 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChengyu Wang
Lifelong Knowledge Editing for LLMs with Retrieval-Augmented Continuous Prompt Learning
May 08, 2024
Model editing aims to correct outdated or erroneous knowledge in large language models (LLMs) without the need for costly retraining. Lifelong model editing is the most challenging task that caters to the continuous editing requirements of LLMs. Prior works primarily focus on single or batch editing; nevertheless, these methods fall short in lifelong editing scenarios due to catastrophic knowledge forgetting and the degradation of model performance. Although retrieval-based methods alleviate these issues, they are impeded by slow and cumbersome processes of integrating the retrieved knowledge into the model. In this work, we introduce RECIPE, a RetriEval-augmented ContInuous Prompt lEarning method, to boost editing efficacy and inference efficiency in lifelong learning. RECIPE first converts knowledge statements into short and informative continuous prompts, prefixed to the LLM's input query embedding, to efficiently refine the response grounded on the knowledge. It further integrates the Knowledge Sentinel (KS) that acts as an intermediary to calculate a dynamic threshold, determining whether the retrieval repository contains relevant knowledge. Our retriever and prompt encoder are jointly trained to achieve editing properties, i.e., reliability, generality, and locality. In our experiments, RECIPE is assessed extensively across multiple LLMs and editing datasets, where it achieves superior editing performance. RECIPE also demonstrates its capability to maintain the overall performance of LLMs alongside showcasing fast editing and inference speed.
R4: Reinforced Retriever-Reorder-Responder for Retrieval-Augmented Large Language Models
May 04, 2024Retrieval-augmented large language models (LLMs) leverage relevant content retrieved by information retrieval systems to generate correct responses, aiming to alleviate the hallucination problem. However, existing retriever-responder methods typically append relevant documents to the prompt of LLMs to perform text generation tasks without considering the interaction of fine-grained structural semantics between the retrieved documents and the LLMs. This issue is particularly important for accurate response generation as LLMs tend to ``lose in the middle'' when dealing with input prompts augmented with lengthy documents. In this work, we propose a new pipeline named ``Reinforced Retriever-Reorder-Responder'' (R$^4$) to learn document orderings for retrieval-augmented LLMs, thereby further enhancing their generation abilities while the large numbers of parameters of LLMs remain frozen. The reordering learning process is divided into two steps according to the quality of the generated responses: document order adjustment and document representation enhancement. Specifically, document order adjustment aims to organize retrieved document orderings into beginning, middle, and end positions based on graph attention learning, which maximizes the reinforced reward of response quality. Document representation enhancement further refines the representations of retrieved documents for responses of poor quality via document-level gradient adversarial learning. Extensive experiments demonstrate that our proposed pipeline achieves better factual question-answering performance on knowledge-intensive tasks compared to strong baselines across various public datasets. The source codes and trained models will be released upon paper acceptance.
DWE+: Dual-Way Matching Enhanced Framework for Multimodal Entity Linking
Apr 07, 2024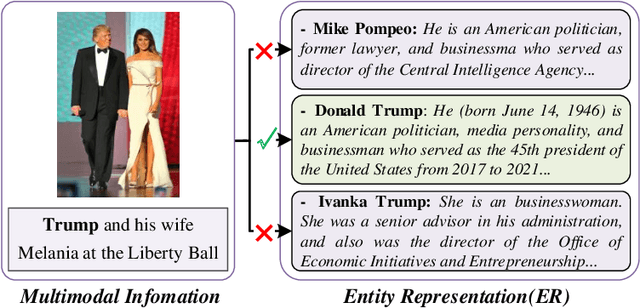
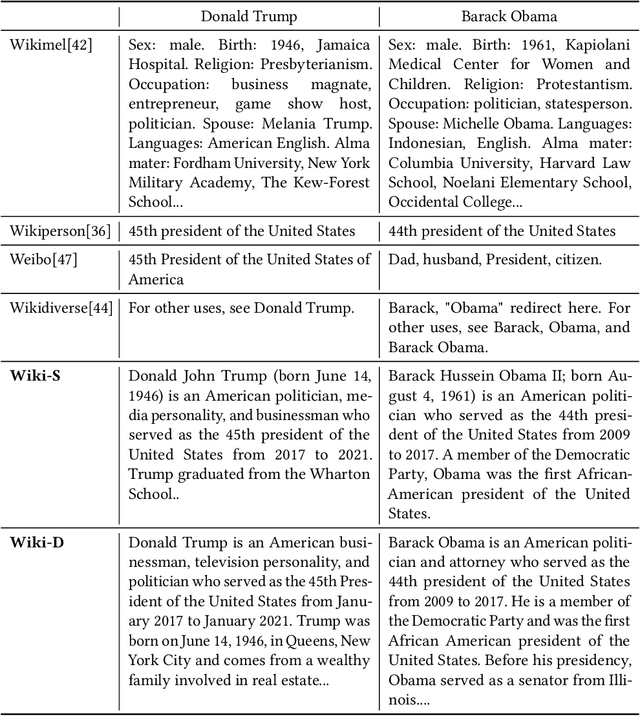
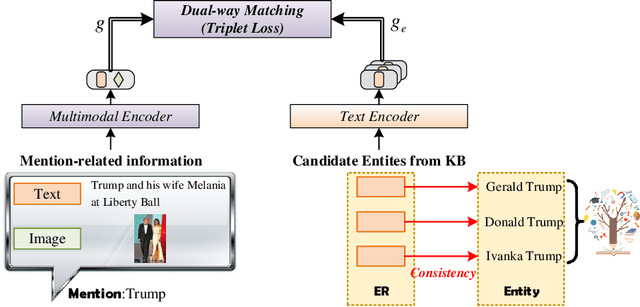
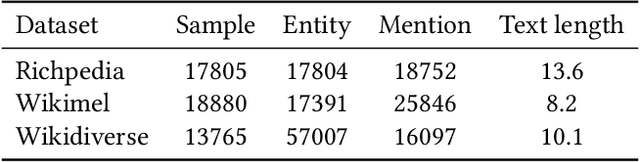
Multimodal entity linking (MEL) aims to utilize multimodal information (usually textual and visual information) to link ambiguous mentions to unambiguous entities in knowledge base. Current methods facing main issues: (1)treating the entire image as input may contain redundant information. (2)the insufficient utilization of entity-related information, such as attributes in images. (3)semantic inconsistency between the entity in knowledge base and its representation. To this end, we propose DWE+ for multimodal entity linking. DWE+ could capture finer semantics and dynamically maintain semantic consistency with entities. This is achieved by three aspects: (a)we introduce a method for extracting fine-grained image features by partitioning the image into multiple local objects. Then, hierarchical contrastive learning is used to further align semantics between coarse-grained information(text and image) and fine-grained (mention and visual objects). (b)we explore ways to extract visual attributes from images to enhance fusion feature such as facial features and identity. (c)we leverage Wikipedia and ChatGPT to capture the entity representation, achieving semantic enrichment from both static and dynamic perspectives, which better reflects the real-world entity semantics. Experiments on Wikimel, Richpedia, and Wikidiverse datasets demonstrate the effectiveness of DWE+ in improving MEL performance. Specifically, we optimize these datasets and achieve state-of-the-art performance on the enhanced datasets. The code and enhanced datasets are released on https://github.com/season1blue/DWET
TRELM: Towards Robust and Efficient Pre-training for Knowledge-Enhanced Language Models
Mar 17, 2024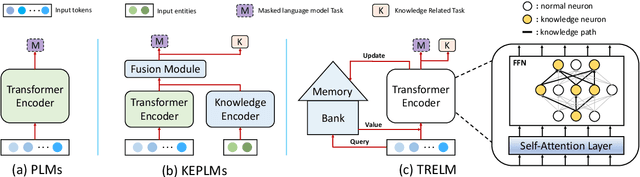

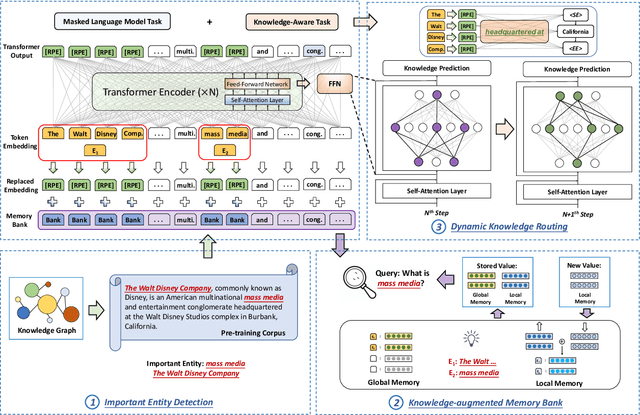
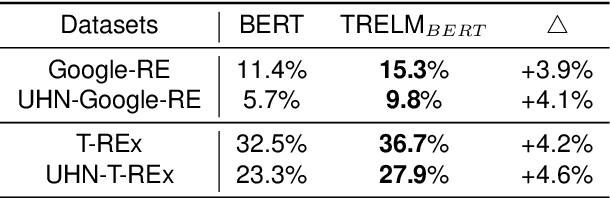
KEPLMs are pre-trained models that utilize external knowledge to enhance language understanding. Previous language models facilitated knowledge acquisition by incorporating knowledge-related pre-training tasks learned from relation triples in knowledge graphs. However, these models do not prioritize learning embeddings for entity-related tokens. Moreover, updating the entire set of parameters in KEPLMs is computationally demanding. This paper introduces TRELM, a Robust and Efficient Pre-training framework for Knowledge-Enhanced Language Models. We observe that entities in text corpora usually follow the long-tail distribution, where the representations of some entities are suboptimally optimized and hinder the pre-training process for KEPLMs. To tackle this, we employ a robust approach to inject knowledge triples and employ a knowledge-augmented memory bank to capture valuable information. Furthermore, updating a small subset of neurons in the feed-forward networks (FFNs) that store factual knowledge is both sufficient and efficient. Specifically, we utilize dynamic knowledge routing to identify knowledge paths in FFNs and selectively update parameters during pre-training. Experimental results show that TRELM reduces pre-training time by at least 50% and outperforms other KEPLMs in knowledge probing tasks and multiple knowledge-aware language understanding tasks.
DiffChat: Learning to Chat with Text-to-Image Synthesis Models for Interactive Image Creation
Mar 08, 2024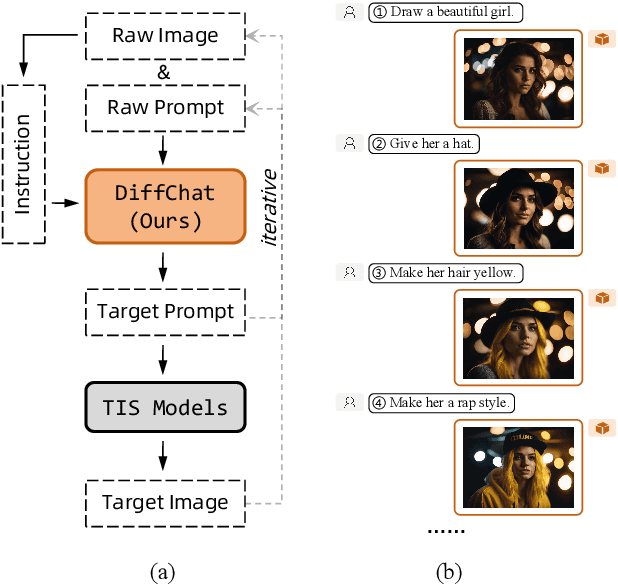

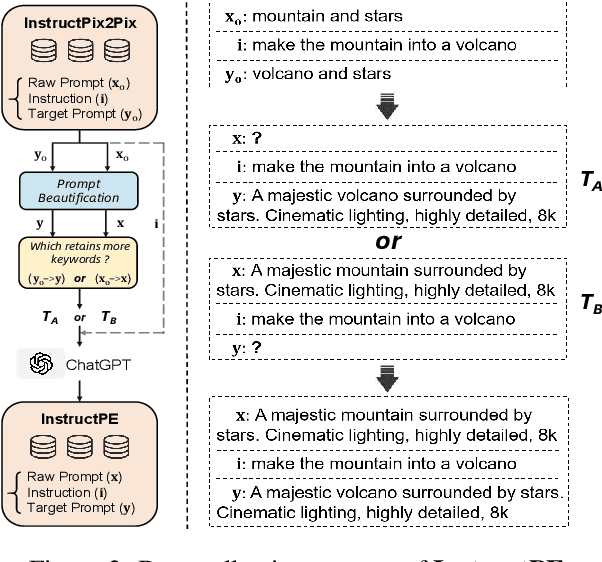
We present DiffChat, a novel method to align Large Language Models (LLMs) to "chat" with prompt-as-input Text-to-Image Synthesis (TIS) models (e.g., Stable Diffusion) for interactive image creation. Given a raw prompt/image and a user-specified instruction, DiffChat can effectively make appropriate modifications and generate the target prompt, which can be leveraged to create the target image of high quality. To achieve this, we first collect an instruction-following prompt engineering dataset named InstructPE for the supervised training of DiffChat. Next, we propose a reinforcement learning framework with the feedback of three core criteria for image creation, i.e., aesthetics, user preference, and content integrity. It involves an action-space dynamic modification technique to obtain more relevant positive samples and harder negative samples during the off-policy sampling. Content integrity is also introduced into the value estimation function for further improvement of produced images. Our method can exhibit superior performance than baseline models and strong competitors based on both automatic and human evaluations, which fully demonstrates its effectiveness.
Towards Understanding Cross and Self-Attention in Stable Diffusion for Text-Guided Image Editing
Mar 06, 2024
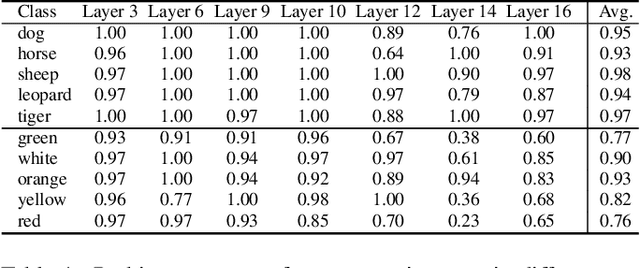
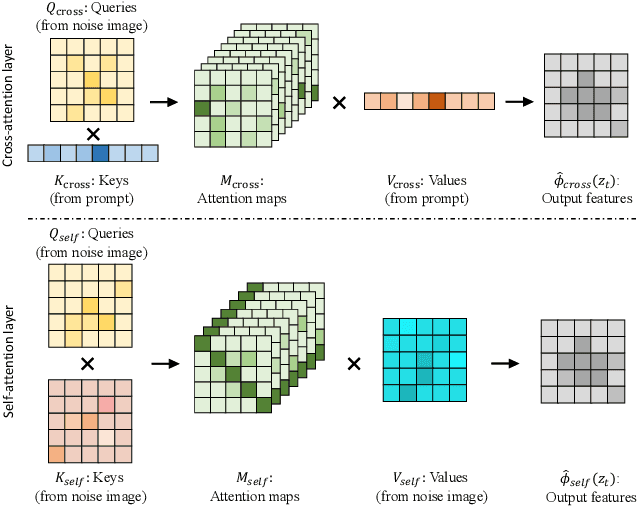
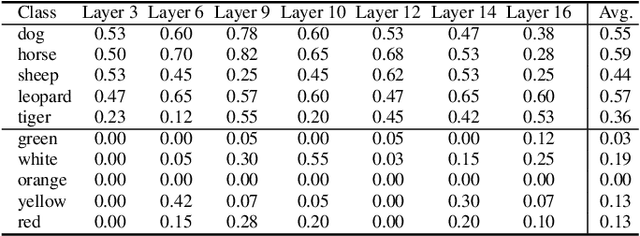
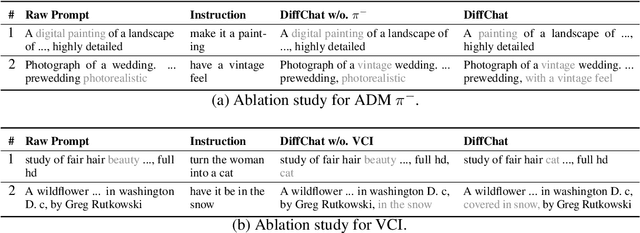
Deep Text-to-Image Synthesis (TIS) models such as Stable Diffusion have recently gained significant popularity for creative Text-to-image generation. Yet, for domain-specific scenarios, tuning-free Text-guided Image Editing (TIE) is of greater importance for application developers, which modify objects or object properties in images by manipulating feature components in attention layers during the generation process. However, little is known about what semantic meanings these attention layers have learned and which parts of the attention maps contribute to the success of image editing. In this paper, we conduct an in-depth probing analysis and demonstrate that cross-attention maps in Stable Diffusion often contain object attribution information that can result in editing failures. In contrast, self-attention maps play a crucial role in preserving the geometric and shape details of the source image during the transformation to the target image. Our analysis offers valuable insights into understanding cross and self-attention maps in diffusion models. Moreover, based on our findings, we simplify popular image editing methods and propose a more straightforward yet more stable and efficient tuning-free procedure that only modifies self-attention maps of the specified attention layers during the denoising process. Experimental results show that our simplified method consistently surpasses the performance of popular approaches on multiple datasets.
Do Large Language Models Understand Logic or Just Mimick Context?
Feb 19, 2024Over the past few years, the abilities of large language models (LLMs) have received extensive attention, which have performed exceptionally well in complicated scenarios such as logical reasoning and symbolic inference. A significant factor contributing to this progress is the benefit of in-context learning and few-shot prompting. However, the reasons behind the success of such models using contextual reasoning have not been fully explored. Do LLMs have understand logical rules to draw inferences, or do they ``guess'' the answers by learning a type of probabilistic mapping through context? This paper investigates the reasoning capabilities of LLMs on two logical reasoning datasets by using counterfactual methods to replace context text and modify logical concepts. Based on our analysis, it is found that LLMs do not truly understand logical rules; rather, in-context learning has simply enhanced the likelihood of these models arriving at the correct answers. If one alters certain words in the context text or changes the concepts of logical terms, the outputs of LLMs can be significantly disrupted, leading to counter-intuitive responses. This work provides critical insights into the limitations of LLMs, underscoring the need for more robust mechanisms to ensure reliable logical reasoning in LLMs.
Diffutoon: High-Resolution Editable Toon Shading via Diffusion Models
Jan 29, 2024Toon shading is a type of non-photorealistic rendering task of animation. Its primary purpose is to render objects with a flat and stylized appearance. As diffusion models have ascended to the forefront of image synthesis methodologies, this paper delves into an innovative form of toon shading based on diffusion models, aiming to directly render photorealistic videos into anime styles. In video stylization, extant methods encounter persistent challenges, notably in maintaining consistency and achieving high visual quality. In this paper, we model the toon shading problem as four subproblems: stylization, consistency enhancement, structure guidance, and colorization. To address the challenges in video stylization, we propose an effective toon shading approach called \textit{Diffutoon}. Diffutoon is capable of rendering remarkably detailed, high-resolution, and extended-duration videos in anime style. It can also edit the content according to prompts via an additional branch. The efficacy of Diffutoon is evaluated through quantitive metrics and human evaluation. Notably, Diffutoon surpasses both open-source and closed-source baseline approaches in our experiments. Our work is accompanied by the release of both the source code and example videos on Github (Project page: https://ecnu-cilab.github.io/DiffutoonProjectPage/).
A Dual-way Enhanced Framework from Text Matching Point of View for Multimodal Entity Linking
Dec 19, 2023Multimodal Entity Linking (MEL) aims at linking ambiguous mentions with multimodal information to entity in Knowledge Graph (KG) such as Wikipedia, which plays a key role in many applications. However, existing methods suffer from shortcomings, including modality impurity such as noise in raw image and ambiguous textual entity representation, which puts obstacles to MEL. We formulate multimodal entity linking as a neural text matching problem where each multimodal information (text and image) is treated as a query, and the model learns the mapping from each query to the relevant entity from candidate entities. This paper introduces a dual-way enhanced (DWE) framework for MEL: (1) our model refines queries with multimodal data and addresses semantic gaps using cross-modal enhancers between text and image information. Besides, DWE innovatively leverages fine-grained image attributes, including facial characteristic and scene feature, to enhance and refine visual features. (2)By using Wikipedia descriptions, DWE enriches entity semantics and obtains more comprehensive textual representation, which reduces between textual representation and the entities in KG. Extensive experiments on three public benchmarks demonstrate that our method achieves state-of-the-art (SOTA) performance, indicating the superiority of our model. The code is released on https://github.com/season1blue/DWE
A Contrastive Compositional Benchmark for Text-to-Image Synthesis: A Study with Unified Text-to-Image Fidelity Metrics
Dec 04, 2023Text-to-image (T2I) synthesis has recently achieved significant advancements. However, challenges remain in the model's compositionality, which is the ability to create new combinations from known components. We introduce Winoground-T2I, a benchmark designed to evaluate the compositionality of T2I models. This benchmark includes 11K complex, high-quality contrastive sentence pairs spanning 20 categories. These contrastive sentence pairs with subtle differences enable fine-grained evaluations of T2I synthesis models. Additionally, to address the inconsistency across different metrics, we propose a strategy that evaluates the reliability of various metrics by using comparative sentence pairs. We use Winoground-T2I with a dual objective: to evaluate the performance of T2I models and the metrics used for their evaluation. Finally, we provide insights into the strengths and weaknesses of these metrics and the capabilities of current T2I models in tackling challenges across a range of complex compositional categories. Our benchmark is publicly available at https://github.com/zhuxiangru/Winoground-T2I .