 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbhinav Shrivastava
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Apr 08, 2024
With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
Measuring Style Similarity in Diffusion Models
Apr 01, 2024Generative models are now widely used by graphic designers and artists. Prior works have shown that these models remember and often replicate content from their training data during generation. Hence as their proliferation increases, it has become important to perform a database search to determine whether the properties of the image are attributable to specific training data, every time before a generated image is used for professional purposes. Existing tools for this purpose focus on retrieving images of similar semantic content. Meanwhile, many artists are concerned with style replication in text-to-image models. We present a framework for understanding and extracting style descriptors from images. Our framework comprises a new dataset curated using the insight that style is a subjective property of an image that captures complex yet meaningful interactions of factors including but not limited to colors, textures, shapes, etc. We also propose a method to extract style descriptors that can be used to attribute style of a generated image to the images used in the training dataset of a text-to-image model. We showcase promising results in various style retrieval tasks. We also quantitatively and qualitatively analyze style attribution and matching in the Stable Diffusion model. Code and artifacts are available at https://github.com/learn2phoenix/CSD.
What is Point Supervision Worth in Video Instance Segmentation?
Apr 01, 2024Video instance segmentation (VIS) is a challenging vision task that aims to detect, segment, and track objects in videos. Conventional VIS methods rely on densely-annotated object masks which are expensive. We reduce the human annotations to only one point for each object in a video frame during training, and obtain high-quality mask predictions close to fully supervised models. Our proposed training method consists of a class-agnostic proposal generation module to provide rich negative samples and a spatio-temporal point-based matcher to match the object queries with the provided point annotations. Comprehensive experiments on three VIS benchmarks demonstrate competitive performance of the proposed framework, nearly matching fully supervised methods.
LiFT: A Surprisingly Simple Lightweight Feature Transform for Dense ViT Descriptors
Mar 21, 2024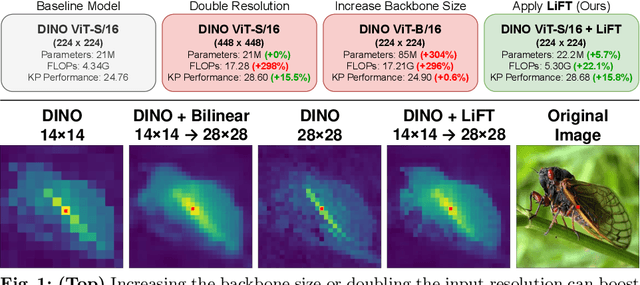
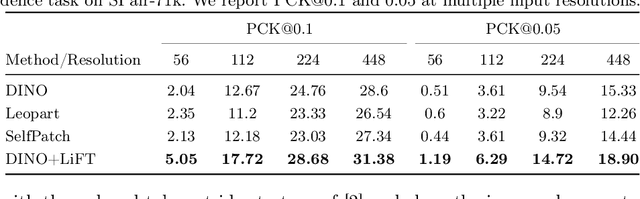
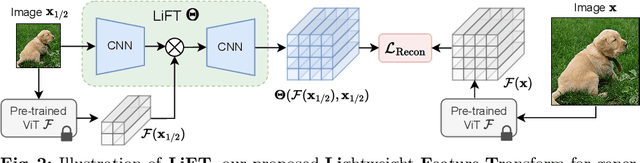

We present a simple self-supervised method to enhance the performance of ViT features for dense downstream tasks. Our Lightweight Feature Transform (LiFT) is a straightforward and compact postprocessing network that can be applied to enhance the features of any pre-trained ViT backbone. LiFT is fast and easy to train with a self-supervised objective, and it boosts the density of ViT features for minimal extra inference cost. Furthermore, we demonstrate that LiFT can be applied with approaches that use additional task-specific downstream modules, as we integrate LiFT with ViTDet for COCO detection and segmentation. Despite the simplicity of LiFT, we find that it is not simply learning a more complex version of bilinear interpolation. Instead, our LiFT training protocol leads to several desirable emergent properties that benefit ViT features in dense downstream tasks. This includes greater scale invariance for features, and better object boundary maps. By simply training LiFT for a few epochs, we show improved performance on keypoint correspondence, detection, segmentation, and object discovery tasks. Overall, LiFT provides an easy way to unlock the benefits of denser feature arrays for a fraction of the computational cost. For more details, refer to our project page at https://www.cs.umd.edu/~sakshams/LiFT/.
Customize-A-Video: One-Shot Motion Customization of Text-to-Video Diffusion Models
Feb 22, 2024Image customization has been extensively studied in text-to-image (T2I) diffusion models, leading to impressive outcomes and applications. With the emergence of text-to-video (T2V) diffusion models, its temporal counterpart, motion customization, has not yet been well investigated. To address the challenge of one-shot motion customization, we propose Customize-A-Video that models the motion from a single reference video and adapting it to new subjects and scenes with both spatial and temporal varieties. It leverages low-rank adaptation (LoRA) on temporal attention layers to tailor the pre-trained T2V diffusion model for specific motion modeling from the reference videos. To disentangle the spatial and temporal information during the training pipeline, we introduce a novel concept of appearance absorbers that detach the original appearance from the single reference video prior to motion learning. Our proposed method can be easily extended to various downstream tasks, including custom video generation and editing, video appearance customization, and multiple motion combination, in a plug-and-play fashion. Our project page can be found at https://anonymous-314.github.io.
Explaining the Implicit Neural Canvas: Connecting Pixels to Neurons by Tracing their Contributions
Jan 18, 2024The many variations of Implicit Neural Representations (INRs), where a neural network is trained as a continuous representation of a signal, have tremendous practical utility for downstream tasks including novel view synthesis, video compression, and image superresolution. Unfortunately, the inner workings of these networks are seriously under-studied. Our work, eXplaining the Implicit Neural Canvas (XINC), is a unified framework for explaining properties of INRs by examining the strength of each neuron's contribution to each output pixel. We call the aggregate of these contribution maps the Implicit Neural Canvas and we use this concept to demonstrate that the INRs which we study learn to ''see'' the frames they represent in surprising ways. For example, INRs tend to have highly distributed representations. While lacking high-level object semantics, they have a significant bias for color and edges, and are almost entirely space-agnostic. We arrive at our conclusions by examining how objects are represented across time in video INRs, using clustering to visualize similar neurons across layers and architectures, and show that this is dominated by motion. These insights demonstrate the general usefulness of our analysis framework. Our project page is available at https://namithap10.github.io/xinc.
Video Dynamics Prior: An Internal Learning Approach for Robust Video Enhancements
Dec 13, 2023In this paper, we present a novel robust framework for low-level vision tasks, including denoising, object removal, frame interpolation, and super-resolution, that does not require any external training data corpus. Our proposed approach directly learns the weights of neural modules by optimizing over the corrupted test sequence, leveraging the spatio-temporal coherence and internal statistics of videos. Furthermore, we introduce a novel spatial pyramid loss that leverages the property of spatio-temporal patch recurrence in a video across the different scales of the video. This loss enhances robustness to unstructured noise in both the spatial and temporal domains. This further results in our framework being highly robust to degradation in input frames and yields state-of-the-art results on downstream tasks such as denoising, object removal, and frame interpolation. To validate the effectiveness of our approach, we conduct qualitative and quantitative evaluations on standard video datasets such as DAVIS, UCF-101, and VIMEO90K-T.
EAGLES: Efficient Accelerated 3D Gaussians with Lightweight EncodingS
Dec 07, 2023
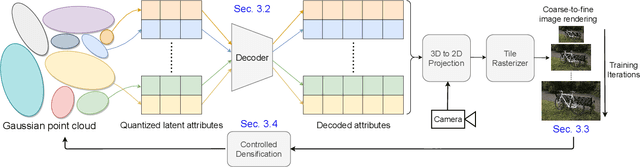
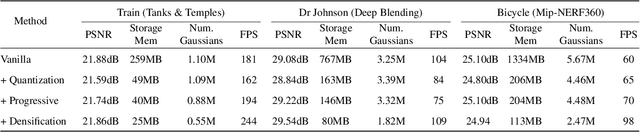
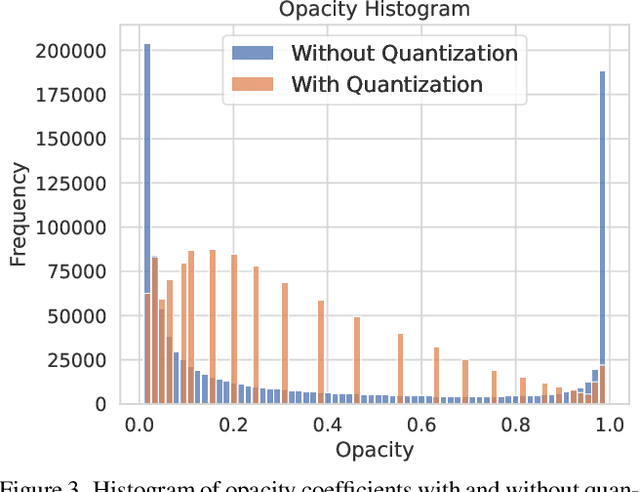
Recently, 3D Gaussian splatting (3D-GS) has gained popularity in novel-view scene synthesis. It addresses the challenges of lengthy training times and slow rendering speeds associated with Neural Radiance Fields (NeRFs). Through rapid, differentiable rasterization of 3D Gaussians, 3D-GS achieves real-time rendering and accelerated training. They, however, demand substantial memory resources for both training and storage, as they require millions of Gaussians in their point cloud representation for each scene. We present a technique utilizing quantized embeddings to significantly reduce memory storage requirements and a coarse-to-fine training strategy for a faster and more stable optimization of the Gaussian point clouds. Our approach results in scene representations with fewer Gaussians and quantized representations, leading to faster training times and rendering speeds for real-time rendering of high resolution scenes. We reduce memory by more than an order of magnitude all while maintaining the reconstruction quality. We validate the effectiveness of our approach on a variety of datasets and scenes preserving the visual quality while consuming 10-20x less memory and faster training/inference speed. Project page and code is available https://efficientgaussian.github.io
Gen2Det: Generate to Detect
Dec 07, 2023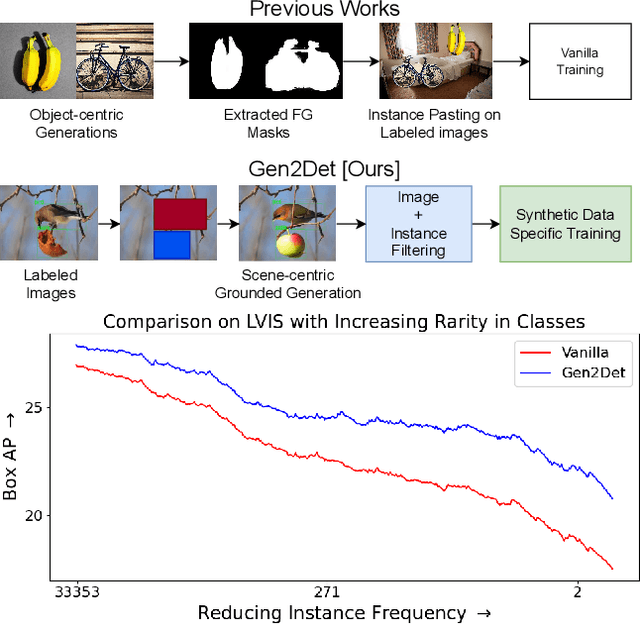
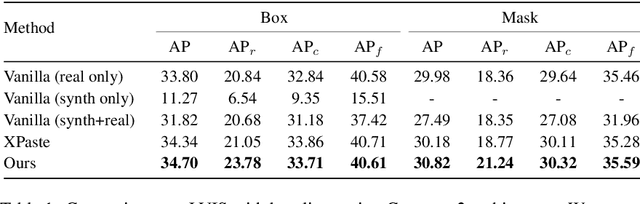
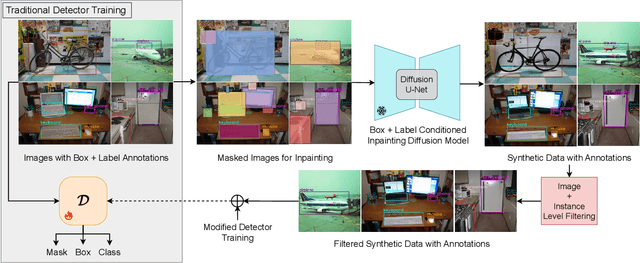
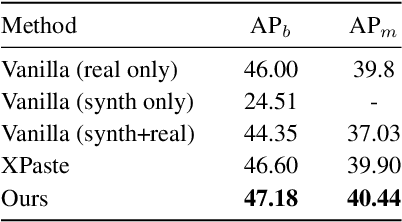
Recently diffusion models have shown improvement in synthetic image quality as well as better control in generation. We motivate and present Gen2Det, a simple modular pipeline to create synthetic training data for object detection for free by leveraging state-of-the-art grounded image generation methods. Unlike existing works which generate individual object instances, require identifying foreground followed by pasting on other images, we simplify to directly generating scene-centric images. In addition to the synthetic data, Gen2Det also proposes a suite of techniques to best utilize the generated data, including image-level filtering, instance-level filtering, and better training recipe to account for imperfections in the generation. Using Gen2Det, we show healthy improvements on object detection and segmentation tasks under various settings and agnostic to detection methods. In the long-tailed detection setting on LVIS, Gen2Det improves the performance on rare categories by a large margin while also significantly improving the performance on other categories, e.g. we see an improvement of 2.13 Box AP and 1.84 Mask AP over just training on real data on LVIS with Mask R-CNN. In the low-data regime setting on COCO, Gen2Det consistently improves both Box and Mask AP by 2.27 and 1.85 points. In the most general detection setting, Gen2Det still demonstrates robust performance gains, e.g. it improves the Box and Mask AP on COCO by 0.45 and 0.32 points.
Multimodality-guided Image Style Transfer using Cross-modal GAN Inversion
Dec 04, 2023Image Style Transfer (IST) is an interdisciplinary topic of computer vision and art that continuously attracts researchers' interests. Different from traditional Image-guided Image Style Transfer (IIST) methods that require a style reference image as input to define the desired style, recent works start to tackle the problem in a text-guided manner, i.e., Text-guided Image Style Transfer (TIST). Compared to IIST, such approaches provide more flexibility with text-specified styles, which are useful in scenarios where the style is hard to define with reference images. Unfortunately, many TIST approaches produce undesirable artifacts in the transferred images. To address this issue, we present a novel method to achieve much improved style transfer based on text guidance. Meanwhile, to offer more flexibility than IIST and TIST, our method allows style inputs from multiple sources and modalities, enabling MultiModality-guided Image Style Transfer (MMIST). Specifically, we realize MMIST with a novel cross-modal GAN inversion method, which generates style representations consistent with specified styles. Such style representations facilitate style transfer and in principle generalize any IIST methods to MMIST. Large-scale experiments and user studies demonstrate that our method achieves state-of-the-art performance on TIST task. Furthermore, comprehensive qualitative results confirm the effectiveness of our method on MMIST task and cross-modal style interpolation.