 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKate Saenko
Koala: Key frame-conditioned long video-LLM
Apr 19, 2024
Long video question answering is a challenging task that involves recognizing short-term activities and reasoning about their fine-grained relationships. State-of-the-art video Large Language Models (vLLMs) hold promise as a viable solution due to their demonstrated emergent capabilities on new tasks. However, despite being trained on millions of short seconds-long videos, vLLMs are unable to understand minutes-long videos and accurately answer questions about them. To address this limitation, we propose a lightweight and self-supervised approach, Key frame-conditioned long video-LLM (Koala), that introduces learnable spatiotemporal queries to adapt pretrained vLLMs for generalizing to longer videos. Our approach introduces two new tokenizers that condition on visual tokens computed from sparse video key frames for understanding short and long video moments. We train our proposed approach on HowTo100M and demonstrate its effectiveness on zero-shot long video understanding benchmarks, where it outperforms state-of-the-art large models by 3 - 6% in absolute accuracy across all tasks. Surprisingly, we also empirically show that our approach not only helps a pretrained vLLM to understand long videos but also improves its accuracy on short-term action recognition.
Vision-LLMs Can Fool Themselves with Self-Generated Typographic Attacks
Feb 01, 2024Recently, significant progress has been made on Large Vision-Language Models (LVLMs); a new class of VL models that make use of large pre-trained language models. Yet, their vulnerability to Typographic attacks, which involve superimposing misleading text onto an image remain unstudied. Furthermore, prior work typographic attacks rely on sampling a random misleading class from a predefined set of classes. However, the random chosen class might not be the most effective attack. To address these issues, we first introduce a novel benchmark uniquely designed to test LVLMs vulnerability to typographic attacks. Furthermore, we introduce a new and more effective typographic attack: Self-Generated typographic attacks. Indeed, our method, given an image, make use of the strong language capabilities of models like GPT-4V by simply prompting them to recommend a typographic attack. Using our novel benchmark, we uncover that typographic attacks represent a significant threat against LVLM(s). Furthermore, we uncover that typographic attacks recommended by GPT-4V using our new method are not only more effective against GPT-4V itself compared to prior work attacks, but also against a host of less capable yet popular open source models like LLaVA, InstructBLIP, and MiniGPT4.
SynCDR : Training Cross Domain Retrieval Models with Synthetic Data
Dec 31, 2023In cross-domain retrieval, a model is required to identify images from the same semantic category across two visual domains. For instance, given a sketch of an object, a model needs to retrieve a real image of it from an online store's catalog. A standard approach for such a problem is learning a feature space of images where Euclidean distances reflect similarity. Even without human annotations, which may be expensive to acquire, prior methods function reasonably well using unlabeled images for training. Our problem constraint takes this further to scenarios where the two domains do not necessarily share any common categories in training data. This can occur when the two domains in question come from different versions of some biometric sensor recording identities of different people. We posit a simple solution, which is to generate synthetic data to fill in these missing category examples across domains. This, we do via category preserving translation of images from one visual domain to another. We compare approaches specifically trained for this translation for a pair of domains, as well as those that can use large-scale pre-trained text-to-image diffusion models via prompts, and find that the latter can generate better replacement synthetic data, leading to more accurate cross-domain retrieval models. Code for our work is available at https://github.com/samarth4149/SynCDR .
CLAMP: Contrastive LAnguage Model Prompt-tuning
Dec 04, 2023Large language models (LLMs) have emerged as powerful general-purpose interfaces for many machine learning problems. Recent work has adapted LLMs to generative visual tasks like image captioning, visual question answering, and visual chat, using a relatively small amount of instruction-tuning data. In this paper, we explore whether modern LLMs can also be adapted to classifying an image into a set of categories. First, we evaluate multimodal LLMs that are tuned for generative tasks on zero-shot image classification and find that their performance is far below that of specialized models like CLIP. We then propose an approach for light fine-tuning of LLMs using the same contrastive image-caption matching objective as CLIP. Our results show that LLMs can, indeed, achieve good image classification performance when adapted this way. Our approach beats state-of-the-art mLLMs by 13% and slightly outperforms contrastive learning with a custom text model, while also retaining the LLM's generative abilities. LLM initialization appears to particularly help classification in domains under-represented in the visual pre-training data.
Learning to Compose SuperWeights for Neural Parameter Allocation Search
Dec 03, 2023Neural parameter allocation search (NPAS) automates parameter sharing by obtaining weights for a network given an arbitrary, fixed parameter budget. Prior work has two major drawbacks we aim to address. First, there is a disconnect in the sharing pattern between the search and training steps, where weights are warped for layers of different sizes during the search to measure similarity, but not during training, resulting in reduced performance. To address this, we generate layer weights by learning to compose sets of SuperWeights, which represent a group of trainable parameters. These SuperWeights are created to be large enough so they can be used to represent any layer in the network, but small enough that they are computationally efficient. The second drawback we address is the method of measuring similarity between shared parameters. Whereas prior work compared the weights themselves, we argue this does not take into account the amount of conflict between the shared weights. Instead, we use gradient information to identify layers with shared weights that wish to diverge from each other. We demonstrate that our SuperWeight Networks consistently boost performance over the state-of-the-art on the ImageNet and CIFAR datasets in the NPAS setting. We further show that our approach can generate parameters for many network architectures using the same set of weights. This enables us to support tasks like efficient ensembling and anytime prediction, outperforming fully-parameterized ensembles with 17% fewer parameters.
Lasagna: Layered Score Distillation for Disentangled Object Relighting
Nov 30, 2023Professional artists, photographers, and other visual content creators use object relighting to establish their photo's desired effect. Unfortunately, manual tools that allow relighting have a steep learning curve and are difficult to master. Although generative editing methods now enable some forms of image editing, relighting is still beyond today's capabilities; existing methods struggle to keep other aspects of the image -- colors, shapes, and textures -- consistent after the edit. We propose Lasagna, a method that enables intuitive text-guided relighting control. Lasagna learns a lighting prior by using score distillation sampling to distill the prior of a diffusion model, which has been finetuned on synthetic relighting data. To train Lasagna, we curate a new synthetic dataset ReLiT, which contains 3D object assets re-lit from multiple light source locations. Despite training on synthetic images, quantitative results show that Lasagna relights real-world images while preserving other aspects of the input image, outperforming state-of-the-art text-guided image editing methods. Lasagna enables realistic and controlled results on natural images and digital art pieces and is preferred by humans over other methods in over 91% of cases. Finally, we demonstrate the versatility of our learning objective by extending it to allow colorization, another form of image editing.
Video Frame Interpolation with Many-to-many Splatting and Spatial Selective Refinement
Oct 29, 2023In this work, we first propose a fully differentiable Many-to-Many (M2M) splatting framework to interpolate frames efficiently. Given a frame pair, we estimate multiple bidirectional flows to directly forward warp the pixels to the desired time step before fusing overlapping pixels. In doing so, each source pixel renders multiple target pixels and each target pixel can be synthesized from a larger area of visual context, establishing a many-to-many splatting scheme with robustness to undesirable artifacts. For each input frame pair, M2M has a minuscule computational overhead when interpolating an arbitrary number of in-between frames, hence achieving fast multi-frame interpolation. However, directly warping and fusing pixels in the intensity domain is sensitive to the quality of motion estimation and may suffer from less effective representation capacity. To improve interpolation accuracy, we further extend an M2M++ framework by introducing a flexible Spatial Selective Refinement (SSR) component, which allows for trading computational efficiency for interpolation quality and vice versa. Instead of refining the entire interpolated frame, SSR only processes difficult regions selected under the guidance of an estimated error map, thereby avoiding redundant computation. Evaluation on multiple benchmark datasets shows that our method is able to improve the efficiency while maintaining competitive video interpolation quality, and it can be adjusted to use more or less compute as needed.
Socratis: Are large multimodal models emotionally aware?
Sep 05, 2023

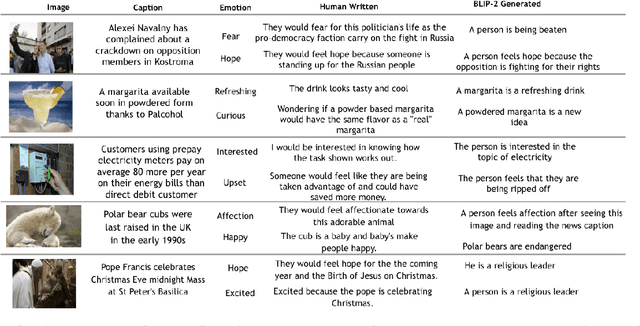
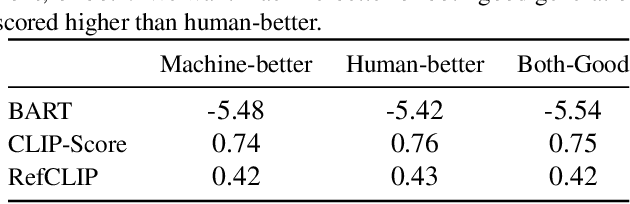
Existing emotion prediction benchmarks contain coarse emotion labels which do not consider the diversity of emotions that an image and text can elicit in humans due to various reasons. Learning diverse reactions to multimodal content is important as intelligent machines take a central role in generating and delivering content to society. To address this gap, we propose Socratis, a societal reactions benchmark, where each image-caption (IC) pair is annotated with multiple emotions and the reasons for feeling them. Socratis contains 18K free-form reactions for 980 emotions on 2075 image-caption pairs from 5 widely-read news and image-caption (IC) datasets. We benchmark the capability of state-of-the-art multimodal large language models to generate the reasons for feeling an emotion given an IC pair. Based on a preliminary human study, we observe that humans prefer human-written reasons over 2 times more often than machine-generated ones. This shows our task is harder than standard generation tasks because it starkly contrasts recent findings where humans cannot tell apart machine vs human-written news articles, for instance. We further see that current captioning metrics based on large vision-language models also fail to correlate with human preferences. We hope that these findings and our benchmark will inspire further research on training emotionally aware models.