MoE finetuning stage to learn routing, and sparse upcycling, which omits the stage of training experts asynchronously. Compared to alternative approaches, BTX achieves the best accuracy-efficiency tradeoff.
A Picture is Worth More Than 77 Text Tokens: Evaluating CLIP-Style Models on Dense Captions
Dec 14, 2023Curation methods for massive vision-language datasets trade off between dataset size and quality. However, even the highest quality of available curated captions are far too short to capture the rich visual detail in an image. To show the value of dense and highly-aligned image-text pairs, we collect the Densely Captioned Images (DCI) dataset, containing 8012 natural images human-annotated with mask-aligned descriptions averaging above 1000 words each. With precise and reliable captions associated with specific parts of an image, we can evaluate vision-language models' (VLMs) understanding of image content with a novel task that matches each caption with its corresponding subcrop. As current models are often limited to 77 text tokens, we also introduce a summarized version (sDCI) in which each caption length is limited. We show that modern techniques that make progress on standard benchmarks do not correspond with significant improvement on our sDCI based benchmark. Lastly, we finetune CLIP using sDCI and show significant improvements over the baseline despite a small training set. By releasing the first human annotated dense image captioning dataset, we hope to enable the development of new benchmarks or fine-tuning recipes for the next generation of VLMs to come.
E-ViLM: Efficient Video-Language Model via Masked Video Modeling with Semantic Vector-Quantized Tokenizer
Nov 28, 2023To build scalable models for challenging real-world tasks, it is important to learn from diverse, multi-modal data in various forms (e.g., videos, text, and images). Among the existing works, a plethora of them have focused on leveraging large but cumbersome cross-modal architectures. Regardless of their effectiveness, larger architectures unavoidably prevent the models from being extended to real-world applications, so building a lightweight VL architecture and an efficient learning schema is of great practical value. In this paper, we propose an Efficient Video-Language Model (dubbed as E-ViLM) and a masked video modeling (MVM) schema, assisted with a semantic vector-quantized tokenizer. In particular, our E-ViLM learns to reconstruct the semantic labels of masked video regions, produced by the pre-trained vector-quantized tokenizer, which discretizes the continuous visual signals into labels. We show that with our simple MVM task and regular VL pre-training modelings, our E-ViLM, despite its compactness, is able to learn expressive representations from Video-Language corpus and generalize well to extensive Video-Language tasks including video question answering, text-to-video retrieval, etc. In particular, our E-ViLM obtains obvious efficiency improvements by reaching competing performances with faster inference speed, i.e., our model reaches $39.3$% Top-$1$ accuracy on the MSRVTT benchmark, retaining $91.4$% of the accuracy of state-of-the-art larger VL architecture with only $15%$ parameters and $94.8%$ fewer GFLOPs. We also provide extensive ablative studies that validate the effectiveness of our proposed learning schema for E-ViLM.
FLAP: Fast Language-Audio Pre-training
Nov 02, 2023We propose Fast Language-Audio Pre-training (FLAP), a self-supervised approach that efficiently and effectively learns aligned audio and language representations through masking, contrastive learning and reconstruction. For efficiency, FLAP randomly drops audio spectrogram tokens, focusing solely on the remaining ones for self-supervision. Through inter-modal contrastive learning, FLAP learns to align paired audio and text representations in a shared latent space. Notably, FLAP leverages multiple augmented views via masking for inter-modal contrast and learns to reconstruct the masked portion of audio tokens. Moreover, FLAP leverages large language models (LLMs) to augment the text inputs, contributing to improved performance. These approaches lead to more robust and informative audio-text representations, enabling FLAP to achieve state-of-the-art (SoTA) performance on audio-text retrieval tasks on AudioCaps (achieving 53.0% R@1) and Clotho (achieving 25.5% R@1).
Demystifying CLIP Data
Oct 02, 2023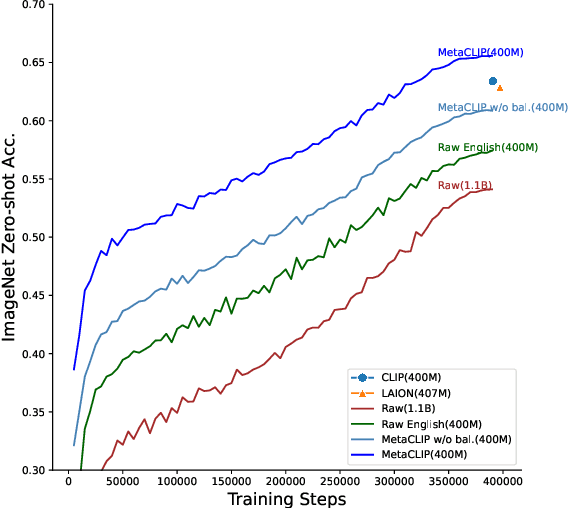

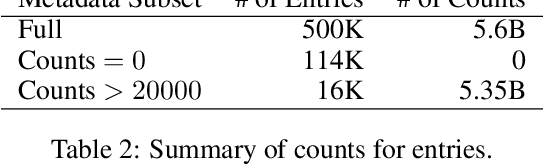
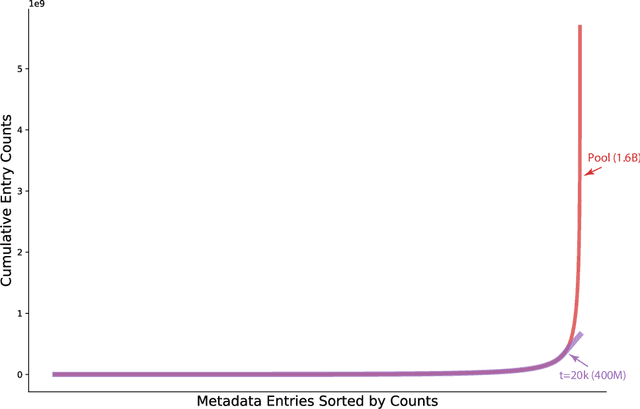
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at https://github.com/facebookresearch/MetaCLIP.
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
Sep 05, 2023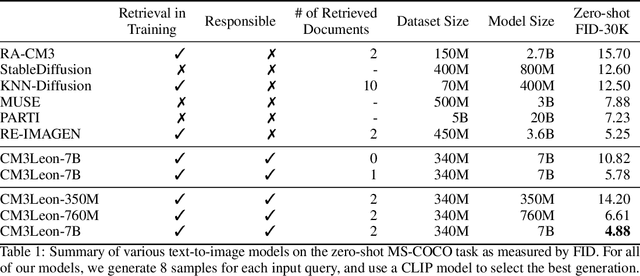

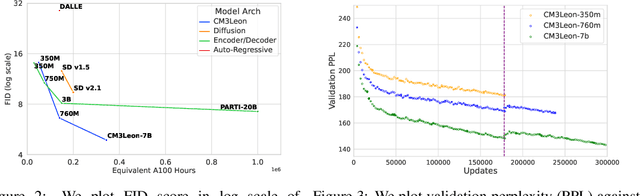

We present CM3Leon (pronounced "Chameleon"), a retrieval-augmented, token-based, decoder-only multi-modal language model capable of generating and infilling both text and images. CM3Leon uses the CM3 multi-modal architecture but additionally shows the extreme benefits of scaling up and tuning on more diverse instruction-style data. It is the first multi-modal model trained with a recipe adapted from text-only language models, including a large-scale retrieval-augmented pre-training stage and a second multi-task supervised fine-tuning (SFT) stage. It is also a general-purpose model that can do both text-to-image and image-to-text generation, allowing us to introduce self-contained contrastive decoding methods that produce high-quality outputs. Extensive experiments demonstrate that this recipe is highly effective for multi-modal models. CM3Leon achieves state-of-the-art performance in text-to-image generation with 5x less training compute than comparable methods (zero-shot MS-COCO FID of 4.88). After SFT, CM3Leon can also demonstrate unprecedented levels of controllability in tasks ranging from language-guided image editing to image-controlled generation and segmentation.
Alexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023

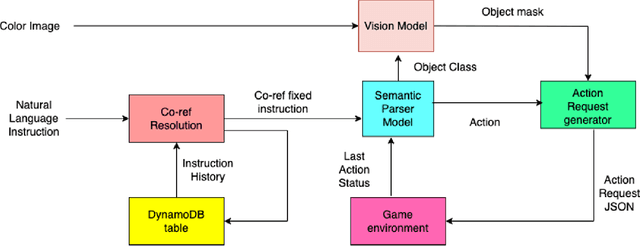

The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
DINOv2: Learning Robust Visual Features without Supervision
Apr 14, 2023
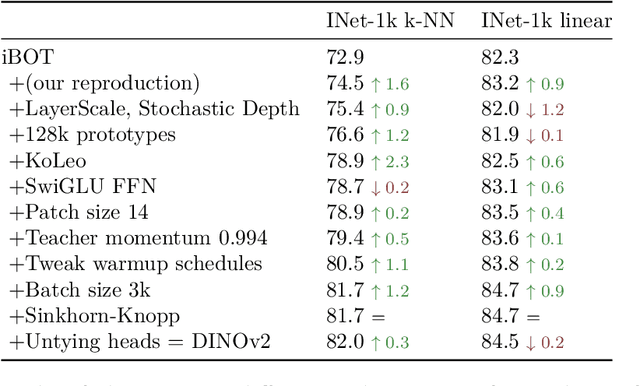
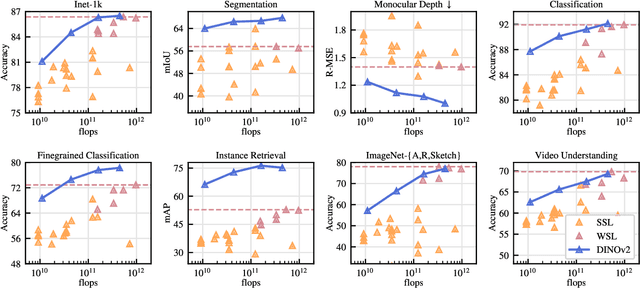
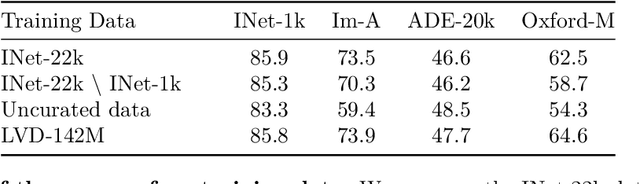
The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning. This work shows that existing pretraining methods, especially self-supervised methods, can produce such features if trained on enough curated data from diverse sources. We revisit existing approaches and combine different techniques to scale our pretraining in terms of data and model size. Most of the technical contributions aim at accelerating and stabilizing the training at scale. In terms of data, we propose an automatic pipeline to build a dedicated, diverse, and curated image dataset instead of uncurated data, as typically done in the self-supervised literature. In terms of models, we train a ViT model (Dosovitskiy et al., 2020) with 1B parameters and distill it into a series of smaller models that surpass the best available all-purpose features, OpenCLIP (Ilharco et al., 2021) on most of the benchmarks at image and pixel levels.
Alexa Arena: A User-Centric Interactive Platform for Embodied AI
Mar 02, 2023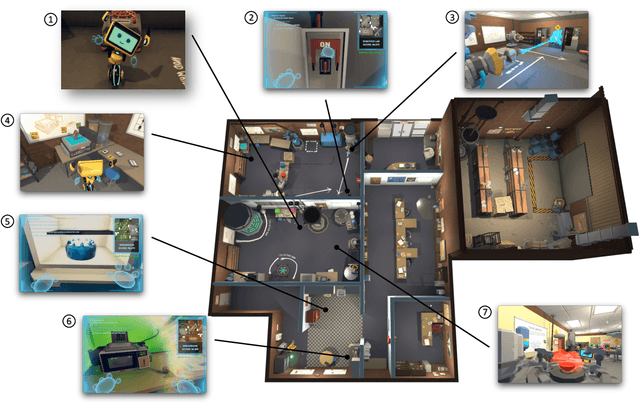
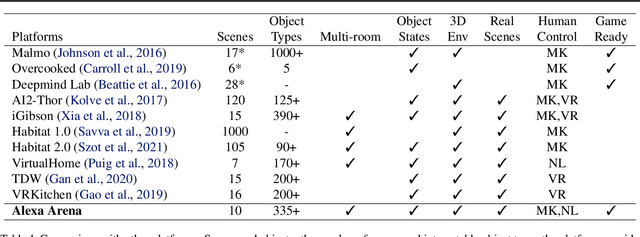
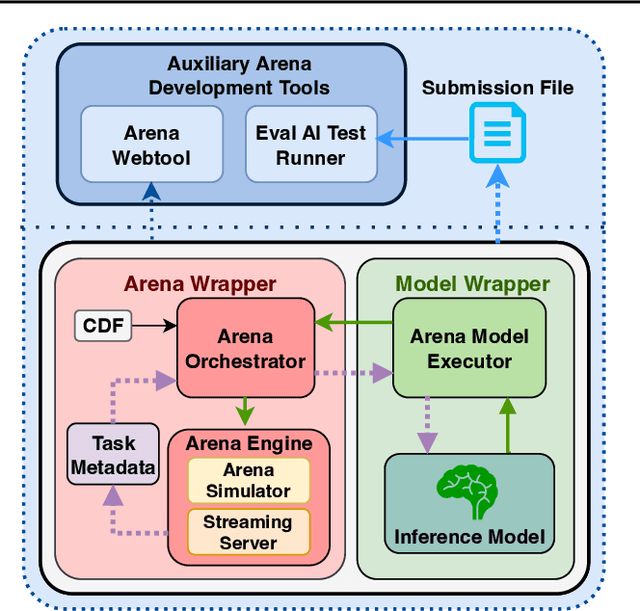
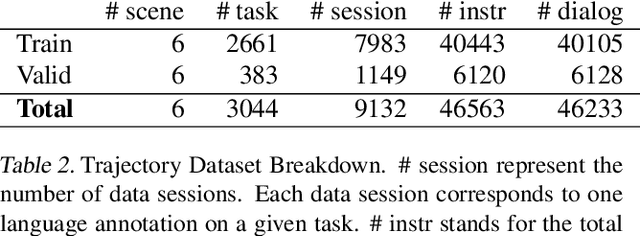
We introduce Alexa Arena, a user-centric simulation platform for Embodied AI (EAI) research. Alexa Arena provides a variety of multi-room layouts and interactable objects, for the creation of human-robot interaction (HRI) missions. With user-friendly graphics and control mechanisms, Alexa Arena supports the development of gamified robotic tasks readily accessible to general human users, thus opening a new venue for high-efficiency HRI data collection and EAI system evaluation. Along with the platform, we introduce a dialog-enabled instruction-following benchmark and provide baseline results for it. We make Alexa Arena publicly available to facilitate research in building generalizable and assistive embodied agents.
MAViL: Masked Audio-Video Learners
Dec 15, 2022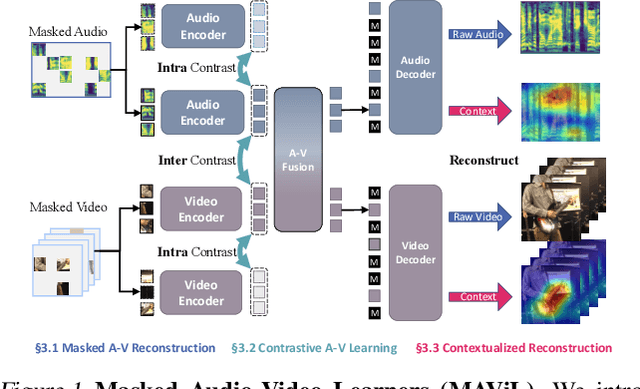



We present Masked Audio-Video Learners (MAViL) to train audio-visual representations. Our approach learns with three complementary forms of self-supervision: (1) reconstruction of masked audio and video input data, (2) intra- and inter-modal contrastive learning with masking, and (3) self-training by reconstructing joint audio-video contextualized features learned from the first two objectives. Pre-training with MAViL not only enables the model to perform well in audio-visual classification and retrieval tasks but also improves representations of each modality in isolation, without using information from the other modality for fine-tuning or inference. Empirically, MAViL sets a new state-of-the-art on AudioSet (53.1 mAP) and VGGSound (67.1% accuracy). For the first time, a self-supervised audio-visual model outperforms ones that use external supervision on these benchmarks. Code will be available soon.