 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuexiang Xie
When to Trust LLMs: Aligning Confidence with Response Quality
Apr 26, 2024
Despite the success of large language models (LLMs) in natural language generation, much evidence shows that LLMs may produce incorrect or nonsensical text. This limitation highlights the importance of discerning when to trust LLMs, especially in safety-critical domains. Existing methods, which rely on verbalizing confidence to tell the reliability by inducing top-k responses and sampling-aggregating multiple responses, often fail, due to the lack of objective guidance of confidence. To address this, we propose CONfidence-Quality-ORDerpreserving alignment approach (CONQORD), leveraging reinforcement learning with a tailored dual-component reward function. This function encompasses quality reward and orderpreserving alignment reward functions. Specifically, the order-preserving reward incentivizes the model to verbalize greater confidence for responses of higher quality to align the order of confidence and quality. Experiments demonstrate that our CONQORD significantly improves the alignment performance between confidence levels and response accuracy, without causing the model to become over-cautious. Furthermore, the aligned confidence provided by CONQORD informs when to trust LLMs, and acts as a determinant for initiating the retrieval process of external knowledge. Aligning confidence with response quality ensures more transparent and reliable responses, providing better trustworthiness.
Tunable Soft Prompts are Messengers in Federated Learning
Nov 12, 2023Federated learning (FL) enables multiple participants to collaboratively train machine learning models using decentralized data sources, alleviating privacy concerns that arise from directly sharing local data. However, the lack of model privacy protection in FL becomes an unneglectable challenge, especially when people want to federally finetune models based on a proprietary large language model. In this study, we propose a novel FL training approach that accomplishes information exchange among participants via tunable soft prompts. These soft prompts, updated and transmitted between the server and clients, assume the role of the global model parameters and serve as messengers to deliver useful knowledge from the local data and global model. As the global model itself is not required to be shared and the local training is conducted based on an auxiliary model with fewer parameters than the global model, the proposed approach provides protection for the global model while reducing communication and computation costs in FL. Extensive experiments show the effectiveness of the proposed approach compared to several baselines. We have released the source code at \url{https://github.com/alibaba/FederatedScope/tree/fedsp/federatedscope/nlp/fedsp}.
Data-Juicer: A One-Stop Data Processing System for Large Language Models
Sep 05, 2023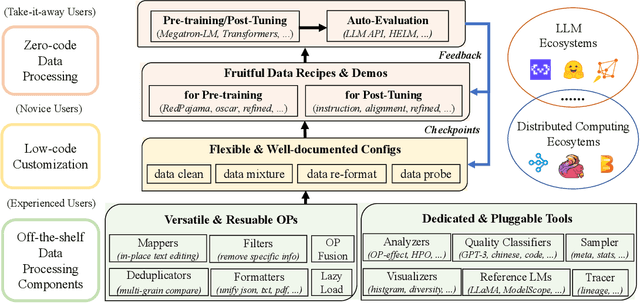
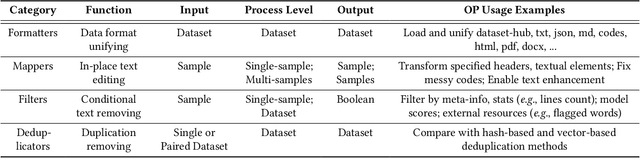
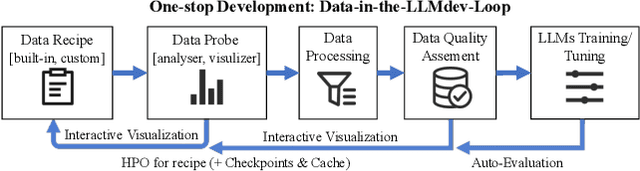
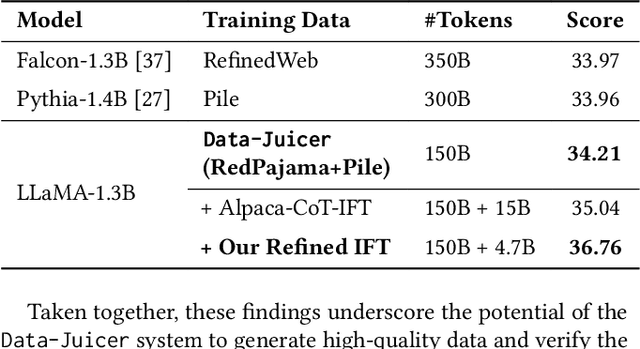
The immense evolution in Large Language Models (LLMs) has underscored the importance of massive, diverse, and high-quality data. Despite this, existing open-source tools for LLM data processing remain limited and mostly tailored to specific datasets, with an emphasis on the reproducibility of released data over adaptability and usability, inhibiting potential applications. In response, we propose a one-stop, powerful yet flexible and user-friendly LLM data processing system named Data-Juicer. Our system offers over 50 built-in versatile operators and pluggable tools, which synergize modularity, composability, and extensibility dedicated to diverse LLM data processing needs. By incorporating visualized and automatic evaluation capabilities, Data-Juicer enables a timely feedback loop to accelerate data processing and gain data insights. To enhance usability, Data-Juicer provides out-of-the-box components for users with various backgrounds, and fruitful data recipes for LLM pre-training and post-tuning usages. Further, we employ multi-facet system optimization and seamlessly integrate Data-Juicer with both LLM and distributed computing ecosystems, to enable efficient and scalable data processing. Empirical validation of the generated data recipes reveals considerable improvements in LLaMA performance for various pre-training and post-tuning cases, demonstrating up to 7.45% relative improvement of averaged score across 16 LLM benchmarks and 16.25% higher win rate using pair-wise GPT-4 evaluation. The system's efficiency and scalability are also validated, supported by up to 88.7% reduction in single-machine processing time, 77.1% and 73.1% less memory and CPU usage respectively, and 7.91x processing acceleration when utilizing distributed computing ecosystems. Our system, data recipes, and multiple tutorial demos are released, calling for broader research centered on LLM data.
FederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning
Sep 01, 2023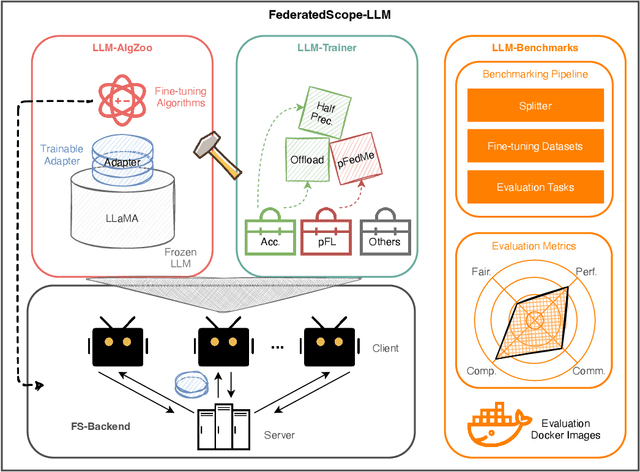


LLMs have demonstrated great capabilities in various NLP tasks. Different entities can further improve the performance of those LLMs on their specific downstream tasks by fine-tuning LLMs. When several entities have similar interested tasks, but their data cannot be shared because of privacy concerns regulations, federated learning (FL) is a mainstream solution to leverage the data of different entities. However, fine-tuning LLMs in federated learning settings still lacks adequate support from existing FL frameworks because it has to deal with optimizing the consumption of significant communication and computational resources, data preparation for different tasks, and distinct information protection demands. This paper first discusses these challenges of federated fine-tuning LLMs, and introduces our package FS-LLM as a main contribution, which consists of the following components: (1) we build an end-to-end benchmarking pipeline, automizing the processes of dataset preprocessing, federated fine-tuning execution, and performance evaluation on federated LLM fine-tuning; (2) we provide comprehensive federated parameter-efficient fine-tuning algorithm implementations and versatile programming interfaces for future extension in FL scenarios with low communication and computation costs, even without accessing the full model; (3) we adopt several accelerating and resource-efficient operators for fine-tuning LLMs with limited resources and the flexible pluggable sub-routines for interdisciplinary study. We conduct extensive experiments to validate the effectiveness of FS-LLM and benchmark advanced LLMs with state-of-the-art parameter-efficient fine-tuning algorithms in FL settings, which also yields valuable insights into federated fine-tuning LLMs for the research community. To facilitate further research and adoption, we release FS-LLM at https://github.com/alibaba/FederatedScope/tree/llm.
Counterfactual Debiasing for Generating Factually Consistent Text Summaries
May 18, 2023



Despite substantial progress in abstractive text summarization to generate fluent and informative texts, the factual inconsistency in the generated summaries remains an important yet challenging problem to be solved. In this paper, we construct causal graphs for abstractive text summarization and identify the intrinsic causes of the factual inconsistency, i.e., the language bias and irrelevancy bias, and further propose a debiasing framework, named CoFactSum, to alleviate the causal effects of these biases by counterfactual estimation. Specifically, the proposed CoFactSum provides two counterfactual estimation strategies, i.e., Explicit Counterfactual Masking with an explicit dynamic masking strategy, and Implicit Counterfactual Training with an implicit discriminative cross-attention mechanism. Meanwhile, we design a Debiasing Degree Adjustment mechanism to dynamically adapt the debiasing degree at each decoding step. Extensive experiments on two widely-used summarization datasets demonstrate the effectiveness of CoFactSum in enhancing the factual consistency of generated summaries compared with several baselines.
FS-Real: Towards Real-World Cross-Device Federated Learning
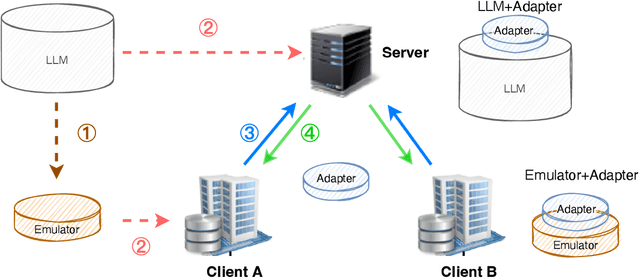
Mar 23, 2023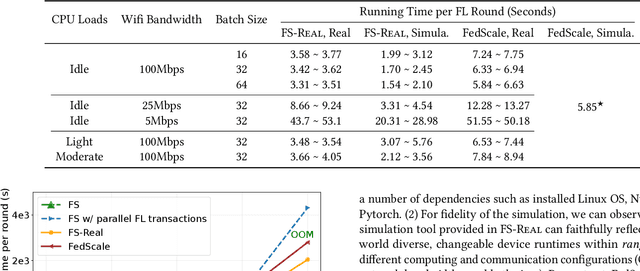
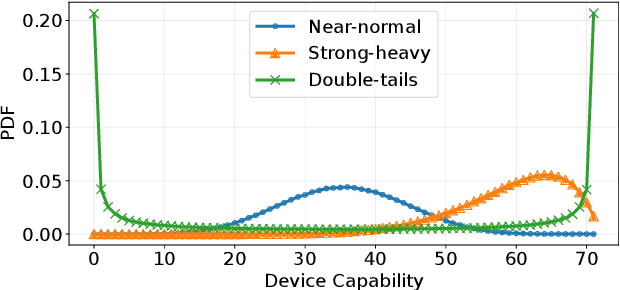

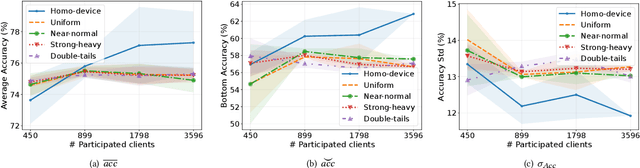
Federated Learning (FL) aims to train high-quality models in collaboration with distributed clients while not uploading their local data, which attracts increasing attention in both academia and industry. However, there is still a considerable gap between the flourishing FL research and real-world scenarios, mainly caused by the characteristics of heterogeneous devices and its scales. Most existing works conduct evaluations with homogeneous devices, which are mismatched with the diversity and variability of heterogeneous devices in real-world scenarios. Moreover, it is challenging to conduct research and development at scale with heterogeneous devices due to limited resources and complex software stacks. These two key factors are important yet underexplored in FL research as they directly impact the FL training dynamics and final performance, making the effectiveness and usability of FL algorithms unclear. To bridge the gap, in this paper, we propose an efficient and scalable prototyping system for real-world cross-device FL, FS-Real. It supports heterogeneous device runtime, contains parallelism and robustness enhanced FL server, and provides implementations and extensibility for advanced FL utility features such as personalization, communication compression and asynchronous aggregation. To demonstrate the usability and efficiency of FS-Real, we conduct extensive experiments with various device distributions, quantify and analyze the effect of the heterogeneous device and various scales, and further provide insights and open discussions about real-world FL scenarios. Our system is released to help to pave the way for further real-world FL research and broad applications involving diverse devices and scales.
Collaborating Heterogeneous Natural Language Processing Tasks via Federated Learning
Dec 12, 2022



The increasing privacy concerns on personal private text data promote the development of federated learning (FL) in recent years. However, the existing studies on applying FL in NLP are not suitable to coordinate participants with heterogeneous or private learning objectives. In this study, we further broaden the application scope of FL in NLP by proposing an Assign-Then-Contrast (denoted as ATC) framework, which enables clients with heterogeneous NLP tasks to construct an FL course and learn useful knowledge from each other. Specifically, the clients are suggested to first perform local training with the unified tasks assigned by the server rather than using their own learning objectives, which is called the Assign training stage. After that, in the Contrast training stage, clients train with different local learning objectives and exchange knowledge with other clients who contribute consistent and useful model updates. We conduct extensive experiments on six widely-used datasets covering both Natural Language Understanding (NLU) and Natural Language Generation (NLG) tasks, and the proposed ATC framework achieves significant improvements compared with various baseline methods. The source code is available at \url{https://github.com/alibaba/FederatedScope/tree/master/federatedscope/nlp/hetero_tasks}.
A Benchmark for Federated Hetero-Task Learning
Jun 21, 2022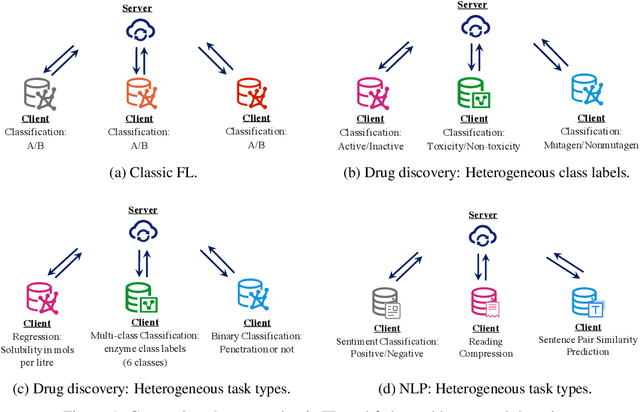
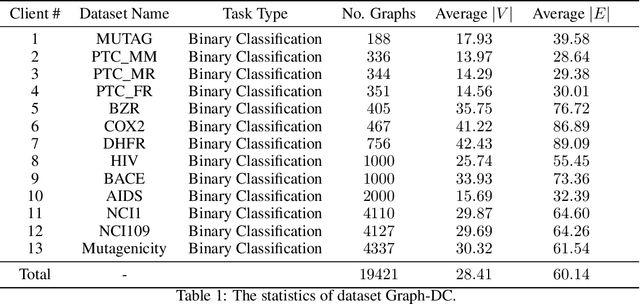
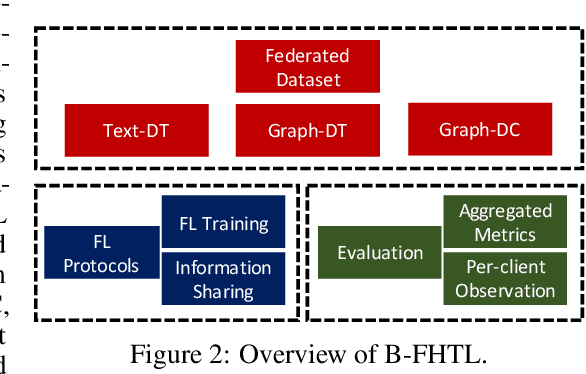
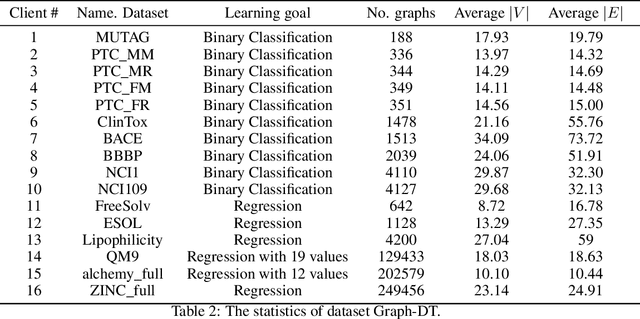
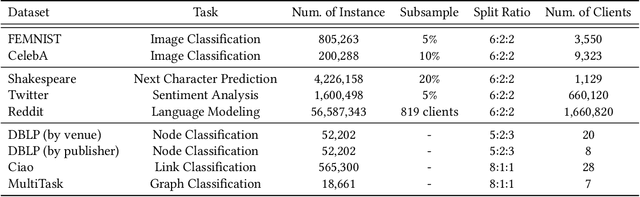
To investigate the heterogeneity in federated learning in real-world scenarios, we generalize the classic federated learning to federated hetero-task learning, which emphasizes the inconsistency across the participants in federated learning in terms of both data distribution and learning tasks. We also present B-FHTL, a federated hetero-task learning benchmark consisting of simulation dataset, FL protocols and a unified evaluation mechanism. B-FHTL dataset contains three well-designed federated learning tasks with increasing heterogeneity. Each task simulates the clients with different non-IID data and learning tasks. To ensure fair comparison among different FL algorithms, B-FHTL builds in a full suite of FL protocols by providing high-level APIs to avoid privacy leakage, and presets most common evaluation metrics spanning across different learning tasks, such as regression, classification, text generation and etc. Furthermore, we compare the FL algorithms in fields of federated multi-task learning, federated personalization and federated meta learning within B-FHTL, and highlight the influence of heterogeneity and difficulties of federated hetero-task learning. Our benchmark, including the federated dataset, protocols, the evaluation mechanism and the preliminary experiment, is open-sourced at https://github.com/alibaba/FederatedScope/tree/master/benchmark/B-FHTL
FederatedScope-GNN: Towards a Unified, Comprehensive and Efficient Package for Federated Graph Learning
Apr 14, 2022



The incredible development of federated learning (FL) has benefited various tasks in the domains of computer vision and natural language processing, and the existing frameworks such as TFF and FATE has made the deployment easy in real-world applications. However, federated graph learning (FGL), even though graph data are prevalent, has not been well supported due to its unique characteristics and requirements. The lack of FGL-related framework increases the efforts for accomplishing reproducible research and deploying in real-world applications. Motivated by such strong demand, in this paper, we first discuss the challenges in creating an easy-to-use FGL package and accordingly present our implemented package FederatedScope-GNN (FS-G), which provides (1) a unified view for modularizing and expressing FGL algorithms; (2) comprehensive DataZoo and ModelZoo for out-of-the-box FGL capability; (3) an efficient model auto-tuning component; and (4) off-the-shelf privacy attack and defense abilities. We validate the effectiveness of FS-G by conducting extensive experiments, which simultaneously gains many valuable insights about FGL for the community. Moreover, we employ FS-G to serve the FGL application in real-world E-commerce scenarios, where the attained improvements indicate great potential business benefits. We publicly release FS-G, as submodules of FederatedScope, at https://github.com/alibaba/FederatedScope to promote FGL's research and enable broad applications that would otherwise be infeasible due to the lack of a dedicated package.
FederatedScope: A Comprehensive and Flexible Federated Learning Platform via Message Passing
Apr 11, 2022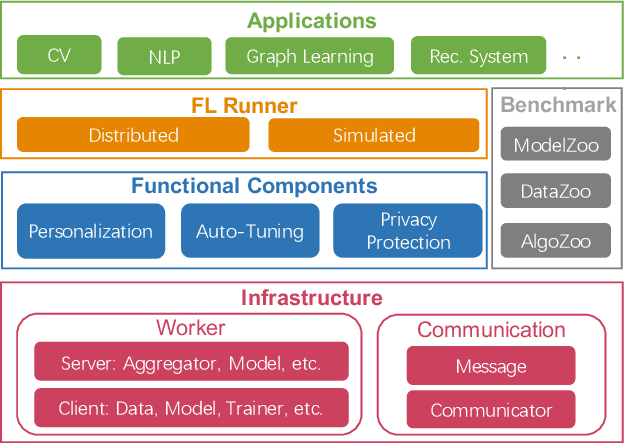


Although remarkable progress has been made by the existing federated learning (FL) platforms to provide fundamental functionalities for development, these FL platforms cannot well satisfy burgeoning demands from rapidly growing FL tasks in both academia and industry. To fill this gap, in this paper, we propose a novel and comprehensive federated learning platform, named FederatedScope, which is based on a message-oriented framework. Towards more handy and flexible support for various FL tasks, FederatedScope frames an FL course into several rounds of message passing among participants, and allows developers to customize new types of exchanged messages and the corresponding handlers for various FL applications. Compared to the procedural framework, the proposed message-oriented framework is more flexible to express heterogeneous message exchange and the rich behaviors of participants, and provides a unified view for both simulation and deployment. Besides, we also include several functional components in FederatedScope, such as personalization, auto-tuning, and privacy protection, to satisfy the requirements of frontier studies in FL. We conduct a series of experiments on the provided easy-to-use and comprehensive FL benchmarks to validate the correctness and efficiency of FederatedScope. We have released FederatedScope for users on https://github.com/alibaba/FederatedScope to promote research and industrial deployment of federated learning in a variety of real-world applications.