 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThéo Moutakanni
Advancing human-centric AI for robust X-ray analysis through holistic self-supervised learning
May 02, 2024
AI Foundation models are gaining traction in various applications, including medical fields like radiology. However, medical foundation models are often tested on limited tasks, leaving their generalisability and biases unexplored. We present RayDINO, a large visual encoder trained by self-supervision on 873k chest X-rays. We compare RayDINO to previous state-of-the-art models across nine radiology tasks, from classification and dense segmentation to text generation, and provide an in depth analysis of population, age and sex biases of our model. Our findings suggest that self-supervision allows patient-centric AI proving useful in clinical workflows and interpreting X-rays holistically. With RayDINO and small task-specific adapters, we reach state-of-the-art results and improve generalization to unseen populations while mitigating bias, illustrating the true promise of foundation models: versatility and robustness.
DINOv2: Learning Robust Visual Features without Supervision
Apr 14, 2023
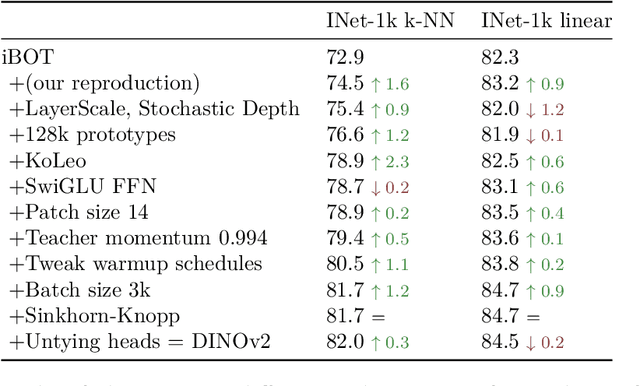
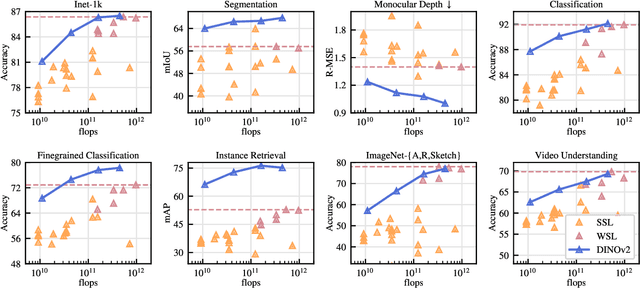
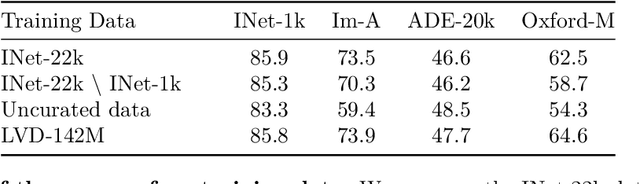
The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning. This work shows that existing pretraining methods, especially self-supervised methods, can produce such features if trained on enough curated data from diverse sources. We revisit existing approaches and combine different techniques to scale our pretraining in terms of data and model size. Most of the technical contributions aim at accelerating and stabilizing the training at scale. In terms of data, we propose an automatic pipeline to build a dedicated, diverse, and curated image dataset instead of uncurated data, as typically done in the self-supervised literature. In terms of models, we train a ViT model (Dosovitskiy et al., 2020) with 1B parameters and distill it into a series of smaller models that surpass the best available all-purpose features, OpenCLIP (Ilharco et al., 2021) on most of the benchmarks at image and pixel levels.