 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWentao Li
Panoptic Perception: A Novel Task and Fine-grained Dataset for Universal Remote Sensing Image Interpretation
Apr 06, 2024
Current remote-sensing interpretation models often focus on a single task such as detection, segmentation, or caption. However, the task-specific designed models are unattainable to achieve the comprehensive multi-level interpretation of images. The field also lacks support for multi-task joint interpretation datasets. In this paper, we propose Panoptic Perception, a novel task and a new fine-grained dataset (FineGrip) to achieve a more thorough and universal interpretation for RSIs. The new task, 1) integrates pixel-level, instance-level, and image-level information for universal image perception, 2) captures image information from coarse to fine granularity, achieving deeper scene understanding and description, and 3) enables various independent tasks to complement and enhance each other through multi-task learning. By emphasizing multi-task interactions and the consistency of perception results, this task enables the simultaneous processing of fine-grained foreground instance segmentation, background semantic segmentation, and global fine-grained image captioning. Concretely, the FineGrip dataset includes 2,649 remote sensing images, 12,054 fine-grained instance segmentation masks belonging to 20 foreground things categories, 7,599 background semantic masks for 5 stuff classes and 13,245 captioning sentences. Furthermore, we propose a joint optimization-based panoptic perception model. Experimental results on FineGrip demonstrate the feasibility of the panoptic perception task and the beneficial effect of multi-task joint optimization on individual tasks. The dataset will be publicly available.
Structure Guided Large Language Model for SQL Generation
Feb 19, 2024Generating accurate Structured Querying Language (SQL) is a long-standing problem, especially in matching users' semantic queries with structured databases and then generating structured SQL. Existing models typically input queries and database schemas into the LLM and rely on the LLM to perform semantic-structure matching and generate structured SQL. However, such solutions overlook the structural information within user queries and databases, which can be utilized to enhance the generation of structured SQL. This oversight can lead to inaccurate or unexecutable SQL generation. To fully exploit the structure, we propose a structure-to-SQL framework, which leverages the inherent structure information to improve the SQL generation of LLMs. Specifically, we introduce our Structure Guided SQL~(SGU-SQL) generation model. SGU-SQL first links user queries and databases in a structure-enhanced manner. It then decomposes complicated linked structures with grammar trees to guide the LLM to generate the SQL step by step. Extensive experiments on two benchmark datasets illustrate that SGU-SQL can outperform sixteen SQL generation baselines.
PETDet: Proposal Enhancement for Two-Stage Fine-Grained Object Detection
Dec 16, 2023Fine-grained object detection (FGOD) extends object detection with the capability of fine-grained recognition. In recent two-stage FGOD methods, the region proposal serves as a crucial link between detection and fine-grained recognition. However, current methods overlook that some proposal-related procedures inherited from general detection are not equally suitable for FGOD, limiting the multi-task learning from generation, representation, to utilization. In this paper, we present PETDet (Proposal Enhancement for Two-stage fine-grained object detection) to better handle the sub-tasks in two-stage FGOD methods. Firstly, an anchor-free Quality Oriented Proposal Network (QOPN) is proposed with dynamic label assignment and attention-based decomposition to generate high-quality oriented proposals. Additionally, we present a Bilinear Channel Fusion Network (BCFN) to extract independent and discriminative features of the proposals. Furthermore, we design a novel Adaptive Recognition Loss (ARL) which offers guidance for the R-CNN head to focus on high-quality proposals. Extensive experiments validate the effectiveness of PETDet. Quantitative analysis reveals that PETDet with ResNet50 reaches state-of-the-art performance on various FGOD datasets, including FAIR1M-v1.0 (42.96 AP), FAIR1M-v2.0 (48.81 AP), MAR20 (85.91 AP) and ShipRSImageNet (74.90 AP). The proposed method also achieves superior compatibility between accuracy and inference speed. Our code and models will be released at https://github.com/canoe-Z/PETDet.
Refining the Optimization Target for Automatic Univariate Time Series Anomaly Detection in Monitoring Services
Jul 20, 2023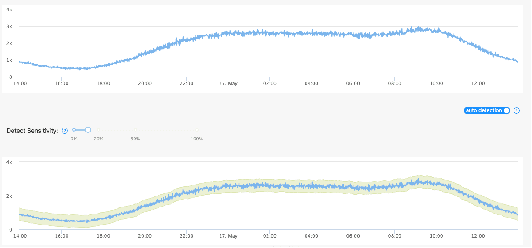

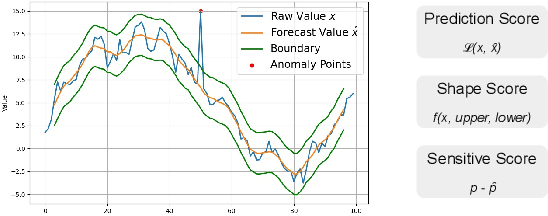
Time series anomaly detection is crucial for industrial monitoring services that handle a large volume of data, aiming to ensure reliability and optimize system performance. Existing methods often require extensive labeled resources and manual parameter selection, highlighting the need for automation. This paper proposes a comprehensive framework for automatic parameter optimization in time series anomaly detection models. The framework introduces three optimization targets: prediction score, shape score, and sensitivity score, which can be easily adapted to different model backbones without prior knowledge or manual labeling efforts. The proposed framework has been successfully applied online for over six months, serving more than 50,000 time series every minute. It simplifies the user's experience by requiring only an expected sensitive value, offering a user-friendly interface, and achieving desired detection results. Extensive evaluations conducted on public datasets and comparison with other methods further confirm the effectiveness of the proposed framework.
Wukong-Reader: Multi-modal Pre-training for Fine-grained Visual Document Understanding
Dec 19, 2022
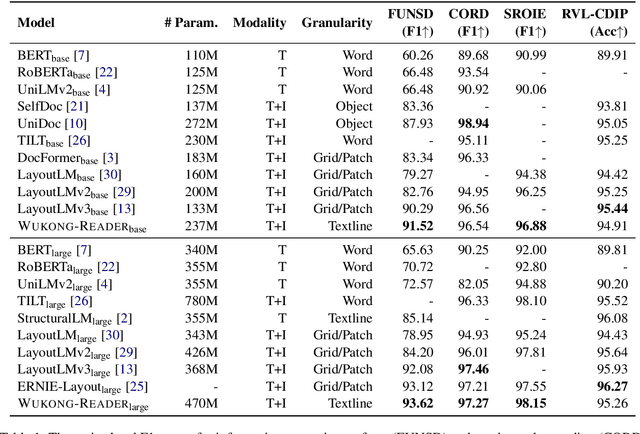
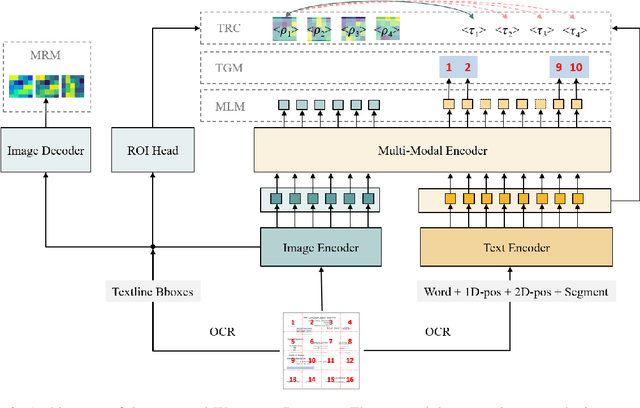
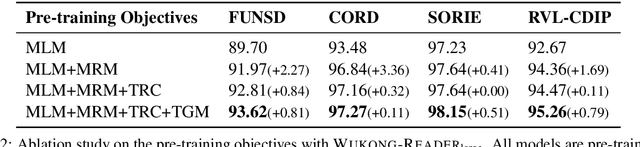
Unsupervised pre-training on millions of digital-born or scanned documents has shown promising advances in visual document understanding~(VDU). While various vision-language pre-training objectives are studied in existing solutions, the document textline, as an intrinsic granularity in VDU, has seldom been explored so far. A document textline usually contains words that are spatially and semantically correlated, which can be easily obtained from OCR engines. In this paper, we propose Wukong-Reader, trained with new pre-training objectives to leverage the structural knowledge nested in document textlines. We introduce textline-region contrastive learning to achieve fine-grained alignment between the visual regions and texts of document textlines. Furthermore, masked region modeling and textline-grid matching are also designed to enhance the visual and layout representations of textlines. Experiments show that our Wukong-Reader has superior performance on various VDU tasks such as information extraction. The fine-grained alignment over textlines also empowers Wukong-Reader with promising localization ability.
Decoder Tuning: Efficient Language Understanding as Decoding
Dec 16, 2022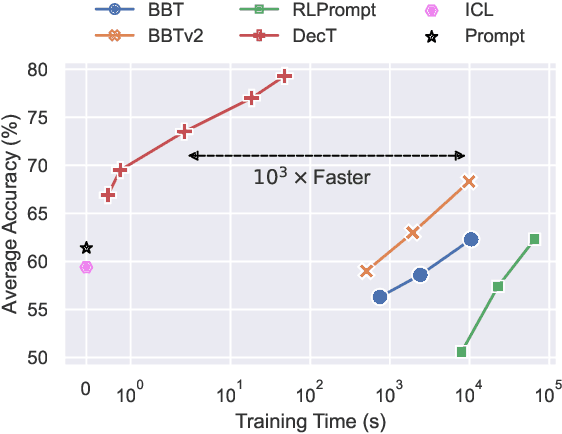
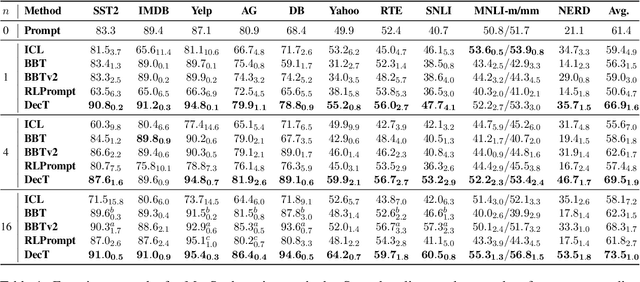
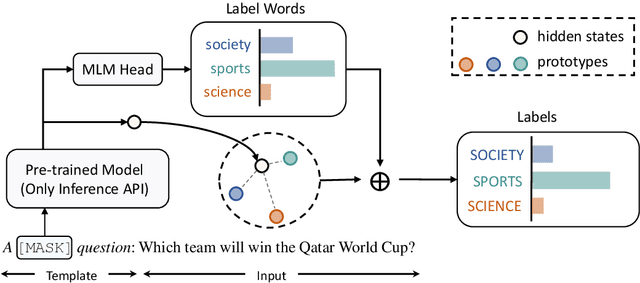
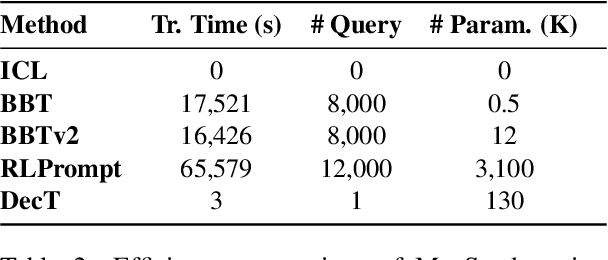
With the evergrowing sizes of pre-trained models (PTMs), it has been an emerging practice to only provide the inference APIs for users, namely model-as-a-service (MaaS) setting. To adapt PTMs with model parameters frozen, most current approaches focus on the input side, seeking for powerful prompts to stimulate models for correct answers. However, we argue that input-side adaptation could be arduous due to the lack of gradient signals and they usually require thousands of API queries, resulting in high computation and time costs. In light of this, we present Decoder Tuning (DecT), which in contrast optimizes task-specific decoder networks on the output side. Specifically, DecT first extracts prompt-stimulated output scores for initial predictions. On top of that, we train an additional decoder network on the output representations to incorporate posterior data knowledge. By gradient-based optimization, DecT can be trained within several seconds and requires only one PTM query per sample. Empirically, we conduct extensive natural language understanding experiments and show that DecT significantly outperforms state-of-the-art algorithms with a $10^3\times$ speed-up.
Quick Graph Conversion for Robust Recommendation
Oct 19, 2022
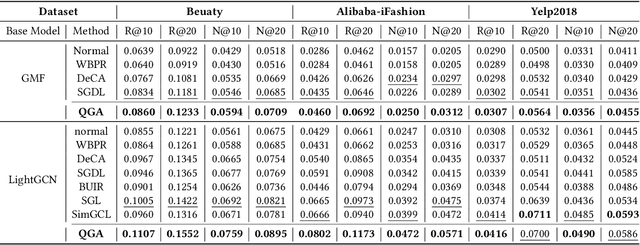
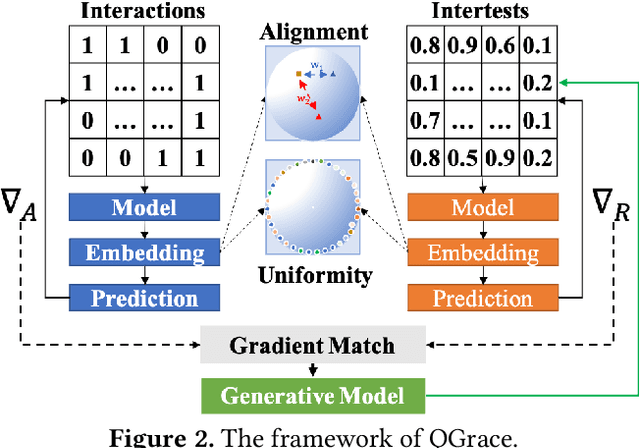
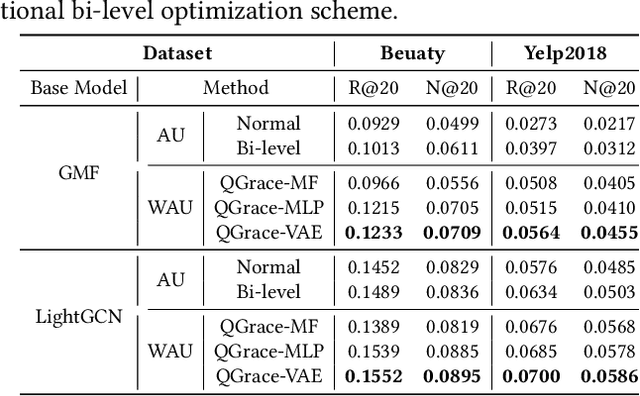
Implicit feedback plays a huge role in recommender systems, but its high noise characteristic seriously reduces its effect. To denoise implicit feedback, some efforts have been devoted to graph data augmentation (GDA) methods. Although the bi-level optimization thought of GDA guarantees better recommendation performance theoretically, it also leads to expensive time costs and severe space explosion problems. Specifically, bi-level optimization involves repeated traversal of all positive and negative instances after each optimization of the recommendation model. In this paper, we propose a new denoising paradigm, i.e., Quick Graph Conversion (QGrace), to effectively transform the original interaction graph into a purified (for positive instances) and densified (for negative instances) interest graph during the recommendation model training process. In QGrace, we leverage the gradient matching scheme based on elaborated generative models to fulfill the conversion and generation of an interest graph, elegantly overcoming the high time and space cost problems. To enable recommendation models to run on interest graphs that lack implicit feedback data, we provide a fine-grained objective function from the perspective of alignment and uniformity. The experimental results on three benchmark datasets demonstrate that the QGrace outperforms the state-of-the-art GDA methods and recommendation models in effectiveness and robustness.
An Effective Iterated Two-stage Heuristic Algorithm for the Multiple Traveling Salesmen Problem
Jan 24, 2022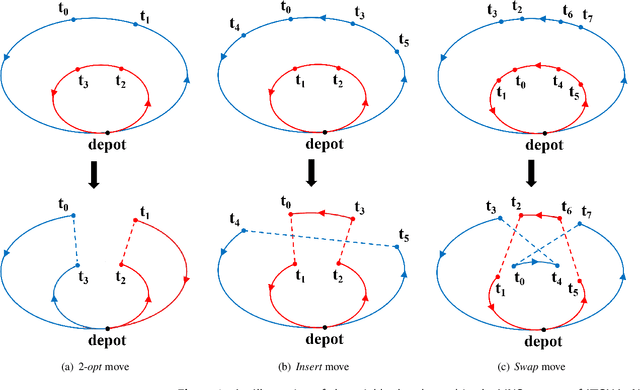

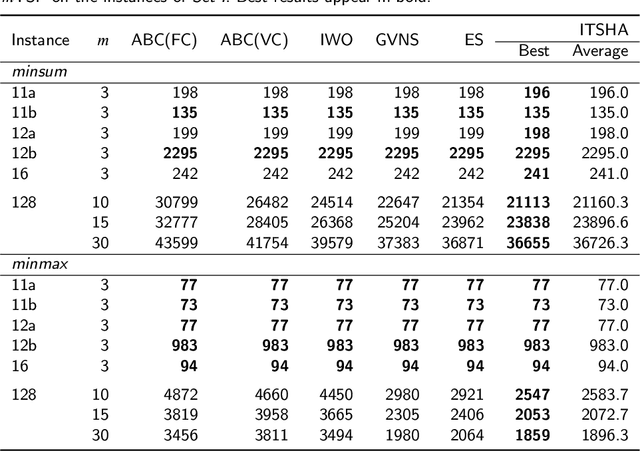

The multiple Traveling Salesmen Problem mTSP is a general extension of the famous NP-hard Traveling Salesmen Problem (TSP), that there are m (m>1) salesmen to visit the cities. In this paper, we address the mTSP with both of the minsum objective and the minmax objective, which aims at minimizing the total length of the m tours and the length of the longest tour among all the m tours, respectively. We propose an iterated two-stage heuristic algorithm, denoted as ITSHA. Each iteration of ITSHA consists of an initialization stage and an improvement stage. The purpose of the initialization stage is to generate high-quality and diverse initial solutions. The improvement stage mainly applies the variable neighborhood search (VNS) approach based on our proposed local search neighborhoods to optimize the initial solution generated by the initialization stage. Moreover, some local optima escaping approaches are employed to enhance the search ability of the algorithm. Extensive experimental results on a wide range of public benchmark instances show that ITSHA significantly outperforms state-of-the-art heuristic algorithms in solving the mTSP on both the objectives.
Federated Learning Algorithms for Generalized Mixed-effects Model (GLMM) on Horizontally Partitioned Data from Distributed Sources
Sep 28, 2021


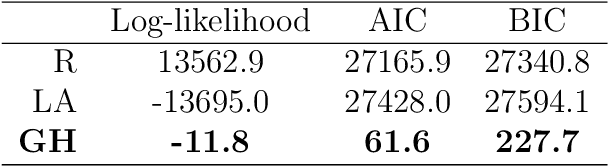
Objectives: This paper develops two algorithms to achieve federated generalized linear mixed effect models (GLMM), and compares the developed model's outcomes with each other, as well as that from the standard R package (`lme4'). Methods: The log-likelihood function of GLMM is approximated by two numerical methods (Laplace approximation and Gaussian Hermite approximation), which supports federated decomposition of GLMM to bring computation to data. Results: Our developed method can handle GLMM to accommodate hierarchical data with multiple non-independent levels of observations in a federated setting. The experiment results demonstrate comparable (Laplace) and superior (Gaussian-Hermite) performances with simulated and real-world data. Conclusion: We developed and compared federated GLMMs with different approximations, which can support researchers in analyzing biomedical data to accommodate mixed effects and address non-independence due to hierarchical structures (i.e., institutes, region, country, etc.).
Synthesis and Inpainting-Based MR-CT Registration for Image-Guided Thermal Ablation of Liver Tumors
Jul 30, 2019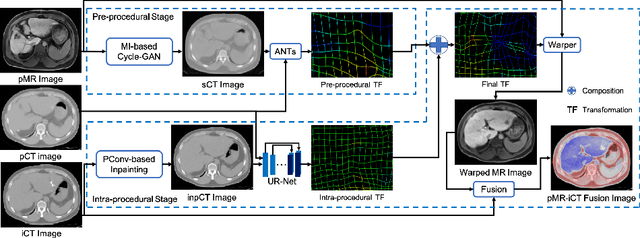
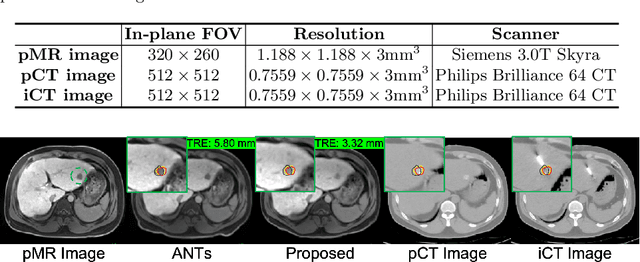
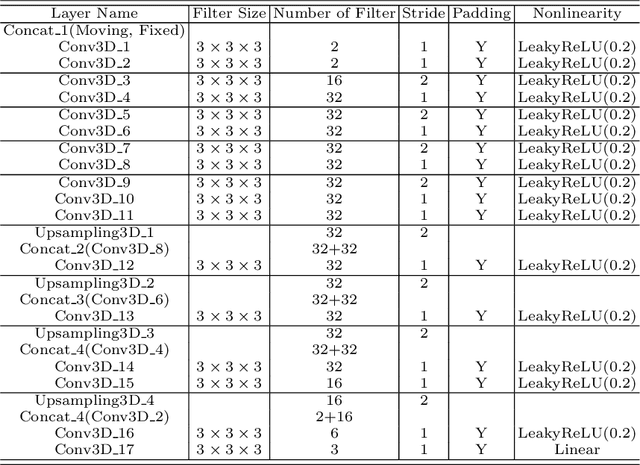
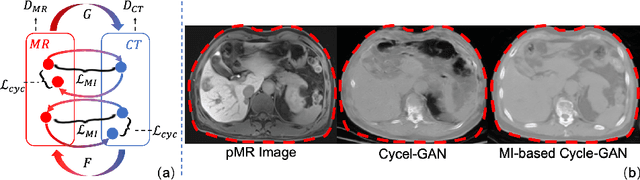
Thermal ablation is a minimally invasive procedure for treat-ing small or unresectable tumors. Although CT is widely used for guiding ablation procedures, the contrast of tumors against surrounding normal tissues in CT images is often poor, aggravating the difficulty in accurate thermal ablation. In this paper, we propose a fast MR-CT image registration method to overlay a pre-procedural MR (pMR) image onto an intra-procedural CT (iCT) image for guiding the thermal ablation of liver tumors. By first using a Cycle-GAN model with mutual information constraint to generate synthesized CT (sCT) image from the cor-responding pMR, pre-procedural MR-CT image registration is carried out through traditional mono-modality CT-CT image registration. At the intra-procedural stage, a partial-convolution-based network is first used to inpaint the probe and its artifacts in the iCT image. Then, an unsupervised registration network is used to efficiently align the pre-procedural CT (pCT) with the inpainted iCT (inpCT) image. The final transformation from pMR to iCT is obtained by combining the two estimated transformations,i.e., (1) from the pMR image space to the pCT image space (through sCT) and (2) from the pCT image space to the iCT image space (through inpCT). Experimental results confirm that the proposed method achieves high registration accuracy with a very fast computational speed.