 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongcheng Gao
Universal Prompt Optimizer for Safe Text-to-Image Generation
Feb 16, 2024
Text-to-Image (T2I) models have shown great performance in generating images based on textual prompts. However, these models are vulnerable to unsafe input to generate unsafe content like sexual, harassment and illegal-activity images. Existing studies based on image checker, model fine-tuning and embedding blocking are impractical in real-world applications. Hence, \textit{we propose the first universal prompt optimizer for safe T2I generation in black-box scenario}. We first construct a dataset consisting of toxic-clean prompt pairs by GPT-3.5 Turbo. To guide the optimizer to have the ability of converting toxic prompt to clean prompt while preserving semantic information, we design a novel reward function measuring toxicity and text alignment of generated images and train the optimizer through Proximal Policy Optimization. Experiments show that our approach can effectively reduce the likelihood of various T2I models in generating inappropriate images, with no significant impact on text alignment. It is also flexible to be combined with methods to achieve better performance.
Generative Pretraining in Multimodality
Jul 11, 2023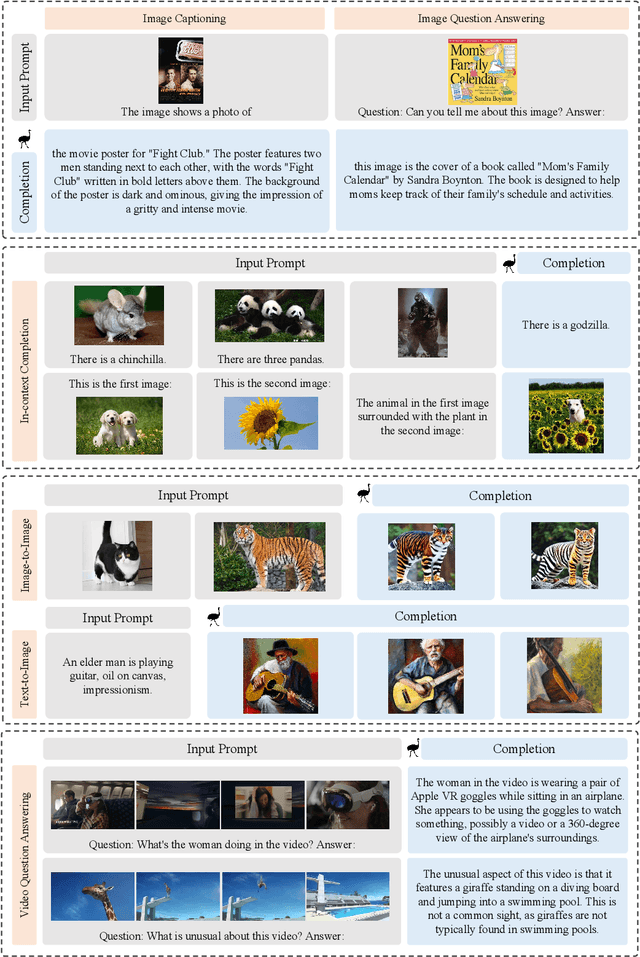
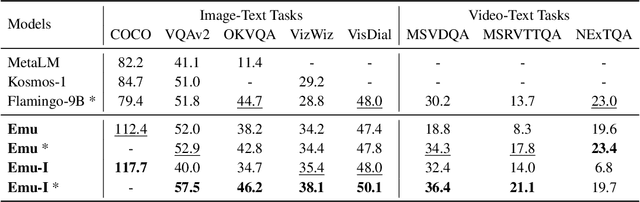
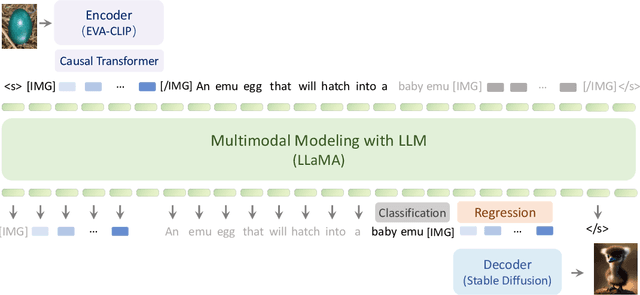
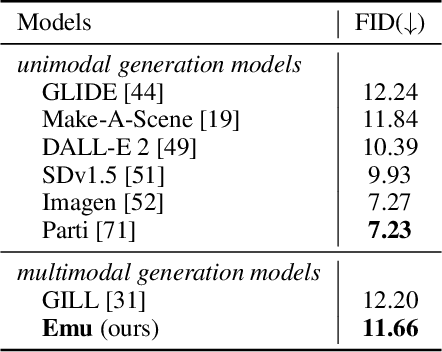
We present Emu, a Transformer-based multimodal foundation model, which can seamlessly generate images and texts in multimodal context. This omnivore model can take in any single-modality or multimodal data input indiscriminately (e.g., interleaved image, text and video) through a one-model-for-all autoregressive training process. First, visual signals are encoded into embeddings, and together with text tokens form an interleaved input sequence. Emu is then end-to-end trained with a unified objective of classifying the next text token or regressing the next visual embedding in the multimodal sequence. This versatile multimodality empowers the exploration of diverse pretraining data sources at scale, such as videos with interleaved frames and text, webpages with interleaved images and text, as well as web-scale image-text pairs and video-text pairs. Emu can serve as a generalist multimodal interface for both image-to-text and text-to-image tasks, and supports in-context image and text generation. Across a broad range of zero-shot/few-shot tasks including image captioning, visual question answering, video question answering and text-to-image generation, Emu demonstrates superb performance compared to state-of-the-art large multimodal models. Extended capabilities such as multimodal assistants via instruction tuning are also demonstrated with impressive performance.
Evaluating the Robustness of Text-to-image Diffusion Models against Real-world Attacks
Jun 16, 2023

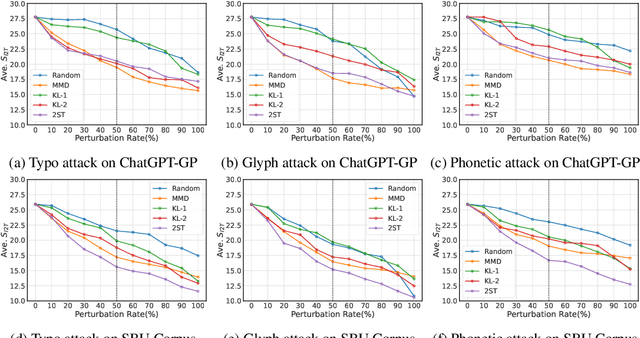
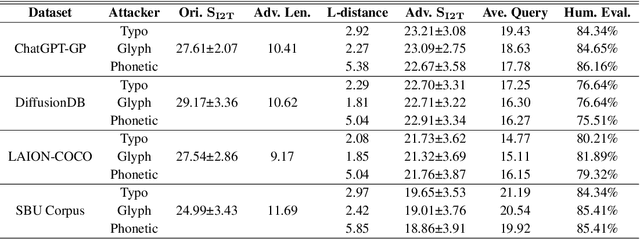
Text-to-image (T2I) diffusion models (DMs) have shown promise in generating high-quality images from textual descriptions. The real-world applications of these models require particular attention to their safety and fidelity, but this has not been sufficiently explored. One fundamental question is whether existing T2I DMs are robust against variations over input texts. To answer it, this work provides the first robustness evaluation of T2I DMs against real-world attacks. Unlike prior studies that focus on malicious attacks involving apocryphal alterations to the input texts, we consider an attack space spanned by realistic errors (e.g., typo, glyph, phonetic) that humans can make, to ensure semantic consistency. Given the inherent randomness of the generation process, we develop novel distribution-based attack objectives to mislead T2I DMs. We perform attacks in a black-box manner without any knowledge of the model. Extensive experiments demonstrate the effectiveness of our method for attacking popular T2I DMs and simultaneously reveal their non-trivial robustness issues. Moreover, we provide an in-depth analysis of our method to show that it is not designed to attack the text encoder in T2I DMs solely.
Revisiting Out-of-distribution Robustness in NLP: Benchmark, Analysis, and LLMs Evaluations
Jun 07, 2023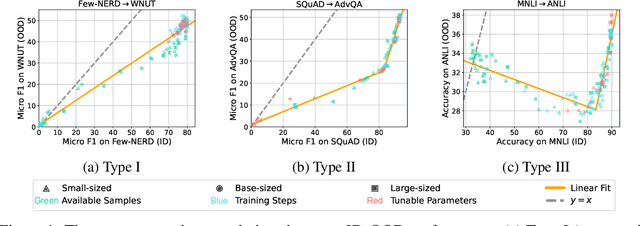
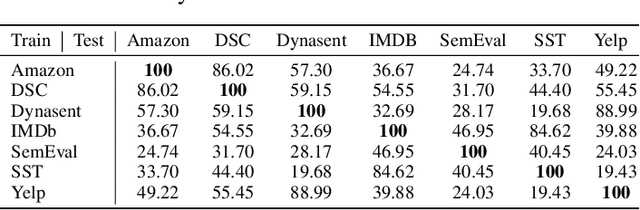
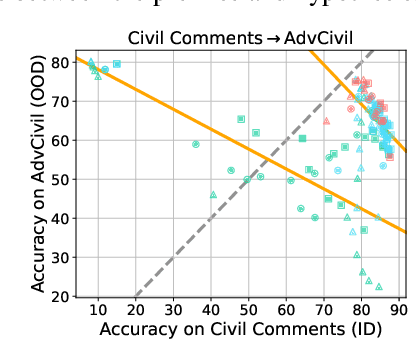
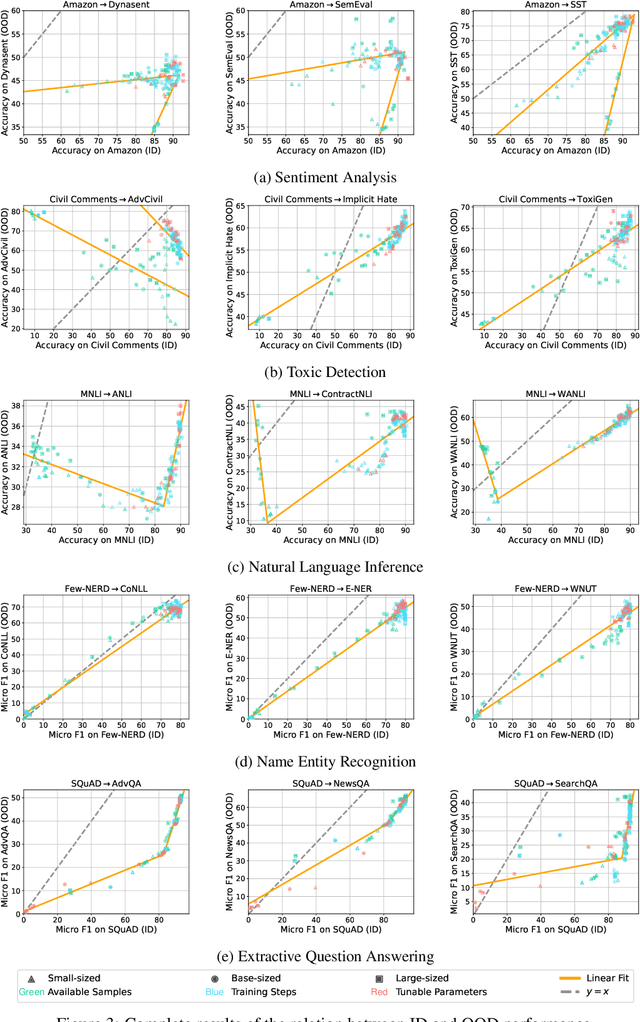
This paper reexamines the research on out-of-distribution (OOD) robustness in the field of NLP. We find that the distribution shift settings in previous studies commonly lack adequate challenges, hindering the accurate evaluation of OOD robustness. To address these issues, we propose a benchmark construction protocol that ensures clear differentiation and challenging distribution shifts. Then we introduce BOSS, a Benchmark suite for Out-of-distribution robustneSS evaluation covering 5 tasks and 20 datasets. Based on BOSS, we conduct a series of experiments on pre-trained language models for analysis and evaluation of OOD robustness. First, for vanilla fine-tuning, we examine the relationship between in-distribution (ID) and OOD performance. We identify three typical types that unveil the inner learning mechanism, which could potentially facilitate the forecasting of OOD robustness, correlating with the advancements on ID datasets. Then, we evaluate 5 classic methods on BOSS and find that, despite exhibiting some effectiveness in specific cases, they do not offer significant improvement compared to vanilla fine-tuning. Further, we evaluate 5 LLMs with various adaptation paradigms and find that when sufficient ID data is available, fine-tuning domain-specific models outperform LLMs on ID examples significantly. However, in the case of OOD instances, prioritizing LLMs with in-context learning yields better results. We identify that both fine-tuned small models and LLMs face challenges in effectively addressing downstream tasks. The code is public at \url{https://github.com/lifan-yuan/OOD_NLP}.
From Adversarial Arms Race to Model-centric Evaluation: Motivating a Unified Automatic Robustness Evaluation Framework
May 29, 2023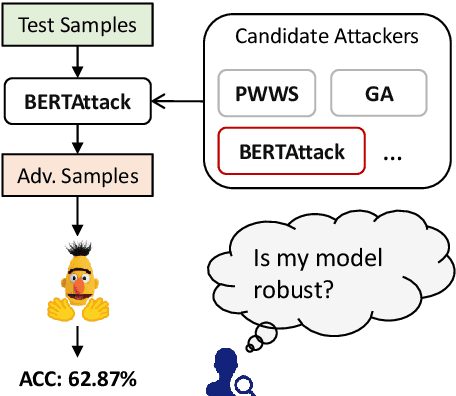


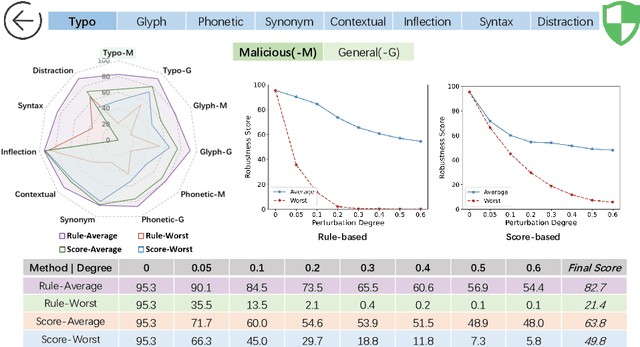
Textual adversarial attacks can discover models' weaknesses by adding semantic-preserved but misleading perturbations to the inputs. The long-lasting adversarial attack-and-defense arms race in Natural Language Processing (NLP) is algorithm-centric, providing valuable techniques for automatic robustness evaluation. However, the existing practice of robustness evaluation may exhibit issues of incomprehensive evaluation, impractical evaluation protocol, and invalid adversarial samples. In this paper, we aim to set up a unified automatic robustness evaluation framework, shifting towards model-centric evaluation to further exploit the advantages of adversarial attacks. To address the above challenges, we first determine robustness evaluation dimensions based on model capabilities and specify the reasonable algorithm to generate adversarial samples for each dimension. Then we establish the evaluation protocol, including evaluation settings and metrics, under realistic demands. Finally, we use the perturbation degree of adversarial samples to control the sample validity. We implement a toolkit RobTest that realizes our automatic robustness evaluation framework. In our experiments, we conduct a robustness evaluation of RoBERTa models to demonstrate the effectiveness of our evaluation framework, and further show the rationality of each component in the framework. The code will be made public at \url{https://github.com/thunlp/RobTest}.
Efficient Detection of LLM-generated Texts with a Bayesian Surrogate Model
May 26, 2023



The detection of machine-generated text, especially from large language models (LLMs), is crucial in preventing serious social problems resulting from their misuse. Some methods train dedicated detectors on specific datasets but fall short in generalizing to unseen test data, while other zero-shot ones often yield suboptimal performance. Although the recent DetectGPT has shown promising detection performance, it suffers from significant inefficiency issues, as detecting a single candidate requires scoring hundreds of its perturbations with the source LLM. This paper aims to bridge this gap. Technically, we propose to incorporate a Bayesian surrogate model, which allows us to select typical samples based on Bayesian uncertainty and interpolate scores from typical samples to other ones, to improve query efficiency. Our empirical results demonstrate that our method significantly outperforms existing approaches under a low query budget. Notably, our method achieves similar performance with up to 2 times fewer queries than DetectGPT and 3.7% higher AUROC at a query number of 5.
Why Should Adversarial Perturbations be Imperceptible? Rethink the Research Paradigm in Adversarial NLP
Oct 19, 2022


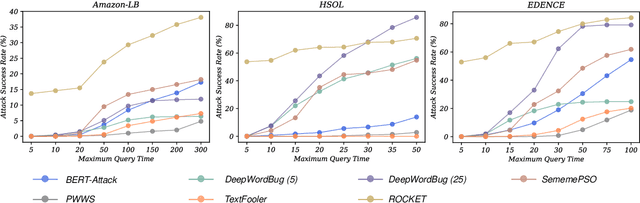
Textual adversarial samples play important roles in multiple subfields of NLP research, including security, evaluation, explainability, and data augmentation. However, most work mixes all these roles, obscuring the problem definitions and research goals of the security role that aims to reveal the practical concerns of NLP models. In this paper, we rethink the research paradigm of textual adversarial samples in security scenarios. We discuss the deficiencies in previous work and propose our suggestions that the research on the Security-oriented adversarial NLP (SoadNLP) should: (1) evaluate their methods on security tasks to demonstrate the real-world concerns; (2) consider real-world attackers' goals, instead of developing impractical methods. To this end, we first collect, process, and release a security datasets collection Advbench. Then, we reformalize the task and adjust the emphasis on different goals in SoadNLP. Next, we propose a simple method based on heuristic rules that can easily fulfill the actual adversarial goals to simulate real-world attack methods. We conduct experiments on both the attack and the defense sides on Advbench. Experimental results show that our method has higher practical value, indicating that the research paradigm in SoadNLP may start from our new benchmark. All the code and data of Advbench can be obtained at \url{https://github.com/thunlp/Advbench}.
Exploring the Universal Vulnerability of Prompt-based Learning Paradigm
Apr 11, 2022



Prompt-based learning paradigm bridges the gap between pre-training and fine-tuning, and works effectively under the few-shot setting. However, we find that this learning paradigm inherits the vulnerability from the pre-training stage, where model predictions can be misled by inserting certain triggers into the text. In this paper, we explore this universal vulnerability by either injecting backdoor triggers or searching for adversarial triggers on pre-trained language models using only plain text. In both scenarios, we demonstrate that our triggers can totally control or severely decrease the performance of prompt-based models fine-tuned on arbitrary downstream tasks, reflecting the universal vulnerability of the prompt-based learning paradigm. Further experiments show that adversarial triggers have good transferability among language models. We also find conventional fine-tuning models are not vulnerable to adversarial triggers constructed from pre-trained language models. We conclude by proposing a potential solution to mitigate our attack methods. Code and data are publicly available at https://github.com/leix28/prompt-universal-vulnerability