 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXimeng Sun
Koala: Key frame-conditioned long video-LLM
Apr 05, 2024

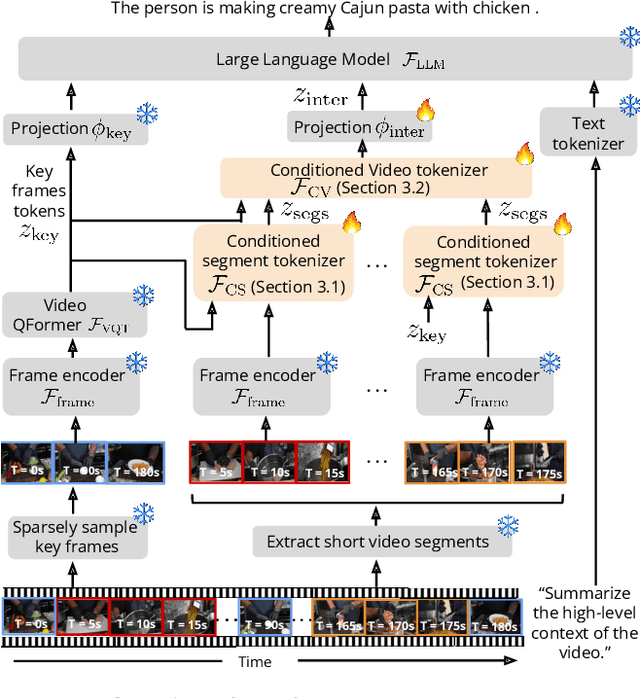


Long video question answering is a challenging task that involves recognizing short-term activities and reasoning about their fine-grained relationships. State-of-the-art video Large Language Models (vLLMs) hold promise as a viable solution due to their demonstrated emergent capabilities on new tasks. However, despite being trained on millions of short seconds-long videos, vLLMs are unable to understand minutes-long videos and accurately answer questions about them. To address this limitation, we propose a lightweight and self-supervised approach, Key frame-conditioned long video-LLM (Koala), that introduces learnable spatiotemporal queries to adapt pretrained vLLMs for generalizing to longer videos. Our approach introduces two new tokenizers that condition on visual tokens computed from sparse video key frames for understanding short and long video moments. We train our proposed approach on HowTo100M and demonstrate its effectiveness on zero-shot long video understanding benchmarks, where it outperforms state-of-the-art large models by 3 - 6% in absolute accuracy across all tasks. Surprisingly, we also empirically show that our approach not only helps a pretrained vLLM to understand long videos but also improves its accuracy on short-term action recognition.
CLAMP: Contrastive LAnguage Model Prompt-tuning
Dec 04, 2023Large language models (LLMs) have emerged as powerful general-purpose interfaces for many machine learning problems. Recent work has adapted LLMs to generative visual tasks like image captioning, visual question answering, and visual chat, using a relatively small amount of instruction-tuning data. In this paper, we explore whether modern LLMs can also be adapted to classifying an image into a set of categories. First, we evaluate multimodal LLMs that are tuned for generative tasks on zero-shot image classification and find that their performance is far below that of specialized models like CLIP. We then propose an approach for light fine-tuning of LLMs using the same contrastive image-caption matching objective as CLIP. Our results show that LLMs can, indeed, achieve good image classification performance when adapted this way. Our approach beats state-of-the-art mLLMs by 13% and slightly outperforms contrastive learning with a custom text model, while also retaining the LLM's generative abilities. LLM initialization appears to particularly help classification in domains under-represented in the visual pre-training data.
Label Budget Allocation in Multi-Task Learning
Aug 24, 2023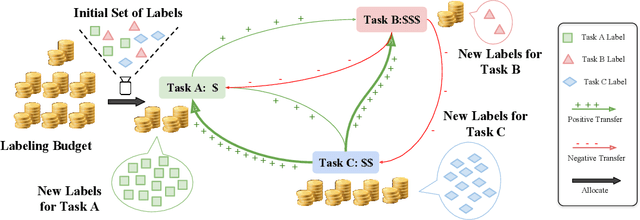
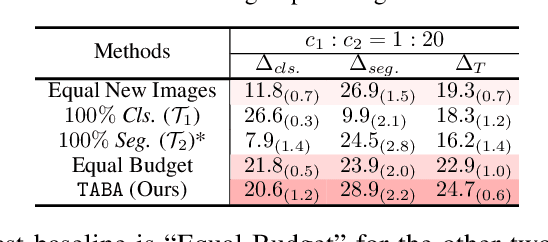
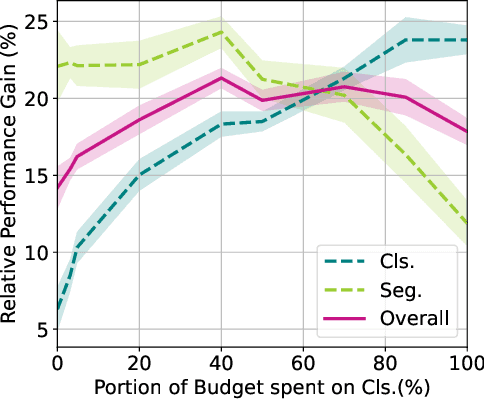
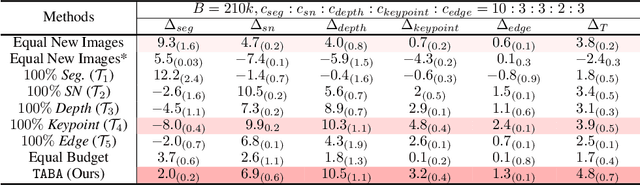
The cost of labeling data often limits the performance of machine learning systems. In multi-task learning, related tasks provide information to each other and improve overall performance, but the label cost can vary among tasks. How should the label budget (i.e. the amount of money spent on labeling) be allocated among different tasks to achieve optimal multi-task performance? We are the first to propose and formally define the label budget allocation problem in multi-task learning and to empirically show that different budget allocation strategies make a big difference to its performance. We propose a Task-Adaptive Budget Allocation algorithm to robustly generate the optimal budget allocation adaptive to different multi-task learning settings. Specifically, we estimate and then maximize the extent of new information obtained from the allocated budget as a proxy for multi-task learning performance. Experiments on PASCAL VOC and Taskonomy demonstrate the efficacy of our approach over other widely used heuristic labeling strategies.
DualCoOp++: Fast and Effective Adaptation to Multi-Label Recognition with Limited Annotations
Aug 03, 2023
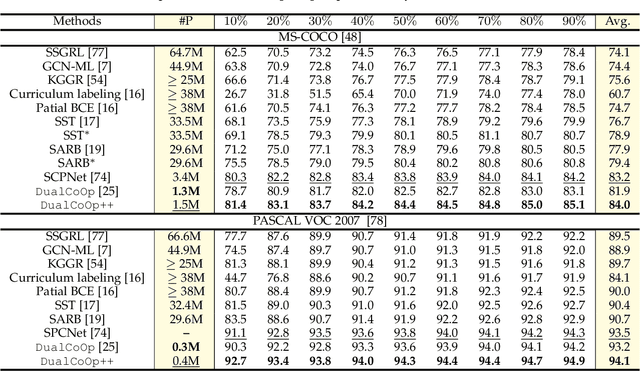
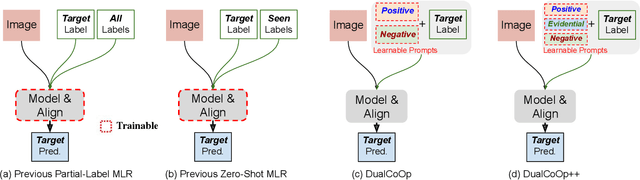
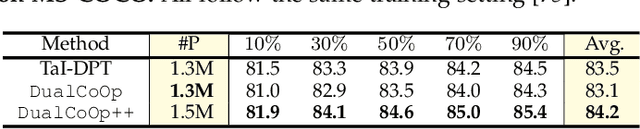
Multi-label image recognition in the low-label regime is a task of great challenge and practical significance. Previous works have focused on learning the alignment between textual and visual spaces to compensate for limited image labels, yet may suffer from reduced accuracy due to the scarcity of high-quality multi-label annotations. In this research, we leverage the powerful alignment between textual and visual features pretrained with millions of auxiliary image-text pairs. We introduce an efficient and effective framework called Evidence-guided Dual Context Optimization (DualCoOp++), which serves as a unified approach for addressing partial-label and zero-shot multi-label recognition. In DualCoOp++ we separately encode evidential, positive, and negative contexts for target classes as parametric components of the linguistic input (i.e., prompts). The evidential context aims to discover all the related visual content for the target class, and serves as guidance to aggregate positive and negative contexts from the spatial domain of the image, enabling better distinguishment between similar categories. Additionally, we introduce a Winner-Take-All module that promotes inter-class interaction during training, while avoiding the need for extra parameters and costs. As DualCoOp++ imposes minimal additional learnable overhead on the pretrained vision-language framework, it enables rapid adaptation to multi-label recognition tasks with limited annotations and even unseen classes. Experiments on standard multi-label recognition benchmarks across two challenging low-label settings demonstrate the superior performance of our approach compared to state-of-the-art methods.
DIME-FM: DIstilling Multimodal and Efficient Foundation Models
Mar 31, 2023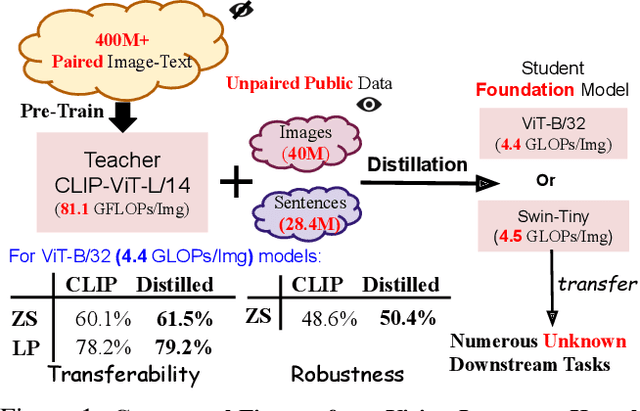

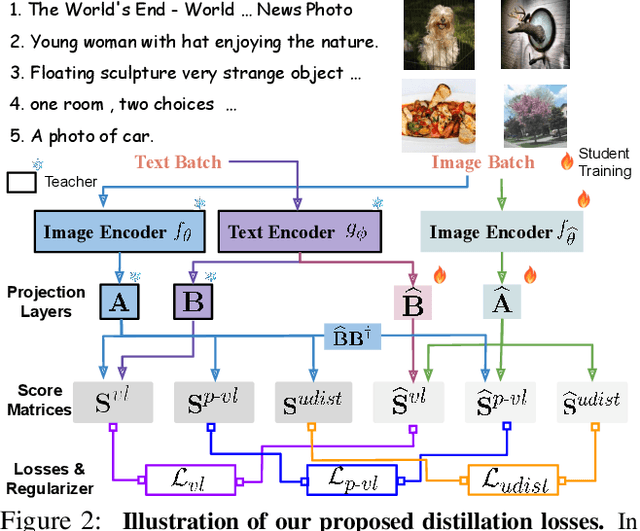
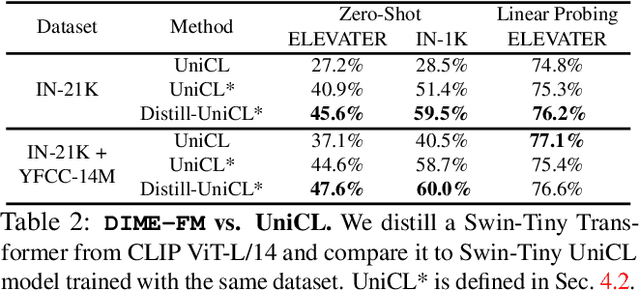
Large Vision-Language Foundation Models (VLFM), such as CLIP, ALIGN and Florence, are trained on large-scale datasets of image-caption pairs and achieve superior transferability and robustness on downstream tasks, but they are difficult to use in many practical applications due to their large size, high latency and fixed architectures. Unfortunately, recent work shows training a small custom VLFM for resource-limited applications is currently very difficult using public and smaller-scale data. In this paper, we introduce a new distillation mechanism (DIME-FM) that allows us to transfer the knowledge contained in large VLFMs to smaller, customized foundation models using a relatively small amount of inexpensive, unpaired images and sentences. We transfer the knowledge from the pre-trained CLIP-ViTL/14 model to a ViT-B/32 model, with only 40M public images and 28.4M unpaired public sentences. The resulting model "Distill-ViT-B/32" rivals the CLIP-ViT-B/32 model pre-trained on its private WiT dataset (400M image-text pairs): Distill-ViT-B/32 achieves similar results in terms of zero-shot and linear-probing performance on both ImageNet and the ELEVATER (20 image classification tasks) benchmarks. It also displays comparable robustness when evaluated on five datasets with natural distribution shifts from ImageNet.
DualCoOp: Fast Adaptation to Multi-Label Recognition with Limited Annotations
Jun 20, 2022
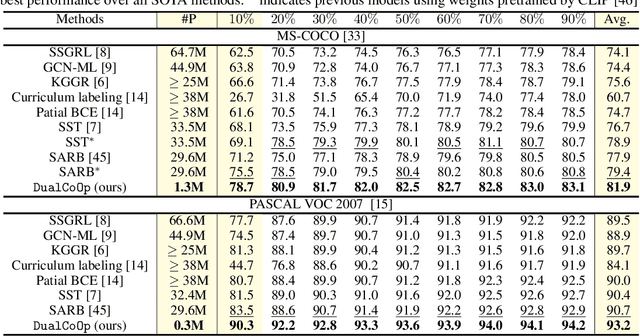
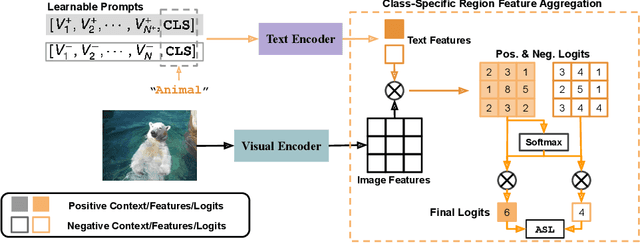
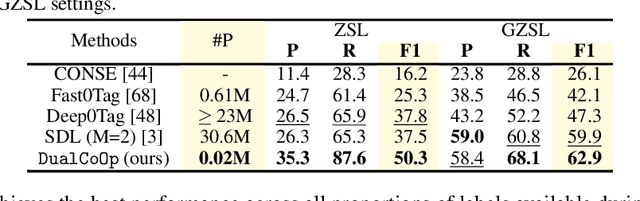
Solving multi-label recognition (MLR) for images in the low-label regime is a challenging task with many real-world applications. Recent work learns an alignment between textual and visual spaces to compensate for insufficient image labels, but loses accuracy because of the limited amount of available MLR annotations. In this work, we utilize the strong alignment of textual and visual features pretrained with millions of auxiliary image-text pairs and propose Dual Context Optimization (DualCoOp) as a unified framework for partial-label MLR and zero-shot MLR. DualCoOp encodes positive and negative contexts with class names as part of the linguistic input (i.e. prompts). Since DualCoOp only introduces a very light learnable overhead upon the pretrained vision-language framework, it can quickly adapt to multi-label recognition tasks that have limited annotations and even unseen classes. Experiments on standard multi-label recognition benchmarks across two challenging low-label settings demonstrate the advantages of our approach over state-of-the-art methods.
Dynamic Network Quantization for Efficient Video Inference
Aug 23, 2021
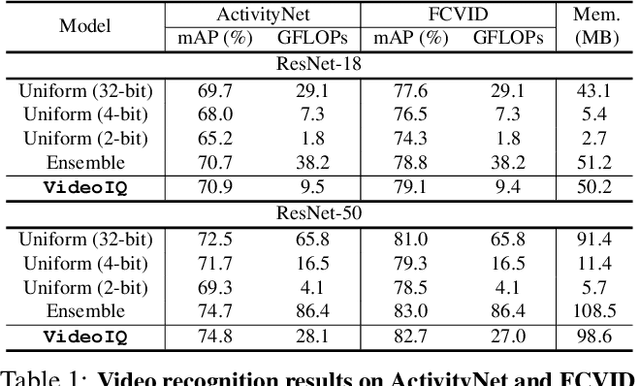
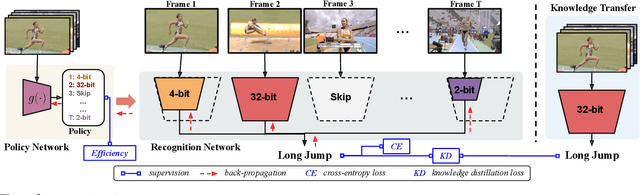
Deep convolutional networks have recently achieved great success in video recognition, yet their practical realization remains a challenge due to the large amount of computational resources required to achieve robust recognition. Motivated by the effectiveness of quantization for boosting efficiency, in this paper, we propose a dynamic network quantization framework, that selects optimal precision for each frame conditioned on the input for efficient video recognition. Specifically, given a video clip, we train a very lightweight network in parallel with the recognition network, to produce a dynamic policy indicating which numerical precision to be used per frame in recognizing videos. We train both networks effectively using standard backpropagation with a loss to achieve both competitive performance and resource efficiency required for video recognition. Extensive experiments on four challenging diverse benchmark datasets demonstrate that our proposed approach provides significant savings in computation and memory usage while outperforming the existing state-of-the-art methods.
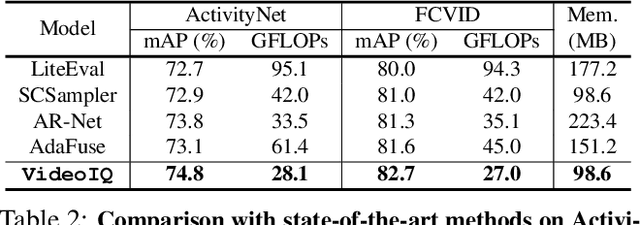
AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition
May 12, 2021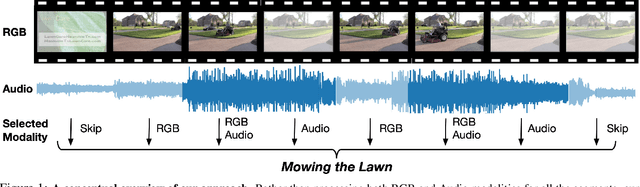

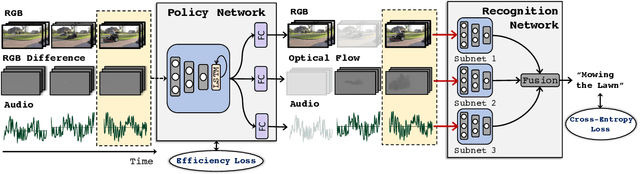
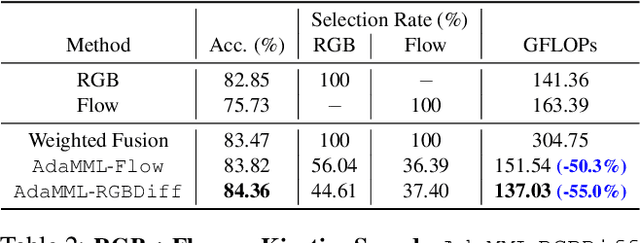
Multi-modal learning, which focuses on utilizing various modalities to improve the performance of a model, is widely used in video recognition. While traditional multi-modal learning offers excellent recognition results, its computational expense limits its impact for many real-world applications. In this paper, we propose an adaptive multi-modal learning framework, called AdaMML, that selects on-the-fly the optimal modalities for each segment conditioned on the input for efficient video recognition. Specifically, given a video segment, a multi-modal policy network is used to decide what modalities should be used for processing by the recognition model, with the goal of improving both accuracy and efficiency. We efficiently train the policy network jointly with the recognition model using standard back-propagation. Extensive experiments on four challenging diverse datasets demonstrate that our proposed adaptive approach yields 35%-55% reduction in computation when compared to the traditional baseline that simply uses all the modalities irrespective of the input, while also achieving consistent improvements in accuracy over the state-of-the-art methods.
All at Once Network Quantization via Collaborative Knowledge Transfer
Mar 02, 2021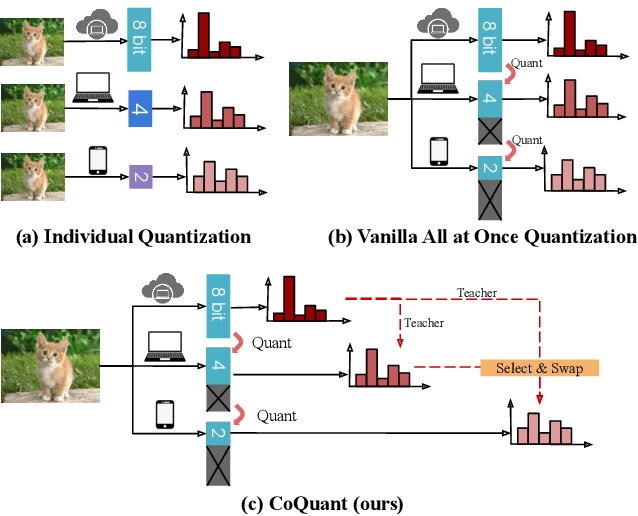
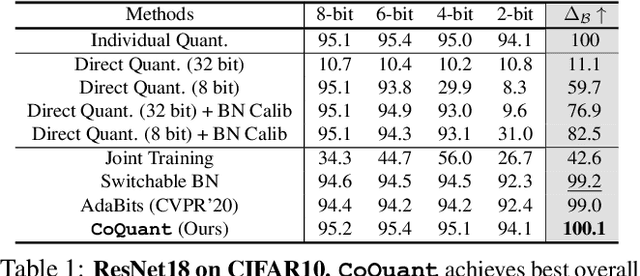

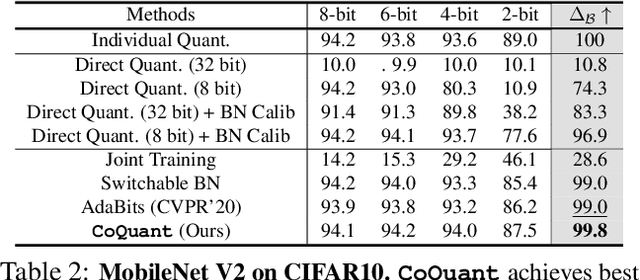
Network quantization has rapidly become one of the most widely used methods to compress and accelerate deep neural networks on edge devices. While existing approaches offer impressive results on common benchmark datasets, they generally repeat the quantization process and retrain the low-precision network from scratch, leading to different networks tailored for different resource constraints. This limits scalable deployment of deep networks in many real-world applications, where in practice dynamic changes in bit-width are often desired. All at Once quantization addresses this problem, by flexibly adjusting the bit-width of a single deep network during inference, without requiring re-training or additional memory to store separate models, for instant adaptation in different scenarios. In this paper, we develop a novel collaborative knowledge transfer approach for efficiently training the all-at-once quantization network. Specifically, we propose an adaptive selection strategy to choose a high-precision \enquote{teacher} for transferring knowledge to the low-precision student while jointly optimizing the model with all bit-widths. Furthermore, to effectively transfer knowledge, we develop a dynamic block swapping method by randomly replacing the blocks in the lower-precision student network with the corresponding blocks in the higher-precision teacher network. Extensive experiments on several challenging and diverse datasets for both image and video classification well demonstrate the efficacy of our proposed approach over state-of-the-art methods.
Revisiting Few-shot Activity Detection with Class Similarity Control
Mar 31, 2020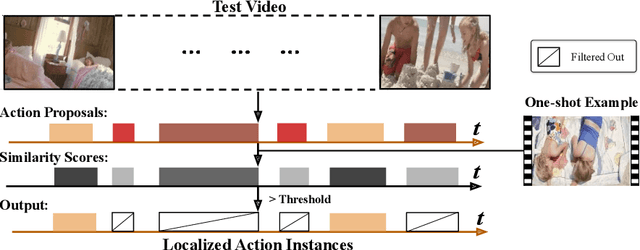
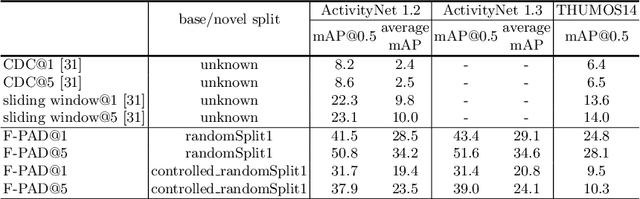


Many interesting events in the real world are rare making preannotated machine learning ready videos a rarity in consequence. Thus, temporal activity detection models that are able to learn from a few examples are desirable. In this paper, we present a conceptually simple and general yet novel framework for few-shot temporal activity detection based on proposal regression which detects the start and end time of the activities in untrimmed videos. Our model is end-to-end trainable, takes into account the frame rate differences between few-shot activities and untrimmed test videos, and can benefit from additional few-shot examples. We experiment on three large scale benchmarks for temporal activity detection (ActivityNet1.2, ActivityNet1.3 and THUMOS14 datasets) in a few-shot setting. We also study the effect on performance of different amount of overlap with activities used to pretrain the video classification backbone and propose corrective measures for future works in this domain. Our code will be made available.