 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHui Xue
Inline AI: Open-source Deep Learning Inference for Cardiac MR
Apr 03, 2024
Cardiac Magnetic Resonance (CMR) is established as a non-invasive imaging technique for evaluation of heart function, anatomy, and myocardial tissue characterization. Quantitative biomarkers are central for diagnosis and management of heart disease. Deep learning (DL) is playing an ever more important role in extracting these quantitative measures from CMR images. While many researchers have reported promising results in training and evaluating models, model deployment into the imaging workflow is less explored. A new imaging AI framework, the InlineAI, was developed and open-sourced. The main innovation is to enable the model inference inline as a part of imaging computation, instead of as an offline post-processing step and to allow users to plug in their models. We demonstrate the system capability on three applications: long-axis CMR cine landmark detection, short-axis CMR cine analysis of function and anatomy, and quantitative perfusion mapping. The InlineAI allowed models to be deployed into imaging workflow in a streaming manner directly on the scanner. The model was loaded and inference on incoming images were performed while the data acquisition was ongoing, and results were sent back to scanner. Several biomarkers were extracted from model outputs in the demonstrated applications and reported as curves and tabular values. All processes are full automated. the model inference was completed within 6-45s after the end of imaging data acquisition.
Imaging transformer for MRI denoising with the SNR unit training: enabling generalization across field-strengths, imaging contrasts, and anatomy
Apr 03, 2024The ability to recover MRI signal from noise is key to achieve fast acquisition, accurate quantification, and high image quality. Past work has shown convolutional neural networks can be used with abundant and paired low and high-SNR images for training. However, for applications where high-SNR data is difficult to produce at scale (e.g. with aggressive acceleration, high resolution, or low field strength), training a new denoising network using a large quantity of high-SNR images can be infeasible. In this study, we overcome this limitation by improving the generalization of denoising models, enabling application to many settings beyond what appears in the training data. Specifically, we a) develop a training scheme that uses complex MRIs reconstructed in the SNR units (i.e., the images have a fixed noise level, SNR unit training) and augments images with realistic noise based on coil g-factor, and b) develop a novel imaging transformer (imformer) to handle 2D, 2D+T, and 3D MRIs in one model architecture. Through empirical evaluation, we show this combination improves performance compared to CNN models and improves generalization, enabling a denoising model to be used across field-strengths, image contrasts, and anatomy.
Zippo: Zipping Color and Transparency Distributions into a Single Diffusion Model
Mar 19, 2024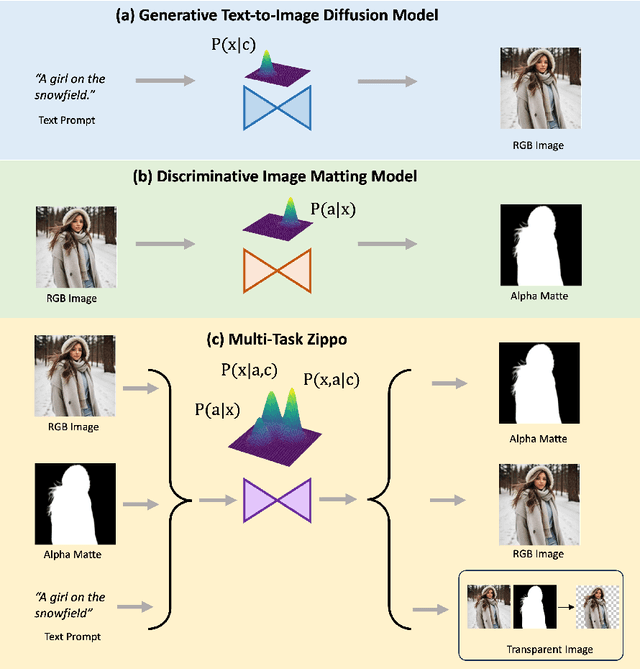

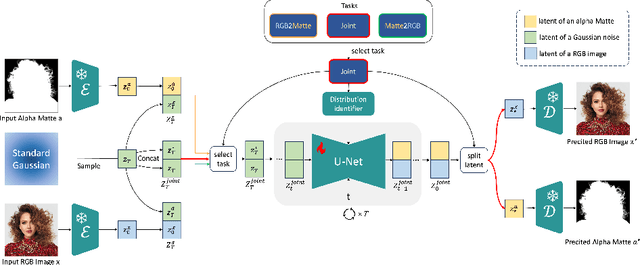
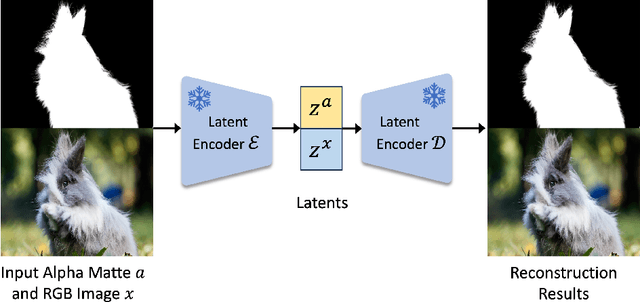
Beyond the superiority of the text-to-image diffusion model in generating high-quality images, recent studies have attempted to uncover its potential for adapting the learned semantic knowledge to visual perception tasks. In this work, instead of translating a generative diffusion model into a visual perception model, we explore to retain the generative ability with the perceptive adaptation. To accomplish this, we present Zippo, a unified framework for zipping the color and transparency distributions into a single diffusion model by expanding the diffusion latent into a joint representation of RGB images and alpha mattes. By alternatively selecting one modality as the condition and then applying the diffusion process to the counterpart modality, Zippo is capable of generating RGB images from alpha mattes and predicting transparency from input images. In addition to single-modality prediction, we propose a modality-aware noise reassignment strategy to further empower Zippo with jointly generating RGB images and its corresponding alpha mattes under the text guidance. Our experiments showcase Zippo's ability of efficient text-conditioned transparent image generation and present plausible results of Matte-to-RGB and RGB-to-Matte translation.
TRELM: Towards Robust and Efficient Pre-training for Knowledge-Enhanced Language Models
Mar 17, 2024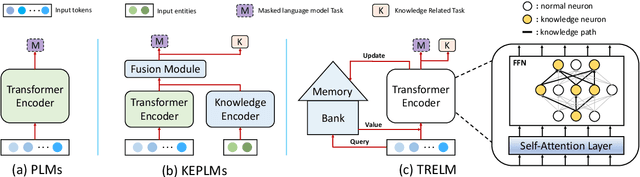

KEPLMs are pre-trained models that utilize external knowledge to enhance language understanding. Previous language models facilitated knowledge acquisition by incorporating knowledge-related pre-training tasks learned from relation triples in knowledge graphs. However, these models do not prioritize learning embeddings for entity-related tokens. Moreover, updating the entire set of parameters in KEPLMs is computationally demanding. This paper introduces TRELM, a Robust and Efficient Pre-training framework for Knowledge-Enhanced Language Models. We observe that entities in text corpora usually follow the long-tail distribution, where the representations of some entities are suboptimally optimized and hinder the pre-training process for KEPLMs. To tackle this, we employ a robust approach to inject knowledge triples and employ a knowledge-augmented memory bank to capture valuable information. Furthermore, updating a small subset of neurons in the feed-forward networks (FFNs) that store factual knowledge is both sufficient and efficient. Specifically, we utilize dynamic knowledge routing to identify knowledge paths in FFNs and selectively update parameters during pre-training. Experimental results show that TRELM reduces pre-training time by at least 50% and outperforms other KEPLMs in knowledge probing tasks and multiple knowledge-aware language understanding tasks.
Spectral Invariant Learning for Dynamic Graphs under Distribution Shifts
Mar 08, 2024
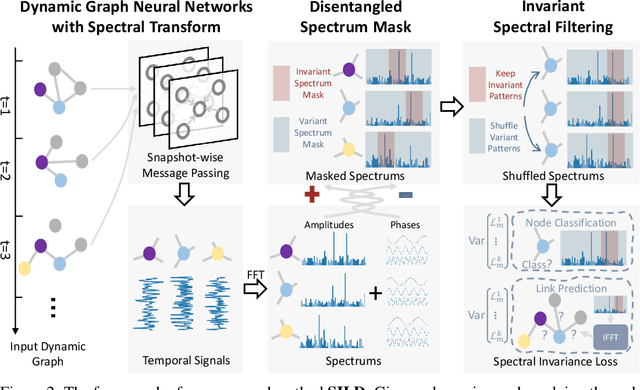
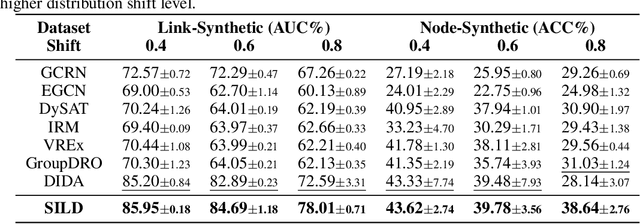
Dynamic graph neural networks (DyGNNs) currently struggle with handling distribution shifts that are inherent in dynamic graphs. Existing work on DyGNNs with out-of-distribution settings only focuses on the time domain, failing to handle cases involving distribution shifts in the spectral domain. In this paper, we discover that there exist cases with distribution shifts unobservable in the time domain while observable in the spectral domain, and propose to study distribution shifts on dynamic graphs in the spectral domain for the first time. However, this investigation poses two key challenges: i) it is non-trivial to capture different graph patterns that are driven by various frequency components entangled in the spectral domain; and ii) it remains unclear how to handle distribution shifts with the discovered spectral patterns. To address these challenges, we propose Spectral Invariant Learning for Dynamic Graphs under Distribution Shifts (SILD), which can handle distribution shifts on dynamic graphs by capturing and utilizing invariant and variant spectral patterns. Specifically, we first design a DyGNN with Fourier transform to obtain the ego-graph trajectory spectrums, allowing the mixed dynamic graph patterns to be transformed into separate frequency components. We then develop a disentangled spectrum mask to filter graph dynamics from various frequency components and discover the invariant and variant spectral patterns. Finally, we propose invariant spectral filtering, which encourages the model to rely on invariant patterns for generalization under distribution shifts. Experimental results on synthetic and real-world dynamic graph datasets demonstrate the superiority of our method for both node classification and link prediction tasks under distribution shifts.
Understanding the Weakness of Large Language Model Agents within a Complex Android Environment
Feb 09, 2024Large language models (LLMs) have empowered intelligent agents to execute intricate tasks within domain-specific software such as browsers and games. However, when applied to general-purpose software systems like operating systems, LLM agents face three primary challenges. Firstly, the action space is vast and dynamic, posing difficulties for LLM agents to maintain an up-to-date understanding and deliver accurate responses. Secondly, real-world tasks often require inter-application cooperation}, demanding farsighted planning from LLM agents. Thirdly, agents need to identify optimal solutions aligning with user constraints, such as security concerns and preferences. These challenges motivate AndroidArena, an environment and benchmark designed to evaluate LLM agents on a modern operating system. To address high-cost of manpower, we design a scalable and semi-automated method to construct the benchmark. In the task evaluation, AndroidArena incorporates accurate and adaptive metrics to address the issue of non-unique solutions. Our findings reveal that even state-of-the-art LLM agents struggle in cross-APP scenarios and adhering to specific constraints. Additionally, we identify a lack of four key capabilities, i.e., understanding, reasoning, exploration, and reflection, as primary reasons for the failure of LLM agents. Furthermore, we provide empirical analysis on the failure of reflection, and improve the success rate by 27% with our proposed exploration strategy. This work is the first to present valuable insights in understanding fine-grained weakness of LLM agents, and offers a path forward for future research in this area. Environment, benchmark, and evaluation code for AndroidArena are released at https://github.com/AndroidArenaAgent/AndroidArena.
Text Image Inpainting via Global Structure-Guided Diffusion Models
Feb 02, 2024Real-world text can be damaged by corrosion issues caused by environmental or human factors, which hinder the preservation of the complete styles of texts, e.g., texture and structure. These corrosion issues, such as graffiti signs and incomplete signatures, bring difficulties in understanding the texts, thereby posing significant challenges to downstream applications, e.g., scene text recognition and signature identification. Notably, current inpainting techniques often fail to adequately address this problem and have difficulties restoring accurate text images along with reasonable and consistent styles. Formulating this as an open problem of text image inpainting, this paper aims to build a benchmark to facilitate its study. In doing so, we establish two specific text inpainting datasets which contain scene text images and handwritten text images, respectively. Each of them includes images revamped by real-life and synthetic datasets, featuring pairs of original images, corrupted images, and other assistant information. On top of the datasets, we further develop a novel neural framework, Global Structure-guided Diffusion Model (GSDM), as a potential solution. Leveraging the global structure of the text as a prior, the proposed GSDM develops an efficient diffusion model to recover clean texts. The efficacy of our approach is demonstrated by thorough empirical study, including a substantial boost in both recognition accuracy and image quality. These findings not only highlight the effectiveness of our method but also underscore its potential to enhance the broader field of text image understanding and processing. Code and datasets are available at: https://github.com/blackprotoss/GSDM.
One-dimensional Adapter to Rule Them All: Concepts, Diffusion Models and Erasing Applications
Dec 26, 2023The prevalent use of commercial and open-source diffusion models (DMs) for text-to-image generation prompts risk mitigation to prevent undesired behaviors. Existing concept erasing methods in academia are all based on full parameter or specification-based fine-tuning, from which we observe the following issues: 1) Generation alternation towards erosion: Parameter drift during target elimination causes alternations and potential deformations across all generations, even eroding other concepts at varying degrees, which is more evident with multi-concept erased; 2) Transfer inability & deployment inefficiency: Previous model-specific erasure impedes the flexible combination of concepts and the training-free transfer towards other models, resulting in linear cost growth as the deployment scenarios increase. To achieve non-invasive, precise, customizable, and transferable elimination, we ground our erasing framework on one-dimensional adapters to erase multiple concepts from most DMs at once across versatile erasing applications. The concept-SemiPermeable structure is injected as a Membrane (SPM) into any DM to learn targeted erasing, and meantime the alteration and erosion phenomenon is effectively mitigated via a novel Latent Anchoring fine-tuning strategy. Once obtained, SPMs can be flexibly combined and plug-and-play for other DMs without specific re-tuning, enabling timely and efficient adaptation to diverse scenarios. During generation, our Facilitated Transport mechanism dynamically regulates the permeability of each SPM to respond to different input prompts, further minimizing the impact on other concepts. Quantitative and qualitative results across ~40 concepts, 7 DMs and 4 erasing applications have demonstrated the superior erasing of SPM. Our code and pre-tuned SPMs will be available on the project page https://lyumengyao.github.io/projects/spm.
PEAN: A Diffusion-based Prior-Enhanced Attention Network for Scene Text Image Super-Resolution
Nov 29, 2023Scene text image super-resolution (STISR) aims at simultaneously increasing the resolution and readability of low-resolution scene text images, thus boosting the performance of the downstream recognition task. Two factors in scene text images, semantic information and visual structure, affect the recognition performance significantly. To mitigate the effects from these factors, this paper proposes a Prior-Enhanced Attention Network (PEAN). Specifically, a diffusion-based module is developed to enhance the text prior, hence offering better guidance for the SR network to generate SR images with higher semantic accuracy. Meanwhile, the proposed PEAN leverages an attention-based modulation module to understand scene text images by neatly perceiving the local and global dependence of images, despite the shape of the text. A multi-task learning paradigm is employed to optimize the network, enabling the model to generate legible SR images. As a result, PEAN establishes new SOTA results on the TextZoom benchmark. Experiments are also conducted to analyze the importance of the enhanced text prior as a means of improving the performance of the SR network. Code will be made available at https://github.com/jdfxzzy/PEAN.