 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaopeng Li
DWE+: Dual-Way Matching Enhanced Framework for Multimodal Entity Linking
Apr 07, 2024
Multimodal entity linking (MEL) aims to utilize multimodal information (usually textual and visual information) to link ambiguous mentions to unambiguous entities in knowledge base. Current methods facing main issues: (1)treating the entire image as input may contain redundant information. (2)the insufficient utilization of entity-related information, such as attributes in images. (3)semantic inconsistency between the entity in knowledge base and its representation. To this end, we propose DWE+ for multimodal entity linking. DWE+ could capture finer semantics and dynamically maintain semantic consistency with entities. This is achieved by three aspects: (a)we introduce a method for extracting fine-grained image features by partitioning the image into multiple local objects. Then, hierarchical contrastive learning is used to further align semantics between coarse-grained information(text and image) and fine-grained (mention and visual objects). (b)we explore ways to extract visual attributes from images to enhance fusion feature such as facial features and identity. (c)we leverage Wikipedia and ChatGPT to capture the entity representation, achieving semantic enrichment from both static and dynamic perspectives, which better reflects the real-world entity semantics. Experiments on Wikimel, Richpedia, and Wikidiverse datasets demonstrate the effectiveness of DWE+ in improving MEL performance. Specifically, we optimize these datasets and achieve state-of-the-art performance on the enhanced datasets. The code and enhanced datasets are released on https://github.com/season1blue/DWET
V2X-DGW: Domain Generalization for Multi-agent Perception under Adverse Weather Conditions
Mar 29, 2024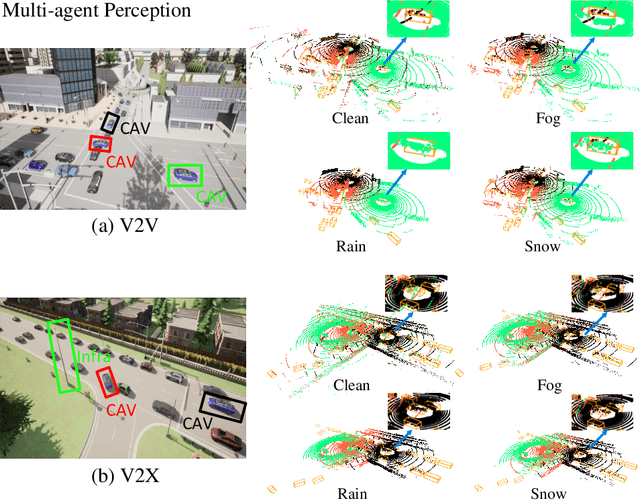
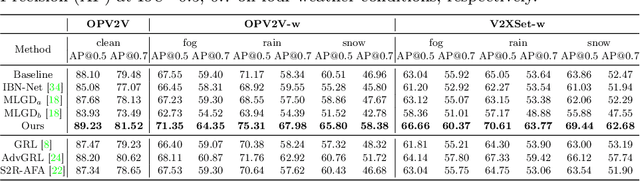
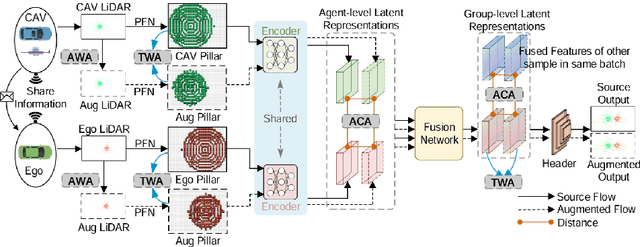
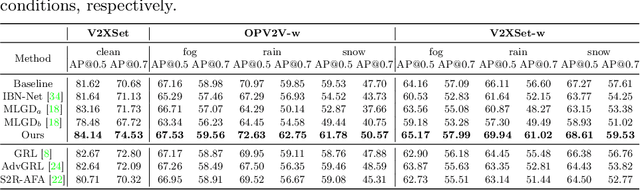
Current LiDAR-based Vehicle-to-Everything (V2X) multi-agent perception systems have shown the significant success on 3D object detection. While these models perform well in the trained clean weather, they struggle in unseen adverse weather conditions with the real-world domain gap. In this paper, we propose a domain generalization approach, named V2X-DGW, for LiDAR-based 3D object detection on multi-agent perception system under adverse weather conditions. Not only in the clean weather does our research aim to ensure favorable multi-agent performance, but also in the unseen adverse weather conditions by learning only on the clean weather data. To advance research in this area, we have simulated the impact of three prevalent adverse weather conditions on two widely-used multi-agent datasets, resulting in the creation of two novel benchmark datasets: OPV2V-w and V2XSet-w. To this end, we first introduce the Adaptive Weather Augmentation (AWA) to mimic the unseen adverse weather conditions, and then propose two alignments for generalizable representation learning: Trust-region Weather-invariant Alignment (TWA) and Agent-aware Contrastive Alignment (ACA). Extensive experimental results demonstrate that our V2X-DGW achieved improvements in the unseen adverse weather conditions.
SWEA: Changing Factual Knowledge in Large Language Models via Subject Word Embedding Altering
Jan 31, 2024Model editing has recently gained widespread attention. Current model editing methods primarily involve modifying model parameters or adding additional modules to the existing model. However, the former causes irreversible damage to LLMs, while the latter incurs additional inference overhead and fuzzy vector matching is not always reliable. To address these issues, we propose an expandable Subject Word Embedding Altering (SWEA) framework, which modifies the representation of subjects and achieve the goal of editing knowledge during the inference stage. SWEA uses precise key matching outside the model and performs reliable subject word embedding altering, thus protecting the original weights of the model without increasing inference overhead. We then propose optimizing then suppressing fusion method, which first optimizes the embedding vector for the editing target and then suppresses the Knowledge Embedding Dimension (KED) to obtain the final fused embedding. We thus propose SWEAOS method for editing factual knowledge in LLMs. We demonstrate the state-of-the-art performance of SWEAOS on the COUNTERFACT and zsRE datasets. To further validate the reasoning ability of SWEAOS in editing knowledge, we evaluate it on the more complex RIPPLEEDITS benchmark. The results on two subdatasets demonstrate that our SWEAOS possesses state-of-the-art reasoning ability.
Agent4Ranking: Semantic Robust Ranking via Personalized Query Rewriting Using Multi-agent LLM
Dec 24, 2023Search engines are crucial as they provide an efficient and easy way to access vast amounts of information on the internet for diverse information needs. User queries, even with a specific need, can differ significantly. Prior research has explored the resilience of ranking models against typical query variations like paraphrasing, misspellings, and order changes. Yet, these works overlook how diverse demographics uniquely formulate identical queries. For instance, older individuals tend to construct queries more naturally and in varied order compared to other groups. This demographic diversity necessitates enhancing the adaptability of ranking models to diverse query formulations. To this end, in this paper, we propose a framework that integrates a novel rewriting pipeline that rewrites queries from various demographic perspectives and a novel framework to enhance ranking robustness. To be specific, we use Chain of Thought (CoT) technology to utilize Large Language Models (LLMs) as agents to emulate various demographic profiles, then use them for efficient query rewriting, and we innovate a robust Multi-gate Mixture of Experts (MMoE) architecture coupled with a hybrid loss function, collectively strengthening the ranking models' robustness. Our extensive experimentation on both public and industrial datasets assesses the efficacy of our query rewriting approach and the enhanced accuracy and robustness of the ranking model. The findings highlight the sophistication and effectiveness of our proposed model.
How to Bridge the Gap between Modalities: A Comprehensive Survey on Multimodal Large Language Model
Nov 10, 2023This review paper explores Multimodal Large Language Models (MLLMs), which integrate Large Language Models (LLMs) like GPT-4 to handle multimodal data such as text and vision. MLLMs demonstrate capabilities like generating image narratives and answering image-based questions, bridging the gap towards real-world human-computer interactions and hinting at a potential pathway to artificial general intelligence. However, MLLMs still face challenges in processing the semantic gap in multimodality, which may lead to erroneous generation, posing potential risks to society. Choosing the appropriate modality alignment method is crucial, as improper methods might require more parameters with limited performance improvement. This paper aims to explore modality alignment methods for LLMs and their existing capabilities. Implementing modality alignment allows LLMs to address environmental issues and enhance accessibility. The study surveys existing modal alignment methods in MLLMs into four groups: (1) Multimodal Converters that change data into something LLMs can understand; (2) Multimodal Perceivers to improve how LLMs perceive different types of data; (3) Tools Assistance for changing data into one common format, usually text; and (4) Data-Driven methods that teach LLMs to understand specific types of data in a dataset. This field is still in a phase of exploration and experimentation, and we will organize and update various existing research methods for multimodal information alignment.
MILL: Mutual Verification with Large Language Models for Zero-Shot Query Expansion
Oct 29, 2023
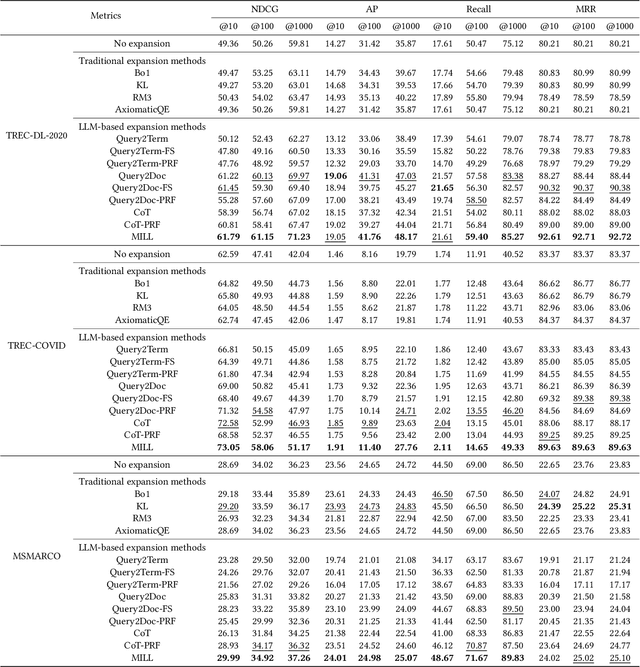

Query expansion is a commonly-used technique in many search systems to better represent users' information needs with additional query terms. Existing studies for this task usually propose to expand a query with retrieved or generated contextual documents. However, both types of methods have clear limitations. For retrieval-based methods, the documents retrieved with the original query might not be accurate enough to reveal the search intent, especially when the query is brief or ambiguous. For generation-based methods, existing models can hardly be trained or aligned on a particular corpus, due to the lack of corpus-specific labeled data. In this paper, we propose a novel Large Language Model (LLM) based mutual verification framework for query expansion, which alleviates the aforementioned limitations. Specifically, we first design a query-query-document generation pipeline, which can effectively leverage the contextual knowledge encoded in LLMs to generate sub-queries and corresponding documents from multiple perspectives. Next, we employ a mutual verification method for both generated and retrieved contextual documents, where 1) retrieved documents are filtered with the external contextual knowledge in generated documents, and 2) generated documents are filtered with the corpus-specific knowledge in retrieved documents. Overall, the proposed method allows retrieved and generated documents to complement each other to finalize a better query expansion. We conduct extensive experiments on three information retrieval datasets, i.e., TREC-DL-2020, TREC-COVID, and MSMARCO. The results demonstrate that our method outperforms other baselines significantly.
A Physics Enhanced Residual Learning (PERL) Framework for Traffic State Prediction
Sep 26, 2023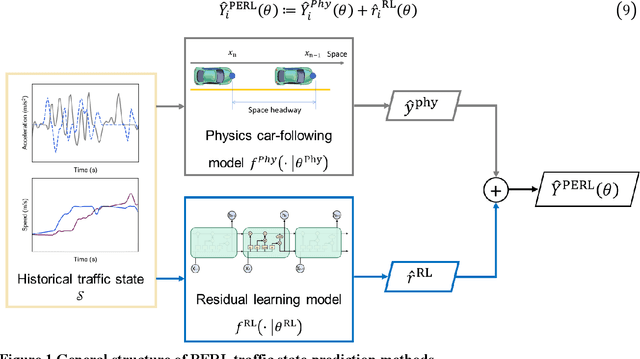
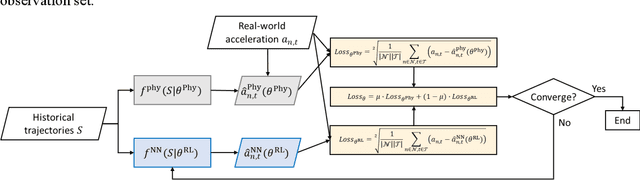

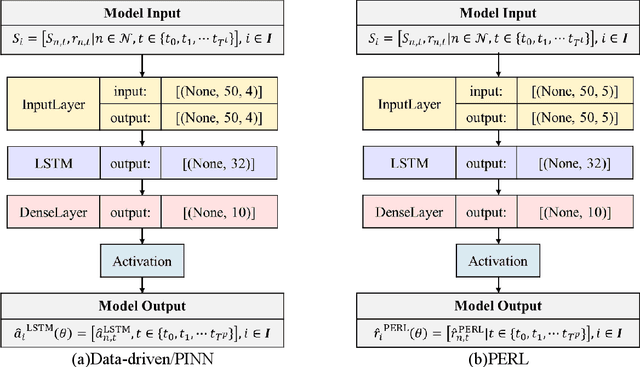
In vehicle trajectory prediction, physics models and data-driven models are two predominant methodologies. However, each approach presents its own set of challenges: physics models fall short in predictability, while data-driven models lack interpretability. Addressing these identified shortcomings, this paper proposes a novel framework, the Physics-Enhanced Residual Learning (PERL) model. PERL integrates the strengths of physics-based and data-driven methods for traffic state prediction. PERL contains a physics model and a residual learning model. Its prediction is the sum of the physics model result and a predicted residual as a correction to it. It preserves the interpretability inherent to physics-based models and has reduced data requirements compared to data-driven methods. Experiments were conducted using a real-world vehicle trajectory dataset. We proposed a PERL model, with the Intelligent Driver Model (IDM) as its physics car-following model and Long Short-Term Memory (LSTM) as its residual learning model. We compare this PERL model with the physics car-following model, data-driven model, and other physics-informed neural network (PINN) models. The result reveals that PERL achieves better prediction with a small dataset, compared to the physics model, data-driven model, and PINN model. Second, the PERL model showed faster convergence during training, offering comparable performance with fewer training samples than the data-driven model and PINN model. Sensitivity analysis also proves comparable performance of PERL using another residual learning model and a physics car-following model.
P-ROCKET: Pruning Random Convolution Kernels for Time Series Classification
Sep 15, 2023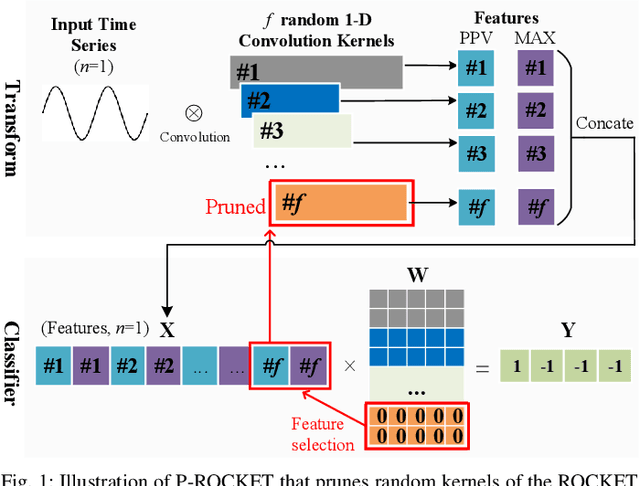
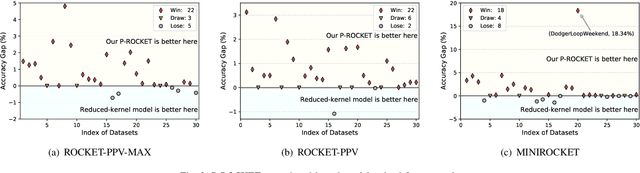
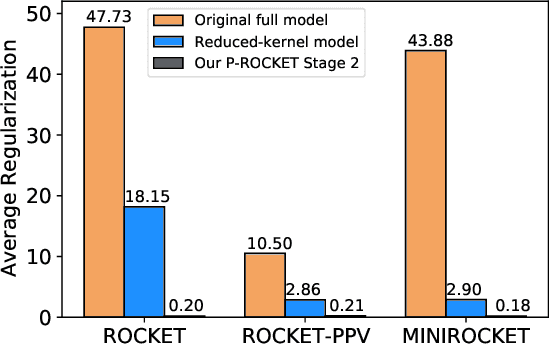
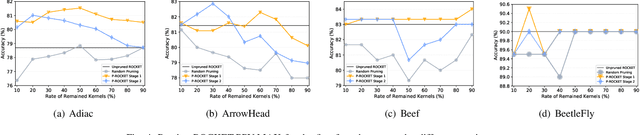
In recent years, two time series classification models, ROCKET and MINIROCKET, have attracted much attention for their low training cost and state-of-the-art accuracy. Utilizing random 1-D convolutional kernels without training, ROCKET and MINIROCKET can rapidly extract features from time series data, allowing for the efficient fitting of linear classifiers. However, to comprehensively capture useful features, a large number of random kernels are required, which is incompatible for resource-constrained devices. Therefore, a heuristic evolutionary algorithm named S-ROCKET is devised to recognize and prune redundant kernels. Nevertheless, the inherent nature of evolutionary algorithms renders the evaluation of kernels within S-ROCKET an unacceptable time-consuming process. In this paper, diverging from S-ROCKET, which directly evaluates random kernels with nonsignificant differences, we remove kernels from a feature selection perspective by eliminating associating connections in the sequential classification layer. To this end, we start by formulating the pruning challenge as a Group Elastic Net classification problem and employ the ADMM method to arrive at a solution. Sequentially, we accelerate the aforementioned time-consuming solving process by bifurcating the $l_{2,1}$ and $l_2$ regularizations into two sequential stages and solve them separately, which ultimately forms our core algorithm, named P-ROCKET. Stage 1 of P-ROCKET employs group-wise regularization similarly to our initial ADMM-based Algorithm, but introduces dynamically varying penalties to greatly accelerate the process. To mitigate overfitting, Stage 2 of P-ROCKET implements element-wise regularization to refit a linear classifier, utilizing the retained features.
HAMUR: Hyper Adapter for Multi-Domain Recommendation
Sep 12, 2023
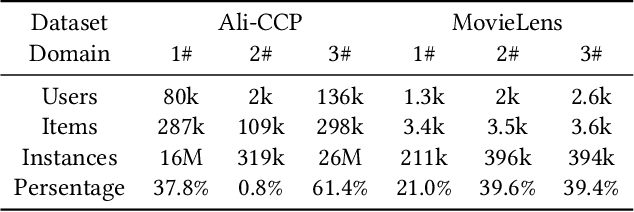

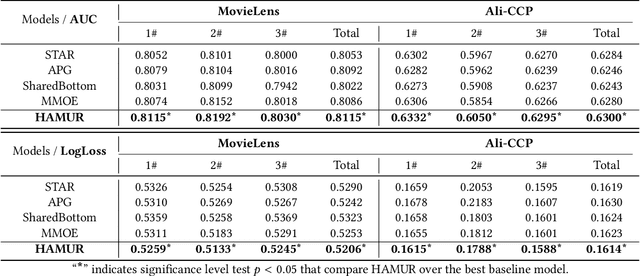
Multi-Domain Recommendation (MDR) has gained significant attention in recent years, which leverages data from multiple domains to enhance their performance concurrently.However, current MDR models are confronted with two limitations. Firstly, the majority of these models adopt an approach that explicitly shares parameters between domains, leading to mutual interference among them. Secondly, due to the distribution differences among domains, the utilization of static parameters in existing methods limits their flexibility to adapt to diverse domains. To address these challenges, we propose a novel model Hyper Adapter for Multi-Domain Recommendation (HAMUR). Specifically, HAMUR consists of two components: (1). Domain-specific adapter, designed as a pluggable module that can be seamlessly integrated into various existing multi-domain backbone models, and (2). Domain-shared hyper-network, which implicitly captures shared information among domains and dynamically generates the parameters for the adapter. We conduct extensive experiments on two public datasets using various backbone networks. The experimental results validate the effectiveness and scalability of the proposed model.
Scenario-Aware Hierarchical Dynamic Network for Multi-Scenario Recommendation
Sep 05, 2023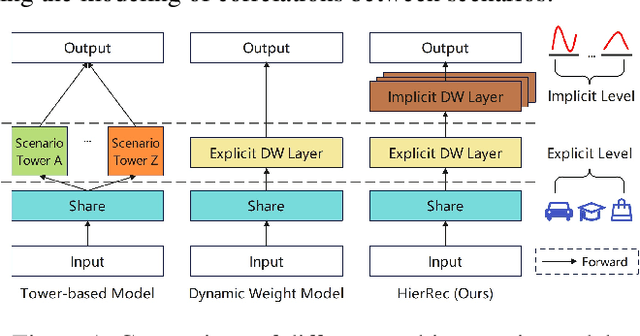

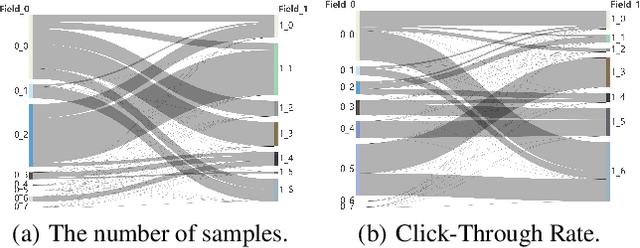
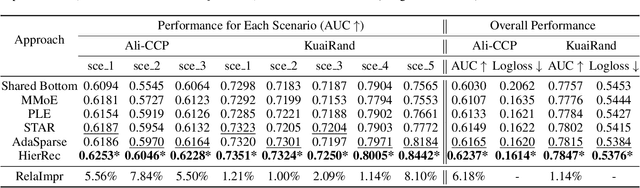
Click-Through Rate (CTR) prediction is a fundamental technique in recommendation and advertising systems. Recent studies have shown that implementing multi-scenario recommendations contributes to strengthening information sharing and improving overall performance. However, existing multi-scenario models only consider coarse-grained explicit scenario modeling that depends on pre-defined scenario identification from manual prior rules, which is biased and sub-optimal. To address these limitations, we propose a Scenario-Aware Hierarchical Dynamic Network for Multi-Scenario Recommendations (HierRec), which perceives implicit patterns adaptively and conducts explicit and implicit scenario modeling jointly. In particular, HierRec designs a basic scenario-oriented module based on the dynamic weight to capture scenario-specific information. Then the hierarchical explicit and implicit scenario-aware modules are proposed to model hybrid-grained scenario information. The multi-head implicit modeling design contributes to perceiving distinctive patterns from different perspectives. Our experiments on two public datasets and real-world industrial applications on a mainstream online advertising platform demonstrate that our HierRec outperforms existing models significantly.