 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSer-Nam Lim
Spherical Linear Interpolation and Text-Anchoring for Zero-shot Composed Image Retrieval
May 01, 2024
Composed Image Retrieval (CIR) is a complex task that retrieves images using a query, which is configured with an image and a caption that describes desired modifications to that image. Supervised CIR approaches have shown strong performance, but their reliance on expensive manually-annotated datasets restricts their scalability and broader applicability. To address these issues, previous studies have proposed pseudo-word token-based Zero-Shot CIR (ZS-CIR) methods, which utilize a projection module to map images to word tokens. However, we conjecture that this approach has a downside: the projection module distorts the original image representation and confines the resulting composed embeddings to the text-side. In order to resolve this, we introduce a novel ZS-CIR method that uses Spherical Linear Interpolation (Slerp) to directly merge image and text representations by identifying an intermediate embedding of both. Furthermore, we introduce Text-Anchored-Tuning (TAT), a method that fine-tunes the image encoder while keeping the text encoder fixed. TAT closes the modality gap between images and text, making the Slerp process much more effective. Notably, the TAT method is not only efficient in terms of the scale of the training dataset and training time, but it also serves as an excellent initial checkpoint for training supervised CIR models, thereby highlighting its wider potential. The integration of the Slerp-based ZS-CIR with a TAT-tuned model enables our approach to deliver state-of-the-art retrieval performance across CIR benchmarks.
Visual Delta Generator with Large Multi-modal Models for Semi-supervised Composed Image Retrieval
Apr 23, 2024Composed Image Retrieval (CIR) is a task that retrieves images similar to a query, based on a provided textual modification. Current techniques rely on supervised learning for CIR models using labeled triplets of the reference image, text, target image. These specific triplets are not as commonly available as simple image-text pairs, limiting the widespread use of CIR and its scalability. On the other hand, zero-shot CIR can be relatively easily trained with image-caption pairs without considering the image-to-image relation, but this approach tends to yield lower accuracy. We propose a new semi-supervised CIR approach where we search for a reference and its related target images in auxiliary data and learn our large language model-based Visual Delta Generator (VDG) to generate text describing the visual difference (i.e., visual delta) between the two. VDG, equipped with fluent language knowledge and being model agnostic, can generate pseudo triplets to boost the performance of CIR models. Our approach significantly improves the existing supervised learning approaches and achieves state-of-the-art results on the CIR benchmarks.
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Apr 08, 2024With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
Mitigating Dialogue Hallucination for Large Multi-modal Models via Adversarial Instruction Tuning
Mar 15, 2024
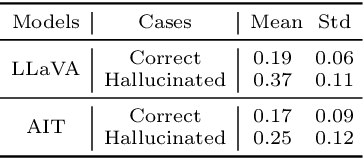
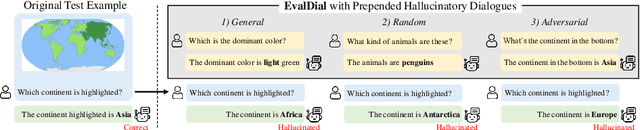
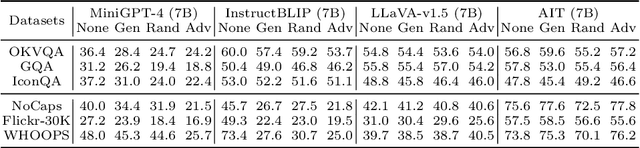
Mitigating hallucinations of Large Multi-modal Models(LMMs) is crucial to enhance their reliability for general-purpose assistants. This paper shows that such hallucinations of LMMs can be significantly exacerbated by preceding user-system dialogues. To precisely measure this, we first present an evaluation benchmark by extending popular multi-modal benchmark datasets with prepended hallucinatory dialogues generated by our novel Adversarial Question Generator, which can automatically generate image-related yet adversarial dialogues by adopting adversarial attacks on LMMs. On our benchmark, the zero-shot performance of state-of-the-art LMMs dropped significantly for both the VQA and Captioning tasks. Next, we further reveal this hallucination is mainly due to the prediction bias toward preceding dialogues rather than visual content. To reduce this bias, we propose Adversarial Instruction Tuning that robustly fine-tunes LMMs on augmented multi-modal instruction-following datasets with hallucinatory dialogues. Extensive experiments show that our proposed approach successfully reduces dialogue hallucination while maintaining or even improving performance.
Universal Pyramid Adversarial Training for Improved ViT Performance
Dec 26, 2023Recently, Pyramid Adversarial training (Herrmann et al., 2022) has been shown to be very effective for improving clean accuracy and distribution-shift robustness of vision transformers. However, due to the iterative nature of adversarial training, the technique is up to 7 times more expensive than standard training. To make the method more efficient, we propose Universal Pyramid Adversarial training, where we learn a single pyramid adversarial pattern shared across the whole dataset instead of the sample-wise patterns. With our proposed technique, we decrease the computational cost of Pyramid Adversarial training by up to 70% while retaining the majority of its benefit on clean performance and distribution-shift robustness. In addition, to the best of our knowledge, we are also the first to find that universal adversarial training can be leveraged to improve clean model performance.
Jack of All Tasks, Master of Many: Designing General-purpose Coarse-to-Fine Vision-Language Model
Dec 19, 2023The ability of large language models (LLMs) to process visual inputs has given rise to general-purpose vision systems, unifying various vision-language (VL) tasks by instruction tuning. However, due to the enormous diversity in input-output formats in the vision domain, existing general-purpose models fail to successfully integrate segmentation and multi-image inputs with coarse-level tasks into a single framework. In this work, we introduce VistaLLM, a powerful visual system that addresses coarse- and fine-grained VL tasks over single and multiple input images using a unified framework. VistaLLM utilizes an instruction-guided image tokenizer that filters global embeddings using task descriptions to extract compressed and refined features from numerous images. Moreover, VistaLLM employs a gradient-aware adaptive sampling technique to represent binary segmentation masks as sequences, significantly improving over previously used uniform sampling. To bolster the desired capability of VistaLLM, we curate CoinIt, a comprehensive coarse-to-fine instruction tuning dataset with 6.8M samples. We also address the lack of multi-image grounding datasets by introducing a novel task, AttCoSeg (Attribute-level Co-Segmentation), which boosts the model's reasoning and grounding capability over multiple input images. Extensive experiments on a wide range of V- and VL tasks demonstrate the effectiveness of VistaLLM by achieving consistent state-of-the-art performance over strong baselines across all downstream tasks. Our project page can be found at https://shramanpramanick.github.io/VistaLLM/.
Video Dynamics Prior: An Internal Learning Approach for Robust Video Enhancements
Dec 13, 2023In this paper, we present a novel robust framework for low-level vision tasks, including denoising, object removal, frame interpolation, and super-resolution, that does not require any external training data corpus. Our proposed approach directly learns the weights of neural modules by optimizing over the corrupted test sequence, leveraging the spatio-temporal coherence and internal statistics of videos. Furthermore, we introduce a novel spatial pyramid loss that leverages the property of spatio-temporal patch recurrence in a video across the different scales of the video. This loss enhances robustness to unstructured noise in both the spatial and temporal domains. This further results in our framework being highly robust to degradation in input frames and yields state-of-the-art results on downstream tasks such as denoising, object removal, and frame interpolation. To validate the effectiveness of our approach, we conduct qualitative and quantitative evaluations on standard video datasets such as DAVIS, UCF-101, and VIMEO90K-T.
On the Robustness of Large Multimodal Models Against Image Adversarial Attacks
Dec 08, 2023Recent advances in instruction tuning have led to the development of State-of-the-Art Large Multimodal Models (LMMs). Given the novelty of these models, the impact of visual adversarial attacks on LMMs has not been thoroughly examined. We conduct a comprehensive study of the robustness of various LMMs against different adversarial attacks, evaluated across tasks including image classification, image captioning, and Visual Question Answer (VQA). We find that in general LMMs are not robust to visual adversarial inputs. However, our findings suggest that context provided to the model via prompts, such as questions in a QA pair helps to mitigate the effects of visual adversarial inputs. Notably, the LMMs evaluated demonstrated remarkable resilience to such attacks on the ScienceQA task with only an 8.10% drop in performance compared to their visual counterparts which dropped 99.73%. We also propose a new approach to real-world image classification which we term query decomposition. By incorporating existence queries into our input prompt we observe diminished attack effectiveness and improvements in image classification accuracy. This research highlights a previously under-explored facet of LMM robustness and sets the stage for future work aimed at strengthening the resilience of multimodal systems in adversarial environments.
Object Recognition as Next Token Prediction
Dec 04, 2023We present an approach to pose object recognition as next token prediction. The idea is to apply a language decoder that auto-regressively predicts the text tokens from image embeddings to form labels. To ground this prediction process in auto-regression, we customize a non-causal attention mask for the decoder, incorporating two key features: modeling tokens from different labels to be independent, and treating image tokens as a prefix. This masking mechanism inspires an efficient method - one-shot sampling - to simultaneously sample tokens of multiple labels in parallel and rank generated labels by their probabilities during inference. To further enhance the efficiency, we propose a simple strategy to construct a compact decoder by simply discarding the intermediate blocks of a pretrained language model. This approach yields a decoder that matches the full model's performance while being notably more efficient. The code is available at https://github.com/kaiyuyue/nxtp
CLAMP: Contrastive LAnguage Model Prompt-tuning
Dec 04, 2023Large language models (LLMs) have emerged as powerful general-purpose interfaces for many machine learning problems. Recent work has adapted LLMs to generative visual tasks like image captioning, visual question answering, and visual chat, using a relatively small amount of instruction-tuning data. In this paper, we explore whether modern LLMs can also be adapted to classifying an image into a set of categories. First, we evaluate multimodal LLMs that are tuned for generative tasks on zero-shot image classification and find that their performance is far below that of specialized models like CLIP. We then propose an approach for light fine-tuning of LLMs using the same contrastive image-caption matching objective as CLIP. Our results show that LLMs can, indeed, achieve good image classification performance when adapted this way. Our approach beats state-of-the-art mLLMs by 13% and slightly outperforms contrastive learning with a custom text model, while also retaining the LLM's generative abilities. LLM initialization appears to particularly help classification in domains under-represented in the visual pre-training data.