 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongtao Huang
TRELM: Towards Robust and Efficient Pre-training for Knowledge-Enhanced Language Models
Mar 17, 2024
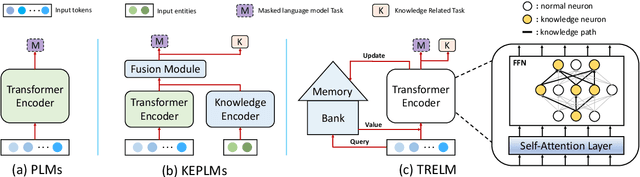

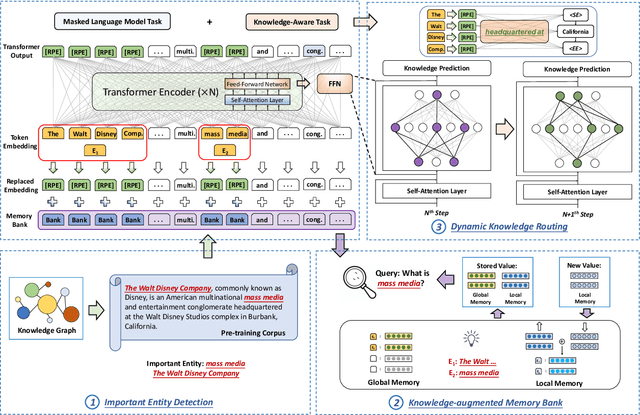
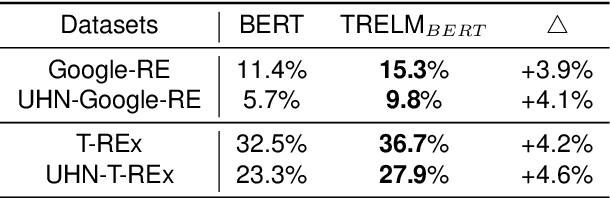
KEPLMs are pre-trained models that utilize external knowledge to enhance language understanding. Previous language models facilitated knowledge acquisition by incorporating knowledge-related pre-training tasks learned from relation triples in knowledge graphs. However, these models do not prioritize learning embeddings for entity-related tokens. Moreover, updating the entire set of parameters in KEPLMs is computationally demanding. This paper introduces TRELM, a Robust and Efficient Pre-training framework for Knowledge-Enhanced Language Models. We observe that entities in text corpora usually follow the long-tail distribution, where the representations of some entities are suboptimally optimized and hinder the pre-training process for KEPLMs. To tackle this, we employ a robust approach to inject knowledge triples and employ a knowledge-augmented memory bank to capture valuable information. Furthermore, updating a small subset of neurons in the feed-forward networks (FFNs) that store factual knowledge is both sufficient and efficient. Specifically, we utilize dynamic knowledge routing to identify knowledge paths in FFNs and selectively update parameters during pre-training. Experimental results show that TRELM reduces pre-training time by at least 50% and outperforms other KEPLMs in knowledge probing tasks and multiple knowledge-aware language understanding tasks.
General Phrase Debiaser: Debiasing Masked Language Models at a Multi-Token Level
Nov 23, 2023The social biases and unwelcome stereotypes revealed by pretrained language models are becoming obstacles to their application. Compared to numerous debiasing methods targeting word level, there has been relatively less attention on biases present at phrase level, limiting the performance of debiasing in discipline domains. In this paper, we propose an automatic multi-token debiasing pipeline called \textbf{General Phrase Debiaser}, which is capable of mitigating phrase-level biases in masked language models. Specifically, our method consists of a \textit{phrase filter stage} that generates stereotypical phrases from Wikipedia pages as well as a \textit{model debias stage} that can debias models at the multi-token level to tackle bias challenges on phrases. The latter searches for prompts that trigger model's bias, and then uses them for debiasing. State-of-the-art results on standard datasets and metrics show that our approach can significantly reduce gender biases on both career and multiple disciplines, across models with varying parameter sizes.
From Adversarial Arms Race to Model-centric Evaluation: Motivating a Unified Automatic Robustness Evaluation Framework
May 29, 2023


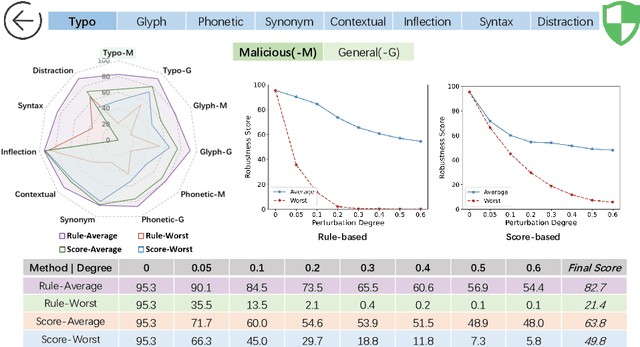
Textual adversarial attacks can discover models' weaknesses by adding semantic-preserved but misleading perturbations to the inputs. The long-lasting adversarial attack-and-defense arms race in Natural Language Processing (NLP) is algorithm-centric, providing valuable techniques for automatic robustness evaluation. However, the existing practice of robustness evaluation may exhibit issues of incomprehensive evaluation, impractical evaluation protocol, and invalid adversarial samples. In this paper, we aim to set up a unified automatic robustness evaluation framework, shifting towards model-centric evaluation to further exploit the advantages of adversarial attacks. To address the above challenges, we first determine robustness evaluation dimensions based on model capabilities and specify the reasonable algorithm to generate adversarial samples for each dimension. Then we establish the evaluation protocol, including evaluation settings and metrics, under realistic demands. Finally, we use the perturbation degree of adversarial samples to control the sample validity. We implement a toolkit RobTest that realizes our automatic robustness evaluation framework. In our experiments, we conduct a robustness evaluation of RoBERTa models to demonstrate the effectiveness of our evaluation framework, and further show the rationality of each component in the framework. The code will be made public at \url{https://github.com/thunlp/RobTest}.
Large Language Models Can be Lazy Learners: Analyze Shortcuts in In-Context Learning
May 26, 2023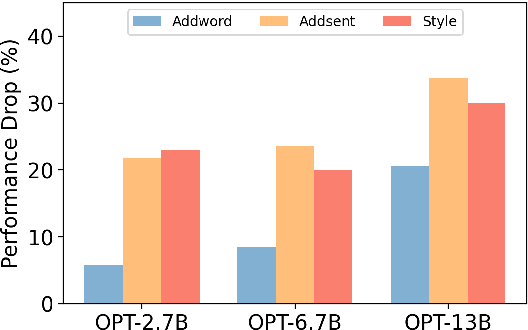


Large language models (LLMs) have recently shown great potential for in-context learning, where LLMs learn a new task simply by conditioning on a few input-label pairs (prompts). Despite their potential, our understanding of the factors influencing end-task performance and the robustness of in-context learning remains limited. This paper aims to bridge this knowledge gap by investigating the reliance of LLMs on shortcuts or spurious correlations within prompts. Through comprehensive experiments on classification and extraction tasks, we reveal that LLMs are "lazy learners" that tend to exploit shortcuts in prompts for downstream tasks. Additionally, we uncover a surprising finding that larger models are more likely to utilize shortcuts in prompts during inference. Our findings provide a new perspective on evaluating robustness in in-context learning and pose new challenges for detecting and mitigating the use of shortcuts in prompts.
Decoder Tuning: Efficient Language Understanding as Decoding
Dec 16, 2022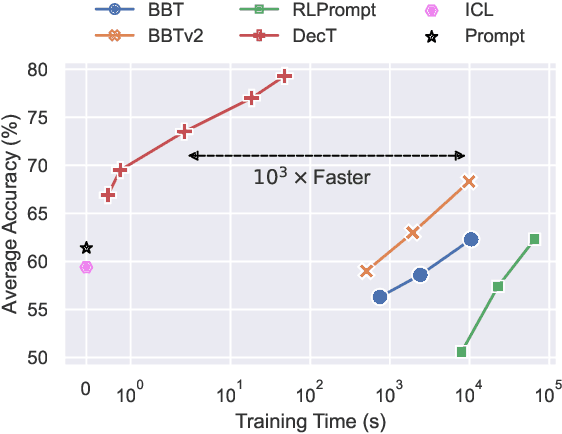
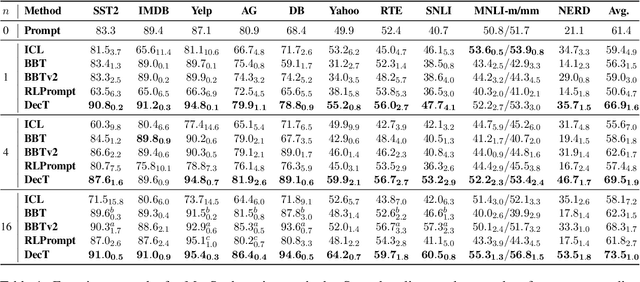
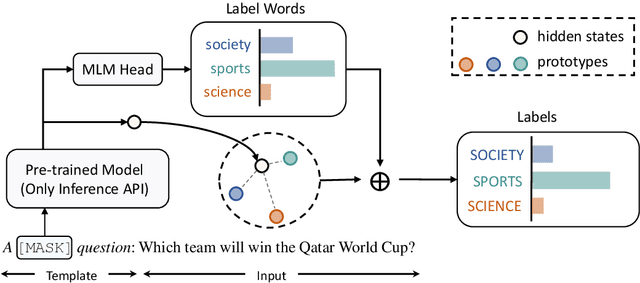
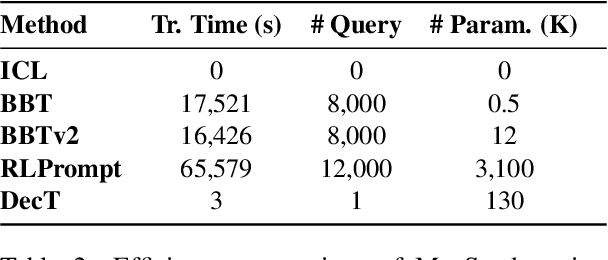
With the evergrowing sizes of pre-trained models (PTMs), it has been an emerging practice to only provide the inference APIs for users, namely model-as-a-service (MaaS) setting. To adapt PTMs with model parameters frozen, most current approaches focus on the input side, seeking for powerful prompts to stimulate models for correct answers. However, we argue that input-side adaptation could be arduous due to the lack of gradient signals and they usually require thousands of API queries, resulting in high computation and time costs. In light of this, we present Decoder Tuning (DecT), which in contrast optimizes task-specific decoder networks on the output side. Specifically, DecT first extracts prompt-stimulated output scores for initial predictions. On top of that, we train an additional decoder network on the output representations to incorporate posterior data knowledge. By gradient-based optimization, DecT can be trained within several seconds and requires only one PTM query per sample. Empirically, we conduct extensive natural language understanding experiments and show that DecT significantly outperforms state-of-the-art algorithms with a $10^3\times$ speed-up.
Why Should Adversarial Perturbations be Imperceptible? Rethink the Research Paradigm in Adversarial NLP
Oct 19, 2022


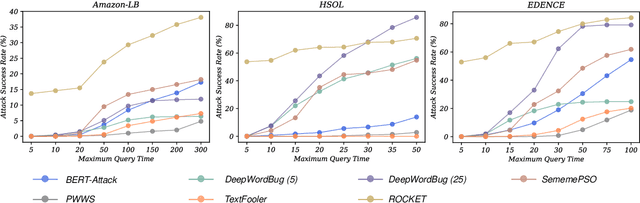
Textual adversarial samples play important roles in multiple subfields of NLP research, including security, evaluation, explainability, and data augmentation. However, most work mixes all these roles, obscuring the problem definitions and research goals of the security role that aims to reveal the practical concerns of NLP models. In this paper, we rethink the research paradigm of textual adversarial samples in security scenarios. We discuss the deficiencies in previous work and propose our suggestions that the research on the Security-oriented adversarial NLP (SoadNLP) should: (1) evaluate their methods on security tasks to demonstrate the real-world concerns; (2) consider real-world attackers' goals, instead of developing impractical methods. To this end, we first collect, process, and release a security datasets collection Advbench. Then, we reformalize the task and adjust the emphasis on different goals in SoadNLP. Next, we propose a simple method based on heuristic rules that can easily fulfill the actual adversarial goals to simulate real-world attack methods. We conduct experiments on both the attack and the defense sides on Advbench. Experimental results show that our method has higher practical value, indicating that the research paradigm in SoadNLP may start from our new benchmark. All the code and data of Advbench can be obtained at \url{https://github.com/thunlp/Advbench}.
Supervised Prototypical Contrastive Learning for Emotion Recognition in Conversation
Oct 19, 2022
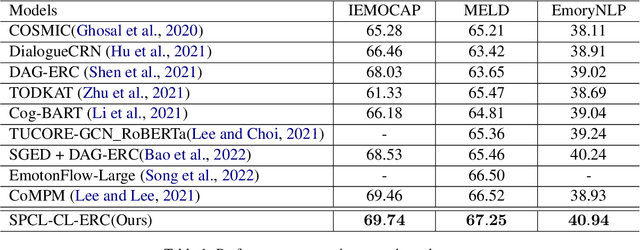
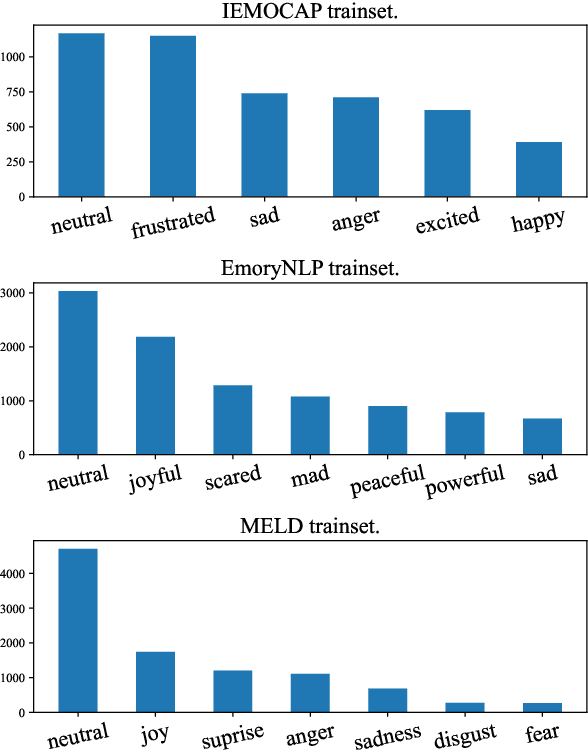
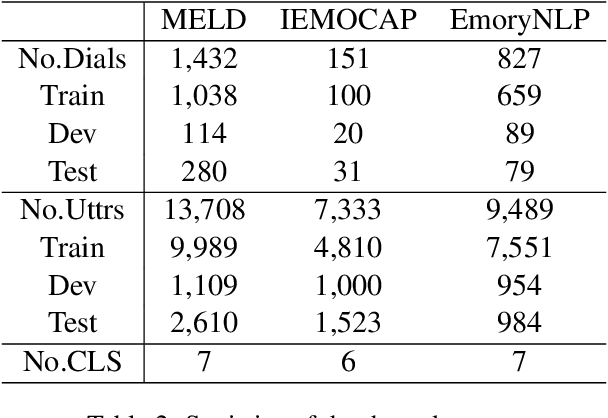
Capturing emotions within a conversation plays an essential role in modern dialogue systems. However, the weak correlation between emotions and semantics brings many challenges to emotion recognition in conversation (ERC). Even semantically similar utterances, the emotion may vary drastically depending on contexts or speakers. In this paper, we propose a Supervised Prototypical Contrastive Learning (SPCL) loss for the ERC task. Leveraging the Prototypical Network, the SPCL targets at solving the imbalanced classification problem through contrastive learning and does not require a large batch size. Meanwhile, we design a difficulty measure function based on the distance between classes and introduce curriculum learning to alleviate the impact of extreme samples. We achieve state-of-the-art results on three widely used benchmarks. Further, we conduct analytical experiments to demonstrate the effectiveness of our proposed SPCL and curriculum learning strategy. We release the code at https://github.com/caskcsg/SPCL.
RMGN: A Regional Mask Guided Network for Parser-free Virtual Try-on
Apr 24, 2022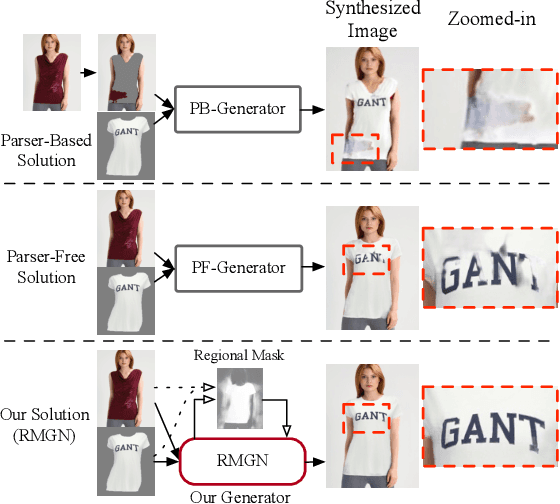
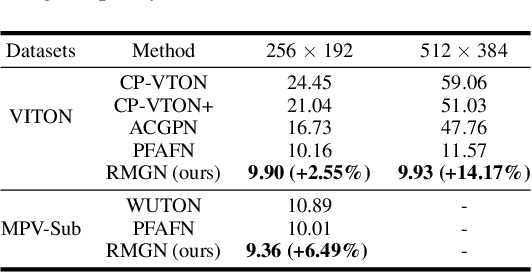
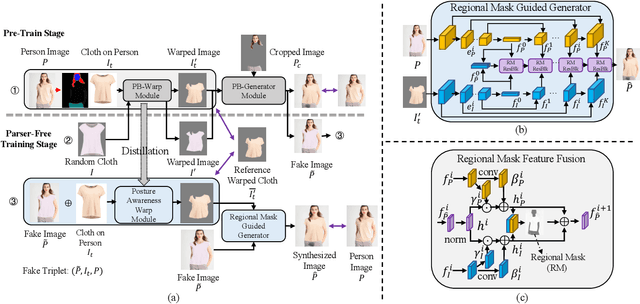
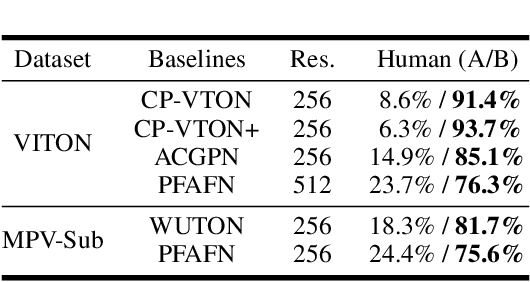
Virtual try-on(VTON) aims at fitting target clothes to reference person images, which is widely adopted in e-commerce.Existing VTON approaches can be narrowly categorized into Parser-Based(PB) and Parser-Free(PF) by whether relying on the parser information to mask the persons' clothes and synthesize try-on images. Although abandoning parser information has improved the applicability of PF methods, the ability of detail synthesizing has also been sacrificed. As a result, the distraction from original cloth may persistin synthesized images, especially in complicated postures and high resolution applications. To address the aforementioned issue, we propose a novel PF method named Regional Mask Guided Network(RMGN). More specifically, a regional mask is proposed to explicitly fuse the features of target clothes and reference persons so that the persisted distraction can be eliminated. A posture awareness loss and a multi-level feature extractor are further proposed to handle the complicated postures and synthesize high resolution images. Extensive experiments demonstrate that our proposed RMGN outperforms both state-of-the-art PB and PF methods.Ablation studies further verify the effectiveness ofmodules in RMGN.
Prototypical Verbalizer for Prompt-based Few-shot Tuning
Mar 18, 2022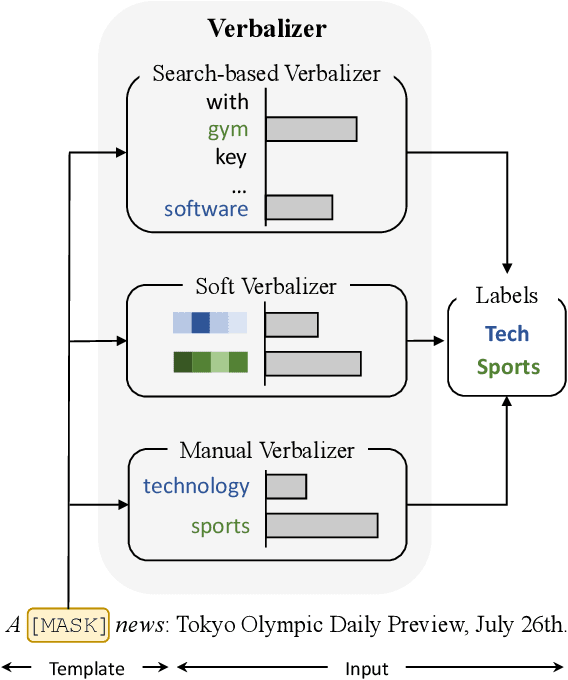
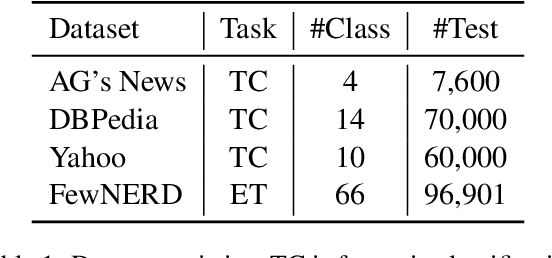
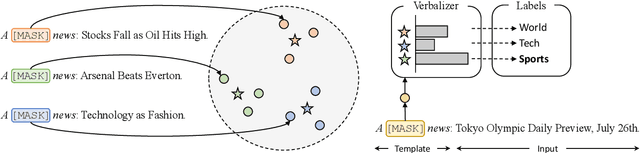
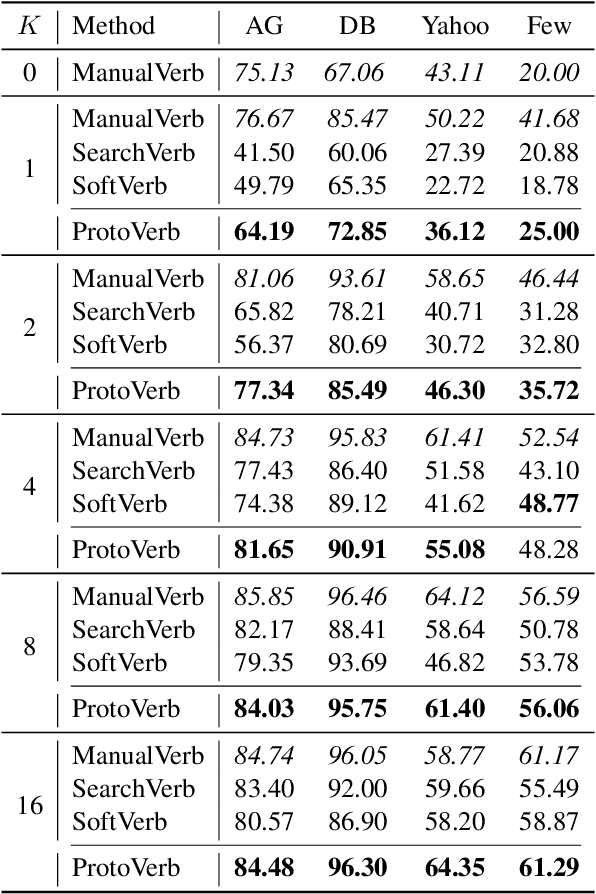
Prompt-based tuning for pre-trained language models (PLMs) has shown its effectiveness in few-shot learning. Typically, prompt-based tuning wraps the input text into a cloze question. To make predictions, the model maps the output words to labels via a verbalizer, which is either manually designed or automatically built. However, manual verbalizers heavily depend on domain-specific prior knowledge and human efforts, while finding appropriate label words automatically still remains challenging.In this work, we propose the prototypical verbalizer (ProtoVerb) which is built directly from training data. Specifically, ProtoVerb learns prototype vectors as verbalizers by contrastive learning. In this way, the prototypes summarize training instances and are able to enclose rich class-level semantics. We conduct experiments on both topic classification and entity typing tasks, and the results demonstrate that ProtoVerb significantly outperforms current automatic verbalizers, especially when training data is extremely scarce. More surprisingly, ProtoVerb consistently boosts prompt-based tuning even on untuned PLMs, indicating an elegant non-tuning way to utilize PLMs. Our codes are avaliable at https://github.com/thunlp/OpenPrompt.
Automated Strabismus Detection based on Deep neural networks for Telemedicine Applications
Sep 30, 2018
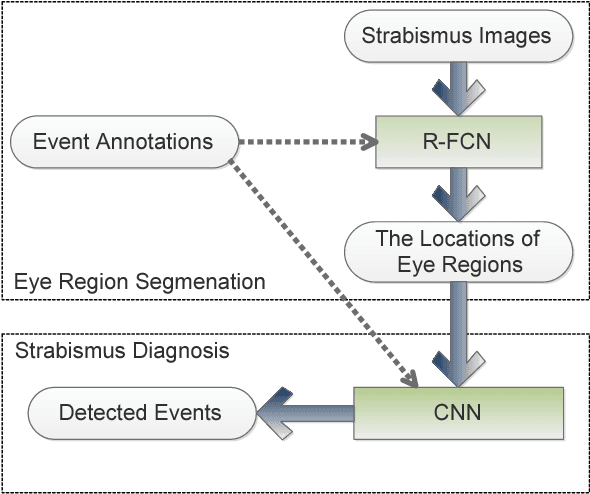
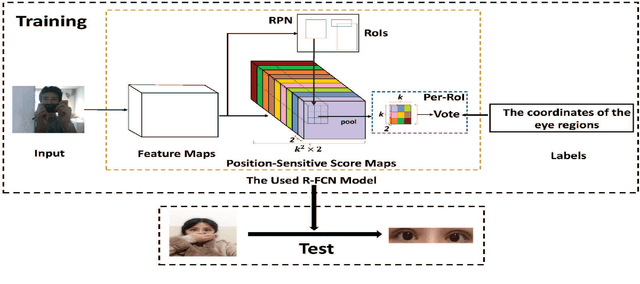

Strabismus is one of the most influential ophthalmologic diseases in humans life. Timely detection of strabismus contributes to its prognosis and treatment. Telemedicine, which has great potential to alleviate the growing demand of the diagnosis of ophthalmologic diseases, is an effective method to achieve timely strabismus detection. In addition, deep neural networks are beneficial to achieve fully automated strabismus detection. In this paper, a tele strabismus dataset is founded by the ophthalmologists. Then a new algorithm based on deep neural networks is proposed to achieve automated strabismus detection on the founded tele strabismus dataset. The proposed algorithm consists of two stages. In the first stage, R-FCN is applied to perform eye region segmentation. In the second stage, a deep convolutional neural networks is built and trained in order to classify the segmented eye regions as strabismus or normal. The experimental results on the founded tele strabismus dataset shows that the proposed method can have a good performance on automated strabismus detection for telemedicine application. Code is made publicly available at: https://github.com/jieWeiLu/Strabismus-Detection-for-Telemedicine-Application