 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShan Zhao
DWE+: Dual-Way Matching Enhanced Framework for Multimodal Entity Linking
Apr 07, 2024
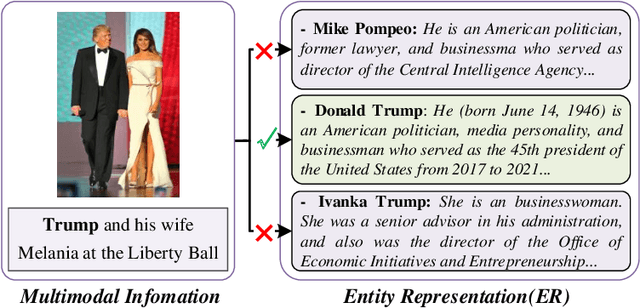
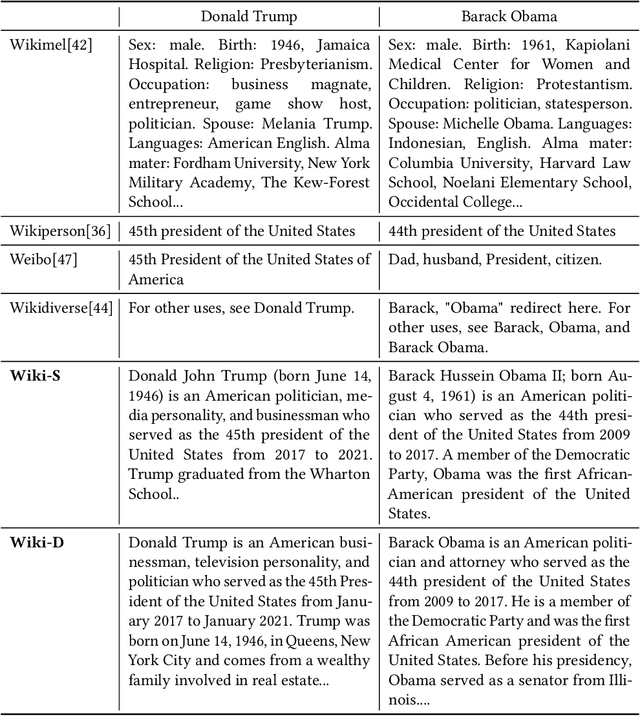
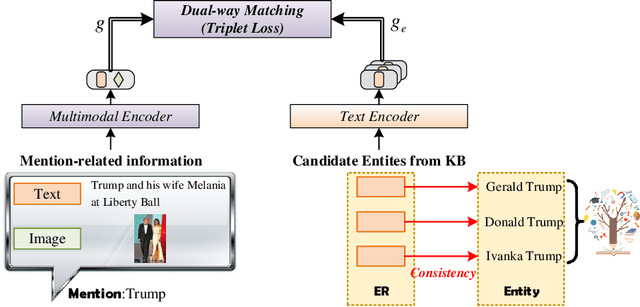
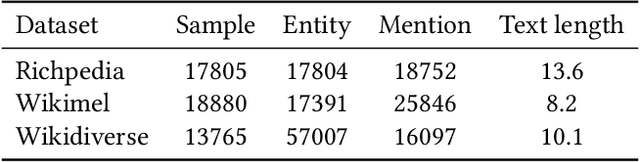
Multimodal entity linking (MEL) aims to utilize multimodal information (usually textual and visual information) to link ambiguous mentions to unambiguous entities in knowledge base. Current methods facing main issues: (1)treating the entire image as input may contain redundant information. (2)the insufficient utilization of entity-related information, such as attributes in images. (3)semantic inconsistency between the entity in knowledge base and its representation. To this end, we propose DWE+ for multimodal entity linking. DWE+ could capture finer semantics and dynamically maintain semantic consistency with entities. This is achieved by three aspects: (a)we introduce a method for extracting fine-grained image features by partitioning the image into multiple local objects. Then, hierarchical contrastive learning is used to further align semantics between coarse-grained information(text and image) and fine-grained (mention and visual objects). (b)we explore ways to extract visual attributes from images to enhance fusion feature such as facial features and identity. (c)we leverage Wikipedia and ChatGPT to capture the entity representation, achieving semantic enrichment from both static and dynamic perspectives, which better reflects the real-world entity semantics. Experiments on Wikimel, Richpedia, and Wikidiverse datasets demonstrate the effectiveness of DWE+ in improving MEL performance. Specifically, we optimize these datasets and achieve state-of-the-art performance on the enhanced datasets. The code and enhanced datasets are released on https://github.com/season1blue/DWET
Causal Graph Neural Networks for Wildfire Danger Prediction
Mar 13, 2024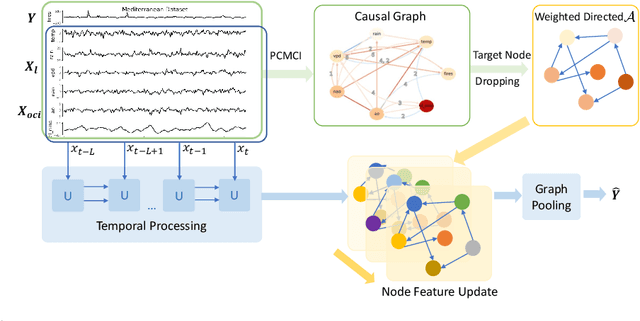
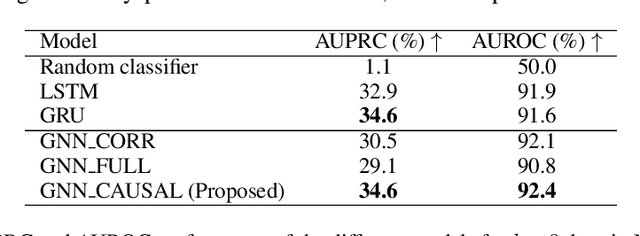
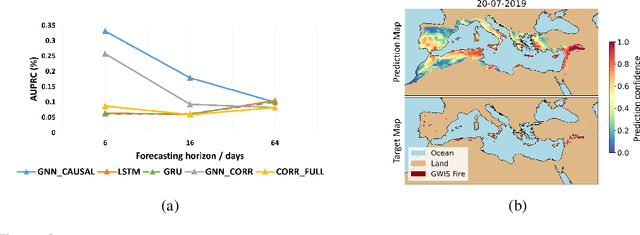
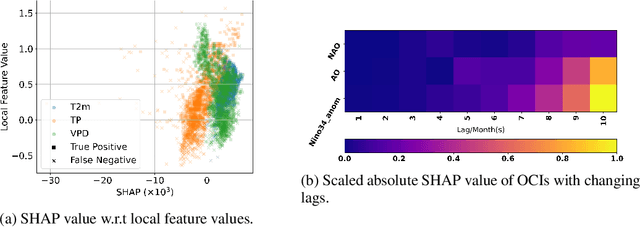
Wildfire forecasting is notoriously hard due to the complex interplay of different factors such as weather conditions, vegetation types and human activities. Deep learning models show promise in dealing with this complexity by learning directly from data. However, to inform critical decision making, we argue that we need models that are right for the right reasons; that is, the implicit rules learned should be grounded by the underlying processes driving wildfires. In that direction, we propose integrating causality with Graph Neural Networks (GNNs) that explicitly model the causal mechanism among complex variables via graph learning. The causal adjacency matrix considers the synergistic effect among variables and removes the spurious links from highly correlated impacts. Our methodology's effectiveness is demonstrated through superior performance forecasting wildfire patterns in the European boreal and mediterranean biome. The gain is especially prominent in a highly imbalanced dataset, showcasing an enhanced robustness of the model to adapt to regime shifts in functional relationships. Furthermore, SHAP values from our trained model further enhance our understanding of the model's inner workings.
Efficient Subseasonal Weather Forecast using Teleconnection-informed Transformers
Feb 05, 2024Subseasonal forecasting, which is pivotal for agriculture, water resource management, and early warning of disasters, faces challenges due to the chaotic nature of the atmosphere. Recent advances in machine learning (ML) have revolutionized weather forecasting by achieving competitive predictive skills to numerical models. However, training such foundation models requires thousands of GPU days, which causes substantial carbon emissions and limits their broader applicability. Moreover, ML models tend to fool the pixel-wise error scores by producing smoothed results which lack physical consistency and meteorological meaning. To deal with the aforementioned problems, we propose a teleconnection-informed transformer. Our architecture leverages the pretrained Pangu model to achieve good initial weights and integrates a teleconnection-informed temporal module to improve predictability in an extended temporal range. Remarkably, by adjusting 1.1% of the Pangu model's parameters, our method enhances predictability on four surface and five upper-level atmospheric variables at a two-week lead time. Furthermore, the teleconnection-filtered features improve the spatial granularity of outputs significantly, indicating their potential physical consistency. Our research underscores the importance of atmospheric and oceanic teleconnections in driving future weather conditions. Besides, it presents a resource-efficient pathway for researchers to leverage existing foundation models on versatile downstream tasks.
A Dual-way Enhanced Framework from Text Matching Point of View for Multimodal Entity Linking
Dec 19, 2023Multimodal Entity Linking (MEL) aims at linking ambiguous mentions with multimodal information to entity in Knowledge Graph (KG) such as Wikipedia, which plays a key role in many applications. However, existing methods suffer from shortcomings, including modality impurity such as noise in raw image and ambiguous textual entity representation, which puts obstacles to MEL. We formulate multimodal entity linking as a neural text matching problem where each multimodal information (text and image) is treated as a query, and the model learns the mapping from each query to the relevant entity from candidate entities. This paper introduces a dual-way enhanced (DWE) framework for MEL: (1) our model refines queries with multimodal data and addresses semantic gaps using cross-modal enhancers between text and image information. Besides, DWE innovatively leverages fine-grained image attributes, including facial characteristic and scene feature, to enhance and refine visual features. (2)By using Wikipedia descriptions, DWE enriches entity semantics and obtains more comprehensive textual representation, which reduces between textual representation and the entities in KG. Extensive experiments on three public benchmarks demonstrate that our method achieves state-of-the-art (SOTA) performance, indicating the superiority of our model. The code is released on https://github.com/season1blue/DWE
Exploring Geometric Deep Learning For Precipitation Nowcasting
Sep 11, 2023



Precipitation nowcasting (up to a few hours) remains a challenge due to the highly complex local interactions that need to be captured accurately. Convolutional Neural Networks rely on convolutional kernels convolving with grid data and the extracted features are trapped by limited receptive field, typically expressed in excessively smooth output compared to ground truth. Thus they lack the capacity to model complex spatial relationships among the grids. Geometric deep learning aims to generalize neural network models to non-Euclidean domains. Such models are more flexible in defining nodes and edges and can effectively capture dynamic spatial relationship among geographical grids. Motivated by this, we explore a geometric deep learning-based temporal Graph Convolutional Network (GCN) for precipitation nowcasting. The adjacency matrix that simulates the interactions among grid cells is learned automatically by minimizing the L1 loss between prediction and ground truth pixel value during the training procedure. Then, the spatial relationship is refined by GCN layers while the temporal information is extracted by 1D convolution with various kernel lengths. The neighboring information is fed as auxiliary input layers to improve the final result. We test the model on sequences of radar reflectivity maps over the Trento/Italy area. The results show that GCNs improves the effectiveness of modeling the local details of the cloud profile as well as the prediction accuracy by achieving decreased error measures.
Rt-Track: Robust Tricks for Multi-Pedestrian Tracking
Mar 16, 2023



Object tracking is divided into single-object tracking (SOT) and multi-object tracking (MOT). MOT aims to maintain the identities of multiple objects across a series of continuous video sequences. In recent years, MOT has made rapid progress. However, modeling the motion and appearance models of objects in complex scenes still faces various challenging issues. In this paper, we design a novel direction consistency method for smooth trajectory prediction (STP-DC) to increase the modeling of motion information and overcome the lack of robustness in previous methods in complex scenes. Existing methods use pedestrian re-identification (Re-ID) to model appearance, however, they extract more background information which lacks discriminability in occlusion and crowded scenes. We propose a hyper-grain feature embedding network (HG-FEN) to enhance the modeling of appearance models, thus generating robust appearance descriptors. We also proposed other robustness techniques, including CF-ECM for storing robust appearance information and SK-AS for improving association accuracy. To achieve state-of-the-art performance in MOT, we propose a robust tracker named Rt-track, incorporating various tricks and techniques. It achieves 79.5 MOTA, 76.0 IDF1 and 62.1 HOTA on the test set of MOT17.Rt-track also achieves 77.9 MOTA, 78.4 IDF1 and 63.3 HOTA on MOT20, surpassing all published methods.
InterFace:Adjustable Angular Margin Inter-class Loss for Deep Face Recognition
Oct 09, 2022



In the field of face recognition, it is always a hot research topic to improve the loss solution to make the face features extracted by the network have greater discriminative power. Research works in recent years has improved the discriminative power of the face model by normalizing softmax to the cosine space step by step and then adding a fixed penalty margin to reduce the intra-class distance to increase the inter-class distance. Although a great deal of previous work has been done to optimize the boundary penalty to improve the discriminative power of the model, adding a fixed margin penalty to the depth feature and the corresponding weight is not consistent with the pattern of data in the real scenario. To address this issue, in this paper, we propose a novel loss function, InterFace, releasing the constraint of adding a margin penalty only between the depth feature and the corresponding weight to push the separability of classes by adding corresponding margin penalties between the depth features and all weights. To illustrate the advantages of InterFace over a fixed penalty margin, we explained geometrically and comparisons on a set of mainstream benchmarks. From a wider perspective, our InterFace has advanced the state-of-the-art face recognition performance on five out of thirteen mainstream benchmarks. All training codes, pre-trained models, and training logs, are publicly released \footnote{$https://github.com/iamsangmeng/InterFace$}.
Semi-Supervised Wide-Angle Portraits Correction by Multi-Scale Transformer
Sep 14, 2021
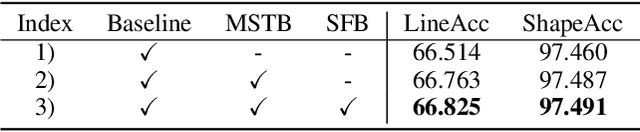
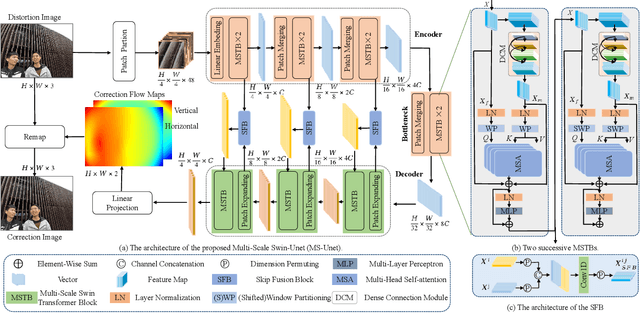
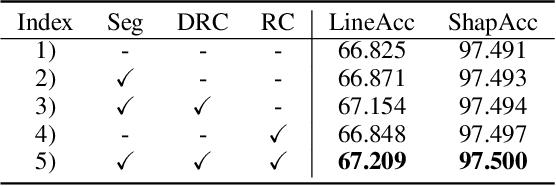
We propose a semi-supervised network for wide-angle portraits correction. Wide-angle images often suffer from skew and distortion affected by perspective distortion, especially noticeable at the face regions. Previous deep learning based approaches require the ground-truth correction flow maps for the training guidance. However, such labels are expensive, which can only be obtained manually. In this work, we propose a semi-supervised scheme, which can consume unlabeled data in addition to the labeled data for improvements. Specifically, our semi-supervised scheme takes the advantages of the consistency mechanism, with several novel components such as direction and range consistency (DRC) and regression consistency (RC). Furthermore, our network, named as Multi-Scale Swin-Unet (MS-Unet), is built upon the multi-scale swin transformer block (MSTB), which can learn both local-scale and long-range semantic information effectively. In addition, we introduce a high-quality unlabeled dataset with rich scenarios for the training. Extensive experiments demonstrate that the proposed method is superior over the state-of-the-art methods and other representative baselines.
Reiterative Domain Aware Multi-target Adaptation
Aug 26, 2021



Most domain adaptation methods focus on single-source-single-target adaptation setting. Multi-target domain adaptation is a powerful extension in which a single classifier is learned for multiple unlabeled target domains. To build a multi-target classifier, it is crucial to effectively aggregate features from the labeled source and different unlabeled target domains. Towards this, recently introduced Domain-aware Curriculum Graph Co-Teaching (D-CGCT) exploits dual classifier head, one of which is based on the graph neural network. D-CGCT uses a sequential adaptation strategy that adapts one domain at a time starting from the target domains that are more similar to the source, assuming that the network finds it easier to adapt to such target domains. However, we argue that there is no easier domain or difficult domain in absolute sense and each domain can have samples showing different characteristics. Following this cue, we propose Reiterative D-CGCT (RD-CGCT) that obtains better adaptation performance by reiterating multiple times over each target domain, while keeping the total number of iterations as same. RD-CGCT further improves the adaptation performance by considering more source samples than training samples in the training minibatch. Proposed RD-CGCT significantly improves the performance over D-CGCT for Office-Home and Office31 datasets.
Practical Wide-Angle Portraits Correction with Deep Structured Models
Apr 28, 2021
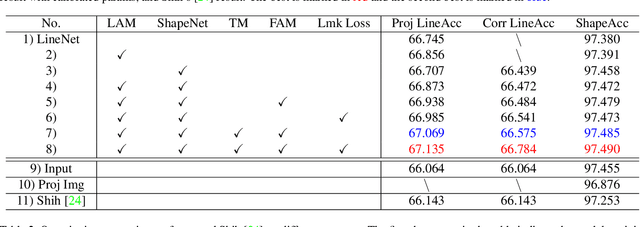
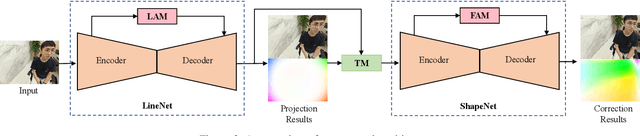

Wide-angle portraits often enjoy expanded views. However, they contain perspective distortions, especially noticeable when capturing group portrait photos, where the background is skewed and faces are stretched. This paper introduces the first deep learning based approach to remove such artifacts from freely-shot photos. Specifically, given a wide-angle portrait as input, we build a cascaded network consisting of a LineNet, a ShapeNet, and a transition module (TM), which corrects perspective distortions on the background, adapts to the stereographic projection on facial regions, and achieves smooth transitions between these two projections, accordingly. To train our network, we build the first perspective portrait dataset with a large diversity in identities, scenes and camera modules. For the quantitative evaluation, we introduce two novel metrics, line consistency and face congruence. Compared to the previous state-of-the-art approach, our method does not require camera distortion parameters. We demonstrate that our approach significantly outperforms the previous state-of-the-art approach both qualitatively and quantitatively.