 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhaoyang Liu
Linear Gaussian Bounding Box Representation and Ring-Shaped Rotated Convolution for Oriented Object Detection
Nov 14, 2023




In oriented object detection, current representations of oriented bounding boxes (OBBs) often suffer from boundary discontinuity problem. Methods of designing continuous regression losses do not essentially solve this problem. Although Gaussian bounding box (GBB) representation avoids this problem, directly regressing GBB is susceptible to numerical instability. We propose linear GBB (LGBB), a novel OBB representation. By linearly transforming the elements of GBB, LGBB avoids the boundary discontinuity problem and has high numerical stability. In addition, existing convolution-based rotation-sensitive feature extraction methods only have local receptive fields, resulting in slow feature aggregation. We propose ring-shaped rotated convolution (RRC), which adaptively rotates feature maps to arbitrary orientations to extract rotation-sensitive features under a ring-shaped receptive field, rapidly aggregating features and contextual information. Experimental results demonstrate that LGBB and RRC achieve state-of-the-art performance. Furthermore, integrating LGBB and RRC into various models effectively improves detection accuracy.
ControlLLM: Augment Language Models with Tools by Searching on Graphs
Oct 30, 2023



We present ControlLLM, a novel framework that enables large language models (LLMs) to utilize multi-modal tools for solving complex real-world tasks. Despite the remarkable performance of LLMs, they still struggle with tool invocation due to ambiguous user prompts, inaccurate tool selection and parameterization, and inefficient tool scheduling. To overcome these challenges, our framework comprises three key components: (1) a \textit{task decomposer} that breaks down a complex task into clear subtasks with well-defined inputs and outputs; (2) a \textit{Thoughts-on-Graph (ToG) paradigm} that searches the optimal solution path on a pre-built tool graph, which specifies the parameter and dependency relations among different tools; and (3) an \textit{execution engine with a rich toolbox} that interprets the solution path and runs the tools efficiently on different computational devices. We evaluate our framework on diverse tasks involving image, audio, and video processing, demonstrating its superior accuracy, efficiency, and versatility compared to existing methods. The code is at https://github.com/OpenGVLab/ControlLLM .
Data-Juicer: A One-Stop Data Processing System for Large Language Models
Sep 05, 2023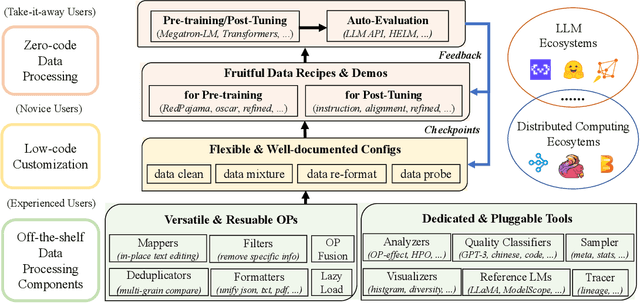
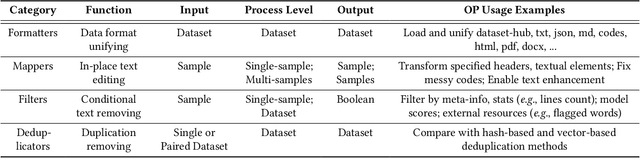
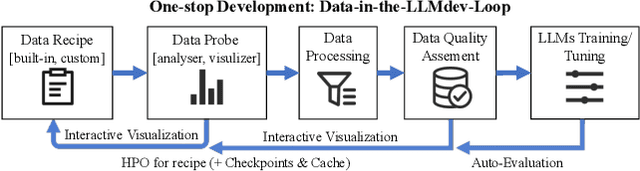
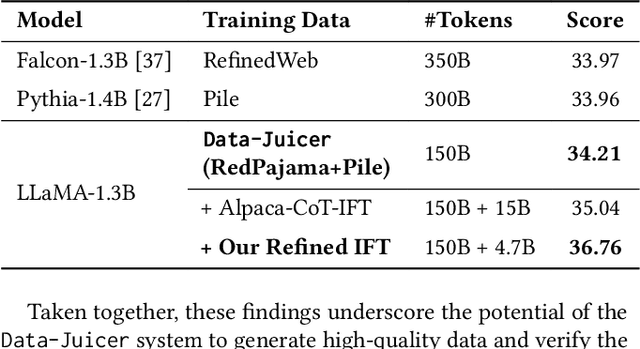
The immense evolution in Large Language Models (LLMs) has underscored the importance of massive, diverse, and high-quality data. Despite this, existing open-source tools for LLM data processing remain limited and mostly tailored to specific datasets, with an emphasis on the reproducibility of released data over adaptability and usability, inhibiting potential applications. In response, we propose a one-stop, powerful yet flexible and user-friendly LLM data processing system named Data-Juicer. Our system offers over 50 built-in versatile operators and pluggable tools, which synergize modularity, composability, and extensibility dedicated to diverse LLM data processing needs. By incorporating visualized and automatic evaluation capabilities, Data-Juicer enables a timely feedback loop to accelerate data processing and gain data insights. To enhance usability, Data-Juicer provides out-of-the-box components for users with various backgrounds, and fruitful data recipes for LLM pre-training and post-tuning usages. Further, we employ multi-facet system optimization and seamlessly integrate Data-Juicer with both LLM and distributed computing ecosystems, to enable efficient and scalable data processing. Empirical validation of the generated data recipes reveals considerable improvements in LLaMA performance for various pre-training and post-tuning cases, demonstrating up to 7.45% relative improvement of averaged score across 16 LLM benchmarks and 16.25% higher win rate using pair-wise GPT-4 evaluation. The system's efficiency and scalability are also validated, supported by up to 88.7% reduction in single-machine processing time, 77.1% and 73.1% less memory and CPU usage respectively, and 7.91x processing acceleration when utilizing distributed computing ecosystems. Our system, data recipes, and multiple tutorial demos are released, calling for broader research centered on LLM data.
InternGPT: Solving Vision-Centric Tasks by Interacting with ChatGPT Beyond Language
May 11, 2023


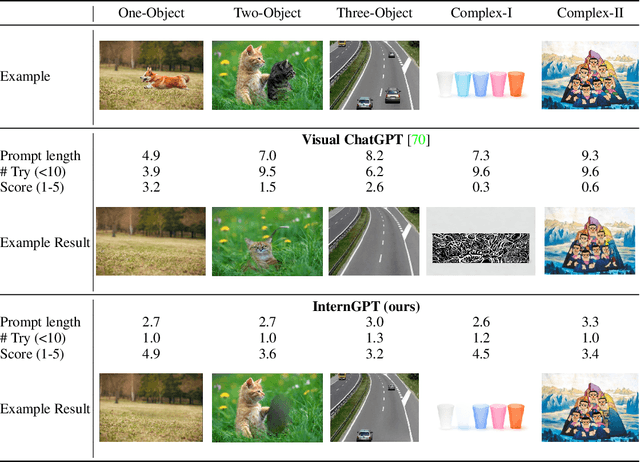
We present an interactive visual framework named InternGPT, or iGPT for short. The framework integrates chatbots that have planning and reasoning capabilities, such as ChatGPT, with non-verbal instructions like pointing movements that enable users to directly manipulate images or videos on the screen. Pointing (including gestures, cursors, etc.) movements can provide more flexibility and precision in performing vision-centric tasks that require fine-grained control, editing, and generation of visual content. The name InternGPT stands for \textbf{inter}action, \textbf{n}onverbal, and \textbf{chat}bots. Different from existing interactive systems that rely on pure language, by incorporating pointing instructions, the proposed iGPT significantly improves the efficiency of communication between users and chatbots, as well as the accuracy of chatbots in vision-centric tasks, especially in complicated visual scenarios where the number of objects is greater than 2. Additionally, in iGPT, an auxiliary control mechanism is used to improve the control capability of LLM, and a large vision-language model termed Husky is fine-tuned for high-quality multi-modal dialogue (impressing ChatGPT-3.5-turbo with 93.89\% GPT-4 Quality). We hope this work can spark new ideas and directions for future interactive visual systems. Welcome to watch the code at https://github.com/OpenGVLab/InternGPT.
VLG: General Video Recognition with Web Textual Knowledge
Dec 03, 2022



Video recognition in an open and dynamic world is quite challenging, as we need to handle different settings such as close-set, long-tail, few-shot and open-set. By leveraging semantic knowledge from noisy text descriptions crawled from the Internet, we focus on the general video recognition (GVR) problem of solving different recognition tasks within a unified framework. The core contribution of this paper is twofold. First, we build a comprehensive video recognition benchmark of Kinetics-GVR, including four sub-task datasets to cover the mentioned settings. To facilitate the research of GVR, we propose to utilize external textual knowledge from the Internet and provide multi-source text descriptions for all action classes. Second, inspired by the flexibility of language representation, we present a unified visual-linguistic framework (VLG) to solve the problem of GVR by an effective two-stage training paradigm. Our VLG is first pre-trained on video and language datasets to learn a shared feature space, and then devises a flexible bi-modal attention head to collaborate high-level semantic concepts under different settings. Extensive results show that our VLG obtains the state-of-the-art performance under four settings. The superior performance demonstrates the effectiveness and generalization ability of our proposed framework. We hope our work makes a step towards the general video recognition and could serve as a baseline for future research. The code and models will be available at https://github.com/MCG-NJU/VLG.
MotionBERT: Unified Pretraining for Human Motion Analysis
Oct 12, 2022



We present MotionBERT, a unified pretraining framework, to tackle different sub-tasks of human motion analysis including 3D pose estimation, skeleton-based action recognition, and mesh recovery. The proposed framework is capable of utilizing all kinds of human motion data resources, including motion capture data and in-the-wild videos. During pretraining, the pretext task requires the motion encoder to recover the underlying 3D motion from noisy partial 2D observations. The pretrained motion representation thus acquires geometric, kinematic, and physical knowledge about human motion and therefore can be easily transferred to multiple downstream tasks. We implement the motion encoder with a novel Dual-stream Spatio-temporal Transformer (DSTformer) neural network. It could capture long-range spatio-temporal relationships among the skeletal joints comprehensively and adaptively, exemplified by the lowest 3D pose estimation error so far when trained from scratch. More importantly, the proposed framework achieves state-of-the-art performance on all three downstream tasks by simply finetuning the pretrained motion encoder with 1-2 linear layers, which demonstrates the versatility of the learned motion representations.
Submission to Generic Event Boundary Detection Challenge@CVPR 2022: Local Context Modeling and Global Boundary Decoding Approach
Jun 30, 2022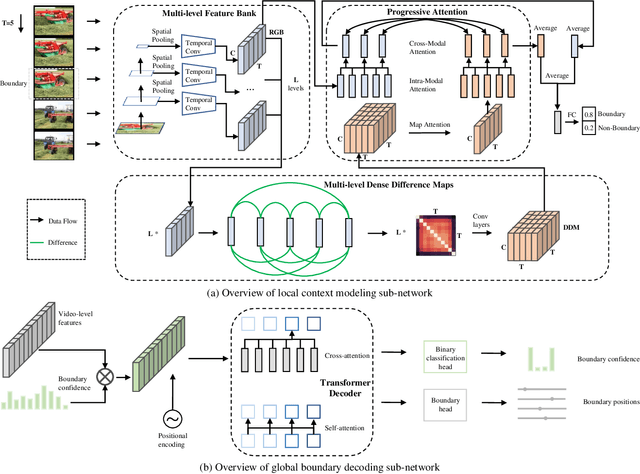
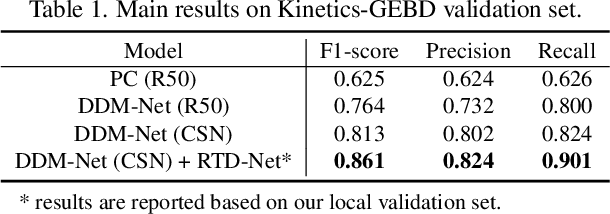
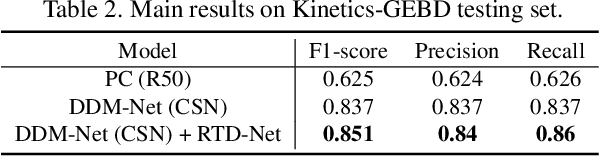
Generic event boundary detection (GEBD) is an important yet challenging task in video understanding, which aims at detecting the moments where humans naturally perceive event boundaries. In this paper, we present a local context modeling and global boundary decoding approach for GEBD task. Local context modeling sub-network is proposed to perceive diverse patterns of generic event boundaries, and it generates powerful video representations and reliable boundary confidence. Based on them, global boundary decoding sub-network is exploited to decode event boundaries from a global view. Our proposed method achieves 85.13% F1-score on Kinetics-GEBD testing set, which achieves a more than 22% F1-score boost compared to the baseline method. The code is available at https://github.com/JackyTown/GEBD_Challenge_CVPR2022.
Joint-Modal Label Denoising for Weakly-Supervised Audio-Visual Video Parsing
Apr 28, 2022



This paper focuses on the weakly-supervised audio-visual video parsing task, which aims to recognize all events belonging to each modality and localize their temporal boundaries. This task is challenging because only overall labels indicating the video events are provided for training. However, an event might be labeled but not appear in one of the modalities, which results in a modality-specific noisy label problem. Motivated by two observations that networks tend to learn clean samples first and that a labeled event would appear in at least one modality, we propose a training strategy to identify and remove modality-specific noisy labels dynamically. Specifically, we sort the losses of all instances within a mini-batch individually in each modality, then select noisy samples according to relationships between intra-modal and inter-modal losses. Besides, we also propose a simple but valid noise ratio estimation method by calculating the proportion of instances whose confidence is below a preset threshold. Our method makes large improvements over the previous state of the arts (e.g., from 60.0% to 63.8% in segment-level visual metric), which demonstrates the effectiveness of our approach.
Progressive Attention on Multi-Level Dense Difference Maps for Generic Event Boundary Detection
Dec 09, 2021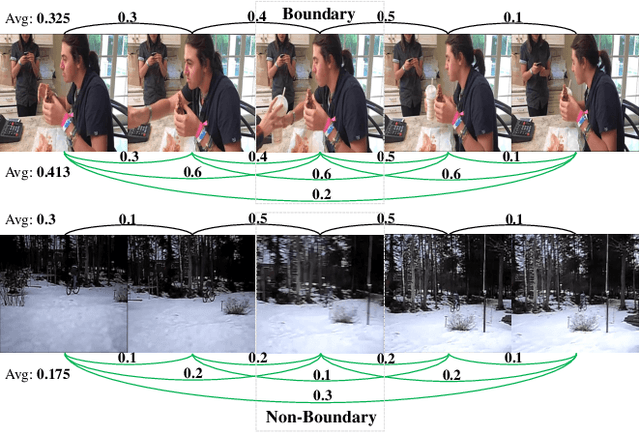
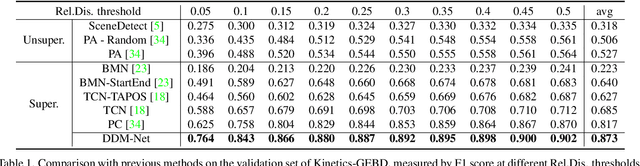
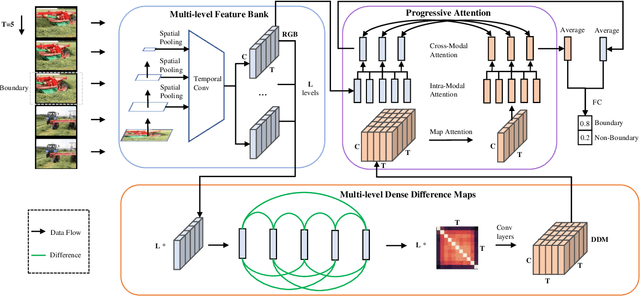
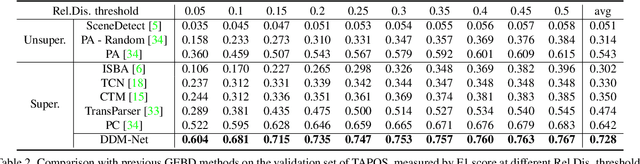
Generic event boundary detection is an important yet challenging task in video understanding, which aims at detecting the moments where humans naturally perceive event boundaries. The main challenge of this task is perceiving various temporal variations of diverse event boundaries. To this end, this paper presents an effective and end-to-end learnable framework (DDM-Net). To tackle the diversity and complicated semantics of event boundaries, we make three notable improvements. First, we construct a feature bank to store multi-level features of space and time, prepared for difference calculation at multiple scales. Second, to alleviate inadequate temporal modeling of previous methods, we present dense difference maps (DDM) to comprehensively characterize the motion pattern. Finally, we exploit progressive attention on multi-level DDM to jointly aggregate appearance and motion clues. As a result, DDM-Net respectively achieves a significant boost of 14% and 8% on Kinetics-GEBD and TAPOS benchmark, and outperforms the top-1 winner solution of LOVEU Challenge@CVPR 2021 without bells and whistles. The state-of-the-art result demonstrates the effectiveness of richer motion representation and more sophisticated aggregation, in handling the diversity of generic event boundary detection. Our codes will be made available soon.
CausCF: Causal Collaborative Filtering for RecommendationEffect Estimation
May 28, 2021
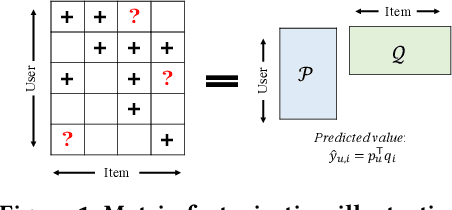
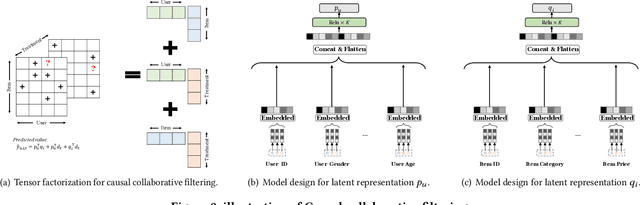
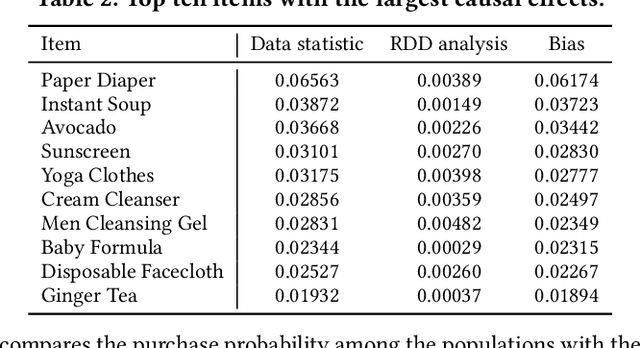
To improve user experience and profits of corporations, modern industrial recommender systems usually aim to select the items that are most likely to be interacted with (e.g., clicks and purchases). However, they overlook the fact that users may purchase the items even without recommendations. To select these effective items, it is essential to estimate the causal effect of recommendations. The real effective items are the ones which can contribute to purchase probability uplift. Nevertheless, it is difficult to obtain the real causal effect since we can only recommend or not recommend an item to a user at one time. Furthermore, previous works usually rely on the randomized controlled trial~(RCT) experiment to evaluate their performance. However, it is usually not practicable in the recommendation scenario due to its unavailable time consuming. To tackle these problems, in this paper, we propose a causal collaborative filtering~(CausCF) method inspired by the widely adopted collaborative filtering~(CF) technique. It is based on the idea that similar users not only have a similar taste on items, but also have similar treatment effect under recommendations. CausCF extends the classical matrix factorization to the tensor factorization with three dimensions -- user, item, and treatment. Furthermore, we also employs regression discontinuity design (RDD) to evaluate the precision of the estimated causal effects from different models. With the testable assumptions, RDD analysis can provide an unbiased causal conclusion without RCT experiments. Through dedicated experiments on both the public datasets and the industrial application, we demonstrate the effectiveness of our proposed CausCF on the causal effect estimation and ranking performance improvement.