 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJing Tan
Dual DETRs for Multi-Label Temporal Action Detection
Mar 31, 2024
Temporal Action Detection (TAD) aims to identify the action boundaries and the corresponding category within untrimmed videos. Inspired by the success of DETR in object detection, several methods have adapted the query-based framework to the TAD task. However, these approaches primarily followed DETR to predict actions at the instance level (i.e., identify each action by its center point), leading to sub-optimal boundary localization. To address this issue, we propose a new Dual-level query-based TAD framework, namely DualDETR, to detect actions from both instance-level and boundary-level. Decoding at different levels requires semantics of different granularity, therefore we introduce a two-branch decoding structure. This structure builds distinctive decoding processes for different levels, facilitating explicit capture of temporal cues and semantics at each level. On top of the two-branch design, we present a joint query initialization strategy to align queries from both levels. Specifically, we leverage encoder proposals to match queries from each level in a one-to-one manner. Then, the matched queries are initialized using position and content prior from the matched action proposal. The aligned dual-level queries can refine the matched proposal with complementary cues during subsequent decoding. We evaluate DualDETR on three challenging multi-label TAD benchmarks. The experimental results demonstrate the superior performance of DualDETR to the existing state-of-the-art methods, achieving a substantial improvement under det-mAP and delivering impressive results under seg-mAP.
Multi-Objective Optimization Using Adaptive Distributed Reinforcement Learning
Mar 13, 2024



The Intelligent Transportation System (ITS) environment is known to be dynamic and distributed, where participants (vehicle users, operators, etc.) have multiple, changing and possibly conflicting objectives. Although Reinforcement Learning (RL) algorithms are commonly applied to optimize ITS applications such as resource management and offloading, most RL algorithms focus on single objectives. In many situations, converting a multi-objective problem into a single-objective one is impossible, intractable or insufficient, making such RL algorithms inapplicable. We propose a multi-objective, multi-agent reinforcement learning (MARL) algorithm with high learning efficiency and low computational requirements, which automatically triggers adaptive few-shot learning in a dynamic, distributed and noisy environment with sparse and delayed reward. We test our algorithm in an ITS environment with edge cloud computing. Empirical results show that the algorithm is quick to adapt to new environments and performs better in all individual and system metrics compared to the state-of-the-art benchmark. Our algorithm also addresses various practical concerns with its modularized and asynchronous online training method. In addition to the cloud simulation, we test our algorithm on a single-board computer and show that it can make inference in 6 milliseconds.
Multi-Agent Reinforcement Learning for Long-Term Network Resource Allocation through Auction: a V2X Application
Jul 29, 2022



We formulate offloading of computational tasks from a dynamic group of mobile agents (e.g., cars) as decentralized decision making among autonomous agents. We design an interaction mechanism that incentivizes such agents to align private and system goals by balancing between competition and cooperation. In the static case, the mechanism provably has Nash equilibria with optimal resource allocation. In a dynamic environment, this mechanism's requirement of complete information is impossible to achieve. For such environments, we propose a novel multi-agent online learning algorithm that learns with partial, delayed and noisy state information, thus greatly reducing information need. Our algorithm is also capable of learning from long-term and sparse reward signals with varying delay. Empirical results from the simulation of a V2X application confirm that through learning, agents with the learning algorithm significantly improve both system and individual performance, reducing up to 30% of offloading failure rate, communication overhead and load variation, increasing computation resource utilization and fairness. Results also confirm the algorithm's good convergence and generalization property in different environments.
Submission to Generic Event Boundary Detection Challenge@CVPR 2022: Local Context Modeling and Global Boundary Decoding Approach
Jun 30, 2022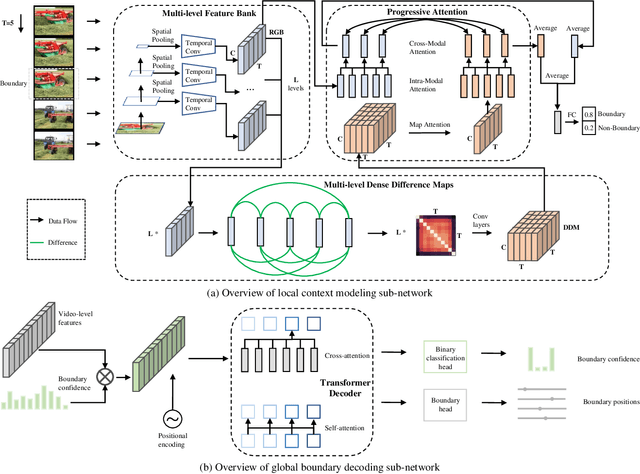
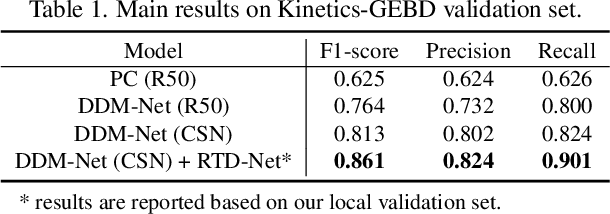
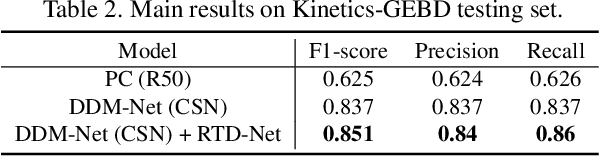
Generic event boundary detection (GEBD) is an important yet challenging task in video understanding, which aims at detecting the moments where humans naturally perceive event boundaries. In this paper, we present a local context modeling and global boundary decoding approach for GEBD task. Local context modeling sub-network is proposed to perceive diverse patterns of generic event boundaries, and it generates powerful video representations and reliable boundary confidence. Based on them, global boundary decoding sub-network is exploited to decode event boundaries from a global view. Our proposed method achieves 85.13% F1-score on Kinetics-GEBD testing set, which achieves a more than 22% F1-score boost compared to the baseline method. The code is available at https://github.com/JackyTown/GEBD_Challenge_CVPR2022.
A Novel Multi-Agent Scheduling Mechanism for Adaptation of Production Plans in Case of Supply Chain Disruptions
Jun 23, 2022



Manufacturing companies typically use sophisticated production planning systems optimizing production steps, often delivering near-optimal solutions. As a downside for delivering a near-optimal schedule, planning systems have high computational demands resulting in hours of computation. Under normal circumstances this is not issue if there is enough buffer time before implementation of the schedule (e.g. at night for the next day). However, in case of unexpected disruptions such as delayed part deliveries or defectively manufactured goods, the planned schedule may become invalid and swift replanning becomes necessary. Such immediate replanning is unsuited for existing optimal planners due to the computational requirements. This paper proposes a novel solution that can effectively and efficiently perform replanning in case of different types of disruptions using an existing plan. The approach is based on the idea to adhere to the existing schedule as much as possible, adapting it based on limited local changes. For that purpose an agent-based scheduling mechanism has been devised, in which agents represent materials and production sites and use local optimization techniques and negotiations to generate an adapted (sufficient, but non-optimal) schedule. The approach has been evaluated using real production data from Huawei, showing that efficient schedules are produced in short time. The system has been implemented as proof of concept and is currently reimplemented and transferred to a production system based on the Jadex agent platform.
Learning to Bid Long-Term: Multi-Agent Reinforcement Learning with Long-Term and Sparse Reward in Repeated Auction Games
Apr 05, 2022



We propose a multi-agent distributed reinforcement learning algorithm that balances between potentially conflicting short-term reward and sparse, delayed long-term reward, and learns with partial information in a dynamic environment. We compare different long-term rewards to incentivize the algorithm to maximize individual payoff and overall social welfare. We test the algorithm in two simulated auction games, and demonstrate that 1) our algorithm outperforms two benchmark algorithms in a direct competition, with cost to social welfare, and 2) our algorithm's aggressive competitive behavior can be guided with the long-term reward signal to maximize both individual payoff and overall social welfare.
Multi-Agent Distributed Reinforcement Learning for Making Decentralized Offloading Decisions
Apr 05, 2022



We formulate computation offloading as a decentralized decision-making problem with autonomous agents. We design an interaction mechanism that incentivizes agents to align private and system goals by balancing between competition and cooperation. The mechanism provably has Nash equilibria with optimal resource allocation in the static case. For a dynamic environment, we propose a novel multi-agent online learning algorithm that learns with partial, delayed and noisy state information, and a reward signal that reduces information need to a great extent. Empirical results confirm that through learning, agents significantly improve both system and individual performance, e.g., 40% offloading failure rate reduction, 32% communication overhead reduction, up to 38% computation resource savings in low contention, 18% utilization increase with reduced load variation in high contention, and improvement in fairness. Results also confirm the algorithm's good convergence and generalization property in significantly different environments.
Temporal Perceiver: A General Architecture for Arbitrary Boundary Detection
Mar 01, 2022



Generic Boundary Detection (GBD) aims at locating general boundaries that divide videos into semantically coherent and taxonomy-free units, and could server as an important pre-processing step for long-form video understanding. Previous research separately handle these different-level generic boundaries with specific designs of complicated deep networks from simple CNN to LSTM. Instead, in this paper, our objective is to develop a general yet simple architecture for arbitrary boundary detection in videos. To this end, we present Temporal Perceiver, a general architecture with Transformers, offering a unified solution to the detection of arbitrary generic boundaries. The core design is to introduce a small set of latent feature queries as anchors to compress the redundant input into fixed dimension via cross-attention blocks. Thanks to this fixed number of latent units, it reduces the quadratic complexity of attention operation to a linear form of input frames. Specifically, to leverage the coherence structure of videos, we construct two types of latent feature queries: boundary queries and context queries, which handle the semantic incoherence and coherence regions accordingly. Moreover, to guide the learning of latent feature queries, we propose an alignment loss on cross-attention to explicitly encourage the boundary queries to attend on the top possible boundaries. Finally, we present a sparse detection head on the compressed representations and directly output the final boundary detection results without any post-processing module. We test our Temporal Perceiver on a variety of detection benchmarks, ranging from shot-level, event-level, to scene-level GBD. Our method surpasses the previous state-of-the-art methods on all benchmarks, demonstrating the generalization ability of our temporal perceiver.
Practical Wide-Angle Portraits Correction with Deep Structured Models
Apr 28, 2021
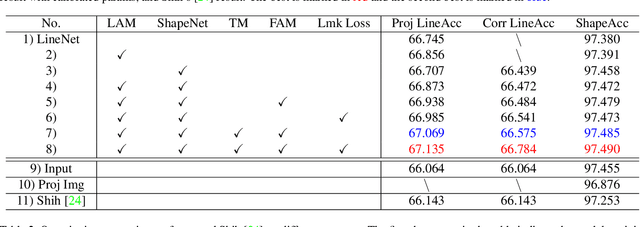
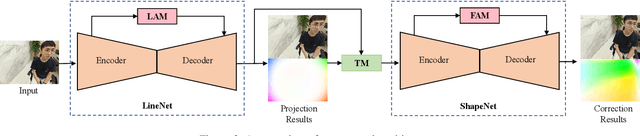

Wide-angle portraits often enjoy expanded views. However, they contain perspective distortions, especially noticeable when capturing group portrait photos, where the background is skewed and faces are stretched. This paper introduces the first deep learning based approach to remove such artifacts from freely-shot photos. Specifically, given a wide-angle portrait as input, we build a cascaded network consisting of a LineNet, a ShapeNet, and a transition module (TM), which corrects perspective distortions on the background, adapts to the stereographic projection on facial regions, and achieves smooth transitions between these two projections, accordingly. To train our network, we build the first perspective portrait dataset with a large diversity in identities, scenes and camera modules. For the quantitative evaluation, we introduce two novel metrics, line consistency and face congruence. Compared to the previous state-of-the-art approach, our method does not require camera distortion parameters. We demonstrate that our approach significantly outperforms the previous state-of-the-art approach both qualitatively and quantitatively.
Relaxed Transformer Decoders for Direct Action Proposal Generation
Feb 03, 2021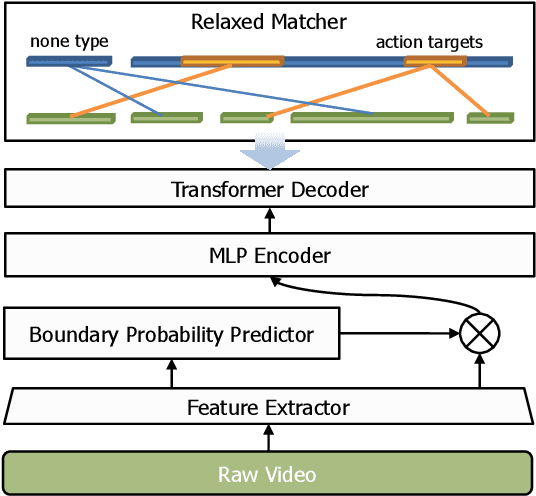
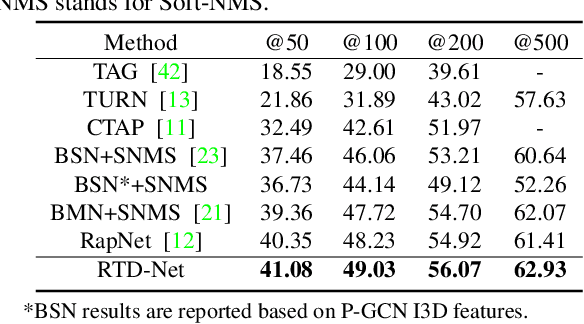
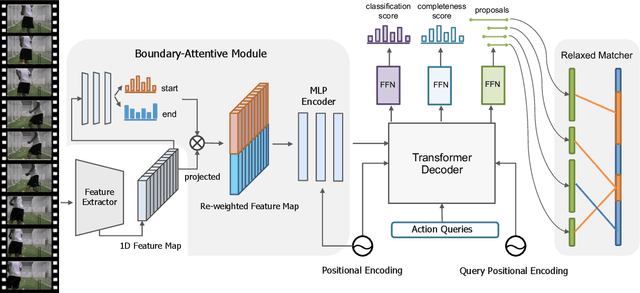

Temporal action proposal generation is an important and challenging task in video understanding, which aims at detecting all temporal segments containing action instances of interest. The existing proposal generation approaches are generally based on pre-defined anchor windows or heuristic bottom-up boundary matching strategies. This paper presents a simple and end-to-end learnable framework (RTD-Net) for direct action proposal generation, by re-purposing a Transformer-alike architecture. To tackle the essential visual difference between time and space, we make three important improvements over the original transformer detection framework (DETR). First, to deal with slowness prior in videos, we replace the original Transformer encoder with a boundary attentive module to better capture temporal information. Second, due to the ambiguous temporal boundary and relatively sparse annotations, we present a relaxed matching loss to relieve the strict criteria of single assignment to each groundtruth. Finally, we devise a three-branch head to further improve the proposal confidence estimation by explicitly predicting its completeness. Extensive experiments on THUMOS14 and ActivityNet-1.3 benchmarks demonstrate the effectiveness of RTD-Net, on both tasks of temporal action proposal generation and temporal action detection. Moreover, due to its simplicity in design, our RTD-Net is more efficient than previous proposal generation methods without non-maximum suppression post-processing. The code will be available at \url{https://github.com/MCG-NJU/RTD-Action}.