 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDawei Gao
Less is More: Data Value Estimation for Visual Instruction Tuning
Mar 21, 2024
Visual instruction tuning is the key to building multimodal large language models (MLLMs), which greatly improves the reasoning capabilities of large language models (LLMs) in vision scenario. However, existing MLLMs mostly rely on a mixture of multiple highly diverse visual instruction datasets for training (even more than a million instructions), which may introduce data redundancy. To investigate this issue, we conduct a series of empirical studies, which reveal a significant redundancy within the visual instruction datasets, and show that greatly reducing the amount of several instruction dataset even do not affect the performance. Based on the findings, we propose a new data selection approach TIVE, to eliminate redundancy within visual instruction data. TIVE first estimates the task-level and instance-level value of the visual instructions based on computed gradients. Then, according to the estimated values, TIVE determines the task proportion within the visual instructions, and selects representative instances to compose a smaller visual instruction subset for training. Experiments on LLaVA-1.5 show that our approach using only about 7.5% data can achieve comparable performance as the full-data fine-tuned model across seven benchmarks, even surpassing it on four of the benchmarks. Our code and data will be publicly released.
AgentScope: A Flexible yet Robust Multi-Agent Platform
Feb 21, 2024With the rapid advancement of Large Language Models (LLMs), significant progress has been made in multi-agent applications. However, the complexities in coordinating agents' cooperation and LLMs' erratic performance pose notable challenges in developing robust and efficient multi-agent applications. To tackle these challenges, we propose AgentScope, a developer-centric multi-agent platform with message exchange as its core communication mechanism. Together with abundant syntactic tools, built-in resources, and user-friendly interactions, our communication mechanism significantly reduces the barriers to both development and understanding. Towards robust and flexible multi-agent application, AgentScope provides both built-in and customizable fault tolerance mechanisms while it is also armed with system-level supports for multi-modal data generation, storage and transmission. Additionally, we design an actor-based distribution framework, enabling easy conversion between local and distributed deployments and automatic parallel optimization without extra effort. With these features, AgentScope empowers developers to build applications that fully realize the potential of intelligent agents. We have released AgentScope at https://github.com/modelscope/agentscope, and hope AgentScope invites wider participation and innovation in this fast-moving field.
Data-CUBE: Data Curriculum for Instruction-based Sentence Representation Learning
Jan 07, 2024Recently, multi-task instruction tuning has been applied into sentence representation learning, which endows the capability of generating specific representations with the guidance of task instruction, exhibiting strong generalization ability on new tasks. However, these methods mostly neglect the potential interference problems across different tasks and instances, which may affect the training and convergence of the model. To address it, we propose a data curriculum method, namely Data-CUBE, that arranges the orders of all the multi-task data for training, to minimize the interference risks from the two views. In the task level, we aim to find the optimal task order to minimize the total cross-task interference risk, which is exactly the traveling salesman problem, hence we utilize a simulated annealing algorithm to find its solution. In the instance level, we measure the difficulty of all instances per task, then divide them into the easy-to-difficult mini-batches for training. Experiments on MTEB sentence representation evaluation tasks show that our approach can boost the performance of state-of-the-art methods. Our code and data are publicly available at the link: \url{https://github.com/RUCAIBox/Data-CUBE}.
Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation
Sep 08, 2023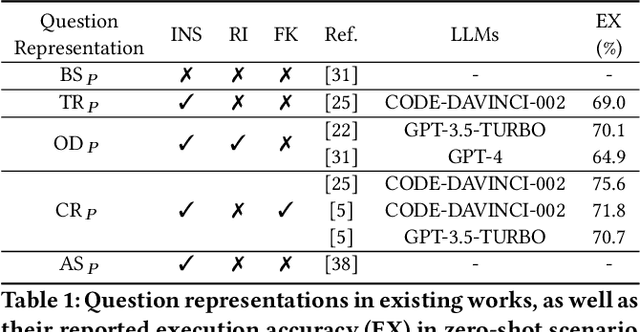


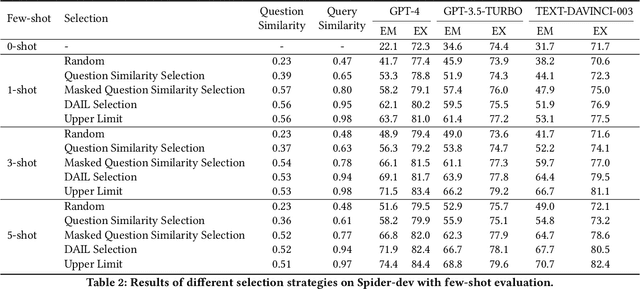
Large language models (LLMs) have emerged as a new paradigm for Text-to-SQL task. However, the absence of a systematical benchmark inhibits the development of designing effective, efficient and economic LLM-based Text-to-SQL solutions. To address this challenge, in this paper, we first conduct a systematical and extensive comparison over existing prompt engineering methods, including question representation, example selection and example organization, and with these experimental results, we elaborate their pros and cons. Based on these findings, we propose a new integrated solution, named DAIL-SQL, which refreshes the Spider leaderboard with 86.6% execution accuracy and sets a new bar. To explore the potential of open-source LLM, we investigate them in various scenarios, and further enhance their performance with supervised fine-tuning. Our explorations highlight open-source LLMs' potential in Text-to-SQL, as well as the advantages and disadvantages of the supervised fine-tuning. Additionally, towards an efficient and economic LLM-based Text-to-SQL solution, we emphasize the token efficiency in prompt engineering and compare the prior studies under this metric. We hope that our work provides a deeper understanding of Text-to-SQL with LLMs, and inspires further investigations and broad applications.
Data-Juicer: A One-Stop Data Processing System for Large Language Models
Sep 05, 2023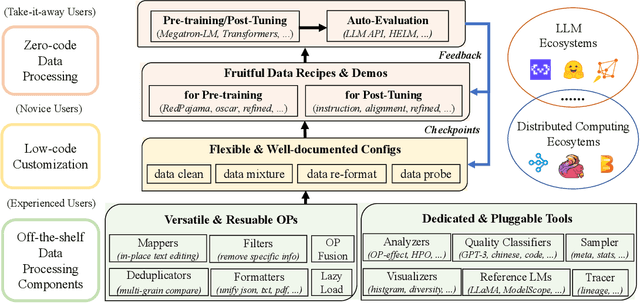
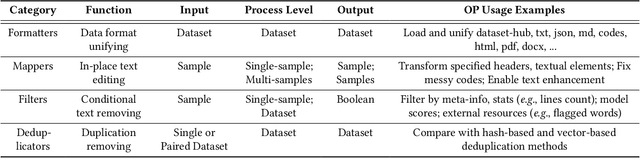
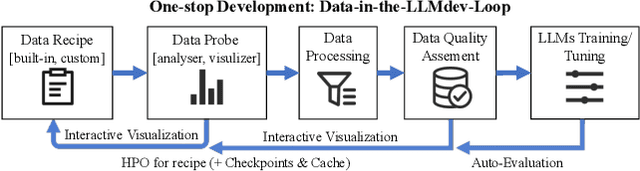
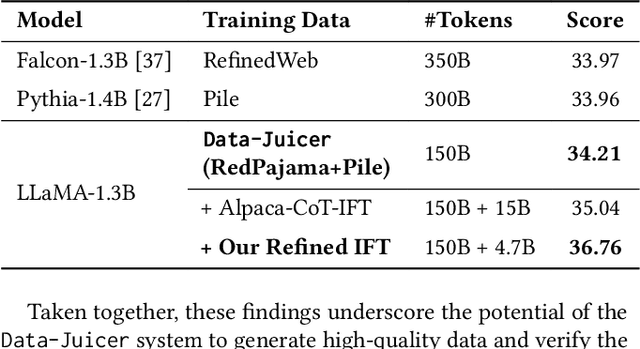
The immense evolution in Large Language Models (LLMs) has underscored the importance of massive, diverse, and high-quality data. Despite this, existing open-source tools for LLM data processing remain limited and mostly tailored to specific datasets, with an emphasis on the reproducibility of released data over adaptability and usability, inhibiting potential applications. In response, we propose a one-stop, powerful yet flexible and user-friendly LLM data processing system named Data-Juicer. Our system offers over 50 built-in versatile operators and pluggable tools, which synergize modularity, composability, and extensibility dedicated to diverse LLM data processing needs. By incorporating visualized and automatic evaluation capabilities, Data-Juicer enables a timely feedback loop to accelerate data processing and gain data insights. To enhance usability, Data-Juicer provides out-of-the-box components for users with various backgrounds, and fruitful data recipes for LLM pre-training and post-tuning usages. Further, we employ multi-facet system optimization and seamlessly integrate Data-Juicer with both LLM and distributed computing ecosystems, to enable efficient and scalable data processing. Empirical validation of the generated data recipes reveals considerable improvements in LLaMA performance for various pre-training and post-tuning cases, demonstrating up to 7.45% relative improvement of averaged score across 16 LLM benchmarks and 16.25% higher win rate using pair-wise GPT-4 evaluation. The system's efficiency and scalability are also validated, supported by up to 88.7% reduction in single-machine processing time, 77.1% and 73.1% less memory and CPU usage respectively, and 7.91x processing acceleration when utilizing distributed computing ecosystems. Our system, data recipes, and multiple tutorial demos are released, calling for broader research centered on LLM data.
FederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning
Sep 01, 2023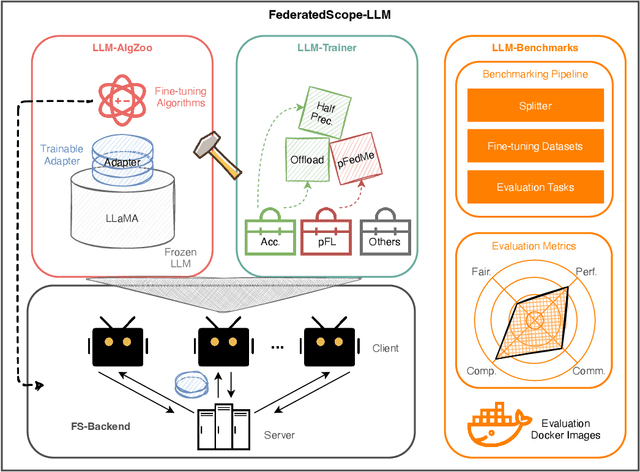

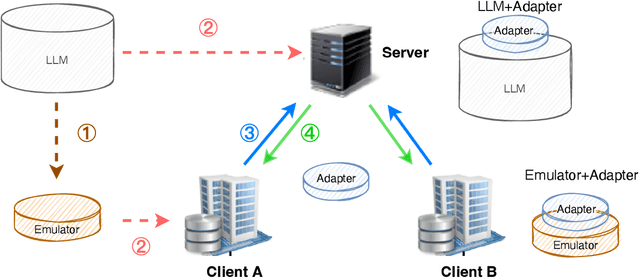

LLMs have demonstrated great capabilities in various NLP tasks. Different entities can further improve the performance of those LLMs on their specific downstream tasks by fine-tuning LLMs. When several entities have similar interested tasks, but their data cannot be shared because of privacy concerns regulations, federated learning (FL) is a mainstream solution to leverage the data of different entities. However, fine-tuning LLMs in federated learning settings still lacks adequate support from existing FL frameworks because it has to deal with optimizing the consumption of significant communication and computational resources, data preparation for different tasks, and distinct information protection demands. This paper first discusses these challenges of federated fine-tuning LLMs, and introduces our package FS-LLM as a main contribution, which consists of the following components: (1) we build an end-to-end benchmarking pipeline, automizing the processes of dataset preprocessing, federated fine-tuning execution, and performance evaluation on federated LLM fine-tuning; (2) we provide comprehensive federated parameter-efficient fine-tuning algorithm implementations and versatile programming interfaces for future extension in FL scenarios with low communication and computation costs, even without accessing the full model; (3) we adopt several accelerating and resource-efficient operators for fine-tuning LLMs with limited resources and the flexible pluggable sub-routines for interdisciplinary study. We conduct extensive experiments to validate the effectiveness of FS-LLM and benchmark advanced LLMs with state-of-the-art parameter-efficient fine-tuning algorithms in FL settings, which also yields valuable insights into federated fine-tuning LLMs for the research community. To facilitate further research and adoption, we release FS-LLM at https://github.com/alibaba/FederatedScope/tree/llm.
Message Passing Based Block Sparse Signal Recovery for DOA Estimation Using Large Arrays
Sep 01, 2023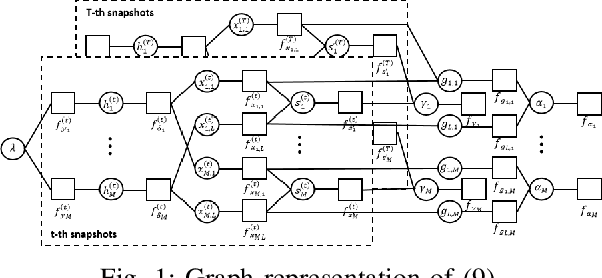



This work deals with directional of arrival (DOA) estimation with a large antenna array. We first develop a novel signal model with a sparse system transfer matrix using an inverse discrete Fourier transform (DFT) operation, which leads to the formulation of a structured block sparse signal recovery problem with a sparse sensing matrix. This enables the development of a low complexity message passing based Bayesian algorithm with a factor graph representation. Simulation results demonstrate the superior performance of the proposed method.
Do Emergent Abilities Exist in Quantized Large Language Models: An Empirical Study
Jul 26, 2023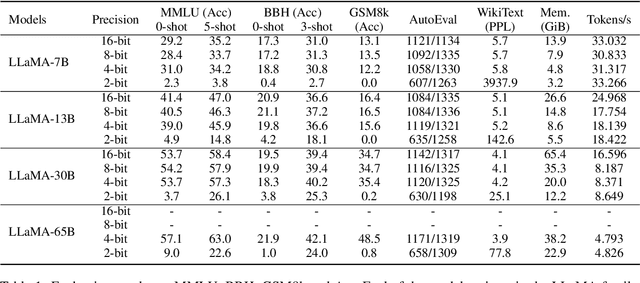
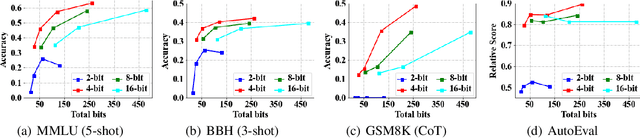


Despite the superior performance, Large Language Models~(LLMs) require significant computational resources for deployment and use. To overcome this issue, quantization methods have been widely applied to reduce the memory footprint of LLMs as well as increasing the inference rate. However, a major challenge is that low-bit quantization methods often lead to performance degradation. It is important to understand how quantization impacts the capacity of LLMs. Different from previous studies focused on overall performance, this work aims to investigate the impact of quantization on \emph{emergent abilities}, which are important characteristics that distinguish LLMs from small language models. Specially, we examine the abilities of in-context learning, chain-of-thought reasoning, and instruction-following in quantized LLMs. Our empirical experiments show that these emergent abilities still exist in 4-bit quantization models, while 2-bit models encounter severe performance degradation on the test of these abilities. To improve the performance of low-bit models, we conduct two special experiments: (1) fine-gained impact analysis that studies which components (or substructures) are more sensitive to quantization, and (2) performance compensation through model fine-tuning. Our work derives a series of important findings to understand the impact of quantization on emergent abilities, and sheds lights on the possibilities of extremely low-bit quantization for LLMs.
Efficient Personalized Federated Learning via Sparse Model-Adaptation
May 04, 2023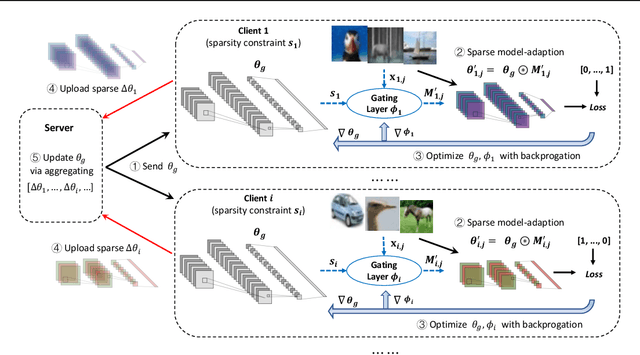
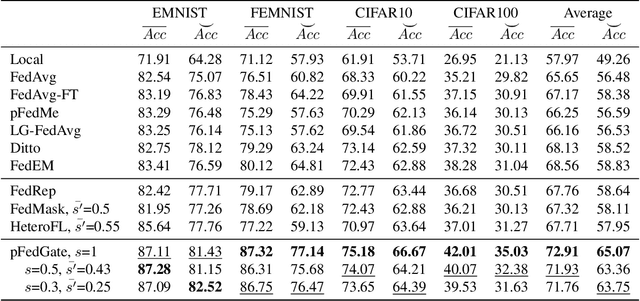
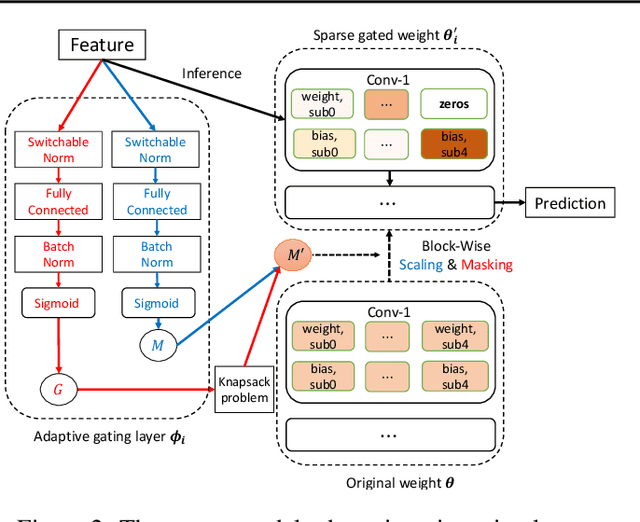
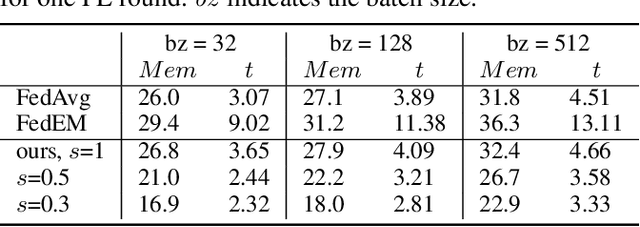
Federated Learning (FL) aims to train machine learning models for multiple clients without sharing their own private data. Due to the heterogeneity of clients' local data distribution, recent studies explore the personalized FL that learns and deploys distinct local models with the help of auxiliary global models. However, the clients can be heterogeneous in terms of not only local data distribution, but also their computation and communication resources. The capacity and efficiency of personalized models are restricted by the lowest-resource clients, leading to sub-optimal performance and limited practicality of personalized FL. To overcome these challenges, we propose a novel approach named pFedGate for efficient personalized FL by adaptively and efficiently learning sparse local models. With a lightweight trainable gating layer, pFedGate enables clients to reach their full potential in model capacity by generating different sparse models accounting for both the heterogeneous data distributions and resource constraints. Meanwhile, the computation and communication efficiency are both improved thanks to the adaptability between the model sparsity and clients' resources. Further, we theoretically show that the proposed pFedGate has superior complexity with guaranteed convergence and generalization error. Extensive experiments show that pFedGate achieves superior global accuracy, individual accuracy and efficiency simultaneously over state-of-the-art methods. We also demonstrate that pFedGate performs better than competitors in the novel clients participation and partial clients participation scenarios, and can learn meaningful sparse local models adapted to different data distributions.
FS-Real: Towards Real-World Cross-Device Federated Learning
Mar 23, 2023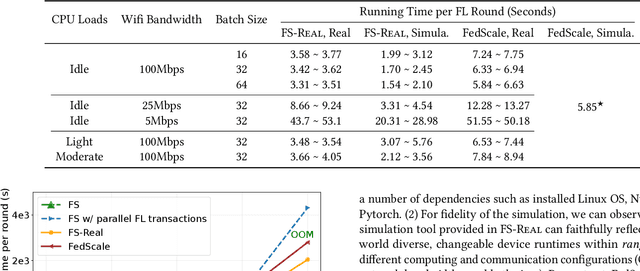
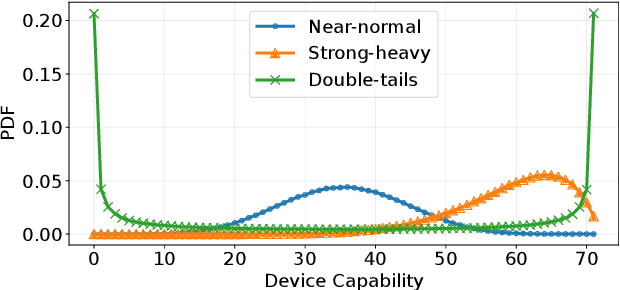

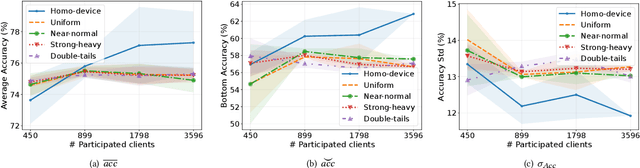
Federated Learning (FL) aims to train high-quality models in collaboration with distributed clients while not uploading their local data, which attracts increasing attention in both academia and industry. However, there is still a considerable gap between the flourishing FL research and real-world scenarios, mainly caused by the characteristics of heterogeneous devices and its scales. Most existing works conduct evaluations with homogeneous devices, which are mismatched with the diversity and variability of heterogeneous devices in real-world scenarios. Moreover, it is challenging to conduct research and development at scale with heterogeneous devices due to limited resources and complex software stacks. These two key factors are important yet underexplored in FL research as they directly impact the FL training dynamics and final performance, making the effectiveness and usability of FL algorithms unclear. To bridge the gap, in this paper, we propose an efficient and scalable prototyping system for real-world cross-device FL, FS-Real. It supports heterogeneous device runtime, contains parallelism and robustness enhanced FL server, and provides implementations and extensibility for advanced FL utility features such as personalization, communication compression and asynchronous aggregation. To demonstrate the usability and efficiency of FS-Real, we conduct extensive experiments with various device distributions, quantify and analyze the effect of the heterogeneous device and various scales, and further provide insights and open discussions about real-world FL scenarios. Our system is released to help to pave the way for further real-world FL research and broad applications involving diverse devices and scales.