 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoyang Li
LLMTune: Accelerate Database Knob Tuning with Large Language Models
Apr 17, 2024
Database knob tuning is a critical challenge in the database community, aiming to optimize knob values to enhance database performance for specific workloads. DBMS often feature hundreds of tunable knobs, posing a significant challenge for DBAs to recommend optimal configurations. Consequently, many machine learning-based tuning methods have been developed to automate this process. Despite the introduction of various optimizers, practical applications have unveiled a new problem: they typically require numerous workload runs to achieve satisfactory performance, a process that is both time-consuming and resource-intensive. This inefficiency largely stems from the optimal configuration often being substantially different from the default setting, necessitating multiple iterations during tuning. Recognizing this, we argue that an effective starting point could significantly reduce redundant exploration in less efficient areas, thereby potentially speeding up the tuning process for the optimizers. Based on this assumption, we introduce LLMTune, a large language model-based configuration generator designed to produce an initial, high-quality configuration for new workloads. These generated configurations can then serve as starting points for various base optimizers, accelerating their tuning processes. To obtain training data for LLMTune's supervised fine-tuning, we have devised a new automatic data generation framework capable of efficiently creating a large number of <workload, configuration> pairs. We have conducted thorough experiments to evaluate LLMTune's effectiveness with different workloads, such as TPC-H and JOB. In comparison to leading methods, LLMTune demonstrates a quicker ability to identify superior configurations. For instance, with the challenging TPC-H workload, our LLMTune achieves a significant 15.6x speed-up ratio in finding the best-performing configurations.
Developing and Deploying Industry Standards for Artificial Intelligence in Education (AIED): Challenges, Strategies, and Future Directions
Mar 25, 2024The adoption of Artificial Intelligence in Education (AIED) holds the promise of revolutionizing educational practices by offering personalized learning experiences, automating administrative and pedagogical tasks, and reducing the cost of content creation. However, the lack of standardized practices in the development and deployment of AIED solutions has led to fragmented ecosystems, which presents challenges in interoperability, scalability, and ethical governance. This article aims to address the critical need to develop and implement industry standards in AIED, offering a comprehensive analysis of the current landscape, challenges, and strategic approaches to overcome these obstacles. We begin by examining the various applications of AIED in various educational settings and identify key areas lacking in standardization, including system interoperability, ontology mapping, data integration, evaluation, and ethical governance. Then, we propose a multi-tiered framework for establishing robust industry standards for AIED. In addition, we discuss methodologies for the iterative development and deployment of standards, incorporating feedback loops from real-world applications to refine and adapt standards over time. The paper also highlights the role of emerging technologies and pedagogical theories in shaping future standards for AIED. Finally, we outline a strategic roadmap for stakeholders to implement these standards, fostering a cohesive and ethical AIED ecosystem. By establishing comprehensive industry standards, such as those by IEEE Artificial Intelligence Standards Committee (AISC) and International Organization for Standardization (ISO), we can accelerate and scale AIED solutions to improve educational outcomes, ensuring that technological advances align with the principles of inclusivity, fairness, and educational excellence.
HDLdebugger: Streamlining HDL debugging with Large Language Models
Mar 18, 2024
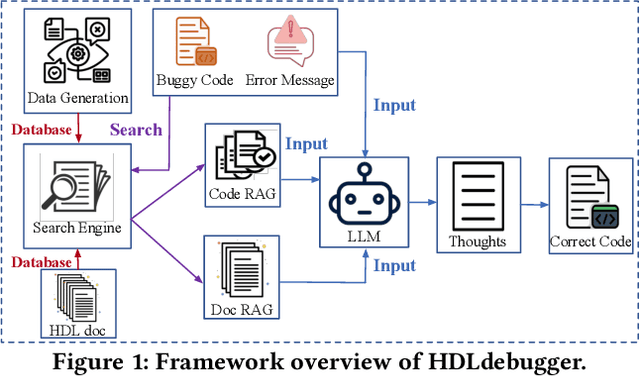

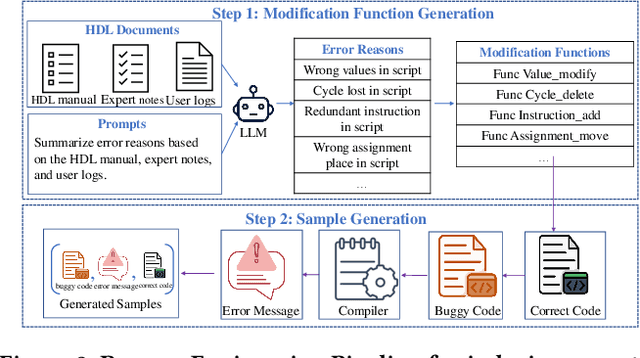
In the domain of chip design, Hardware Description Languages (HDLs) play a pivotal role. However, due to the complex syntax of HDLs and the limited availability of online resources, debugging HDL codes remains a difficult and time-intensive task, even for seasoned engineers. Consequently, there is a pressing need to develop automated HDL code debugging models, which can alleviate the burden on hardware engineers. Despite the strong capabilities of Large Language Models (LLMs) in generating, completing, and debugging software code, their utilization in the specialized field of HDL debugging has been limited and, to date, has not yielded satisfactory results. In this paper, we propose an LLM-assisted HDL debugging framework, namely HDLdebugger, which consists of HDL debugging data generation via a reverse engineering approach, a search engine for retrieval-augmented generation, and a retrieval-augmented LLM fine-tuning approach. Through the integration of these components, HDLdebugger can automate and streamline HDL debugging for chip design. Our comprehensive experiments, conducted on an HDL code dataset sourced from Huawei, reveal that HDLdebugger outperforms 13 cutting-edge LLM baselines, displaying exceptional effectiveness in HDL code debugging.
Spectral Invariant Learning for Dynamic Graphs under Distribution Shifts
Mar 08, 2024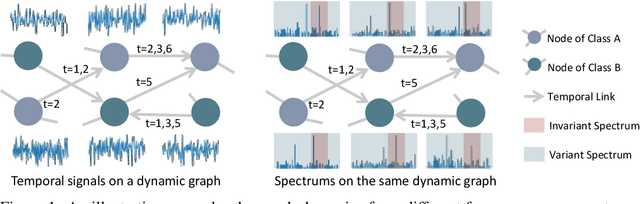
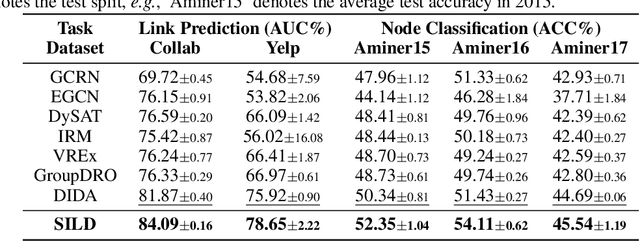
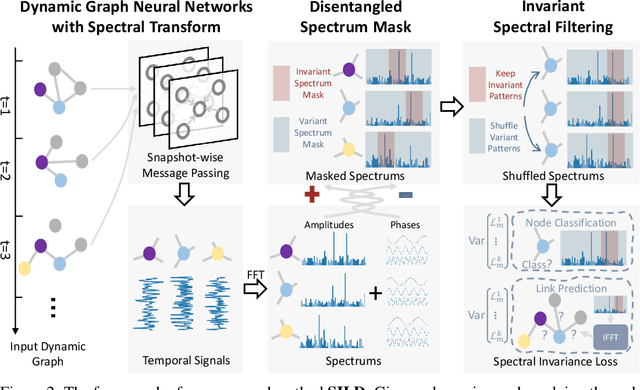
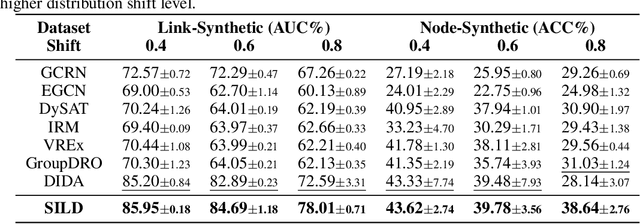
Dynamic graph neural networks (DyGNNs) currently struggle with handling distribution shifts that are inherent in dynamic graphs. Existing work on DyGNNs with out-of-distribution settings only focuses on the time domain, failing to handle cases involving distribution shifts in the spectral domain. In this paper, we discover that there exist cases with distribution shifts unobservable in the time domain while observable in the spectral domain, and propose to study distribution shifts on dynamic graphs in the spectral domain for the first time. However, this investigation poses two key challenges: i) it is non-trivial to capture different graph patterns that are driven by various frequency components entangled in the spectral domain; and ii) it remains unclear how to handle distribution shifts with the discovered spectral patterns. To address these challenges, we propose Spectral Invariant Learning for Dynamic Graphs under Distribution Shifts (SILD), which can handle distribution shifts on dynamic graphs by capturing and utilizing invariant and variant spectral patterns. Specifically, we first design a DyGNN with Fourier transform to obtain the ego-graph trajectory spectrums, allowing the mixed dynamic graph patterns to be transformed into separate frequency components. We then develop a disentangled spectrum mask to filter graph dynamics from various frequency components and discover the invariant and variant spectral patterns. Finally, we propose invariant spectral filtering, which encourages the model to rely on invariant patterns for generalization under distribution shifts. Experimental results on synthetic and real-world dynamic graph datasets demonstrate the superiority of our method for both node classification and link prediction tasks under distribution shifts.
Intent-aware Recommendation via Disentangled Graph Contrastive Learning
Mar 06, 2024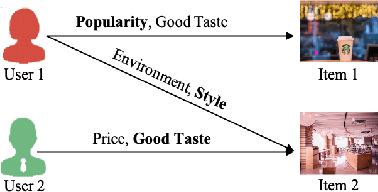
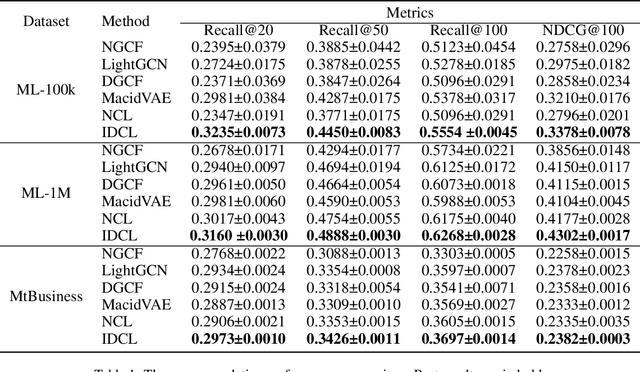
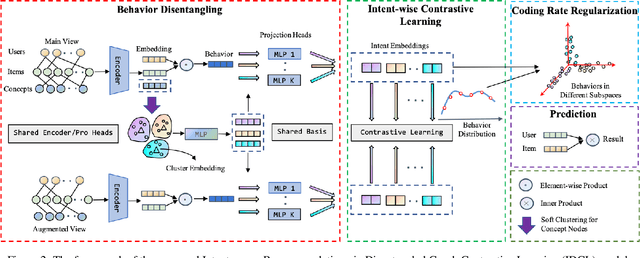
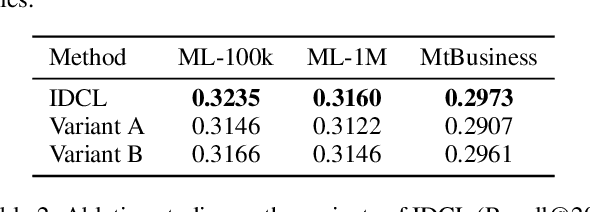
Graph neural network (GNN) based recommender systems have become one of the mainstream trends due to the powerful learning ability from user behavior data. Understanding the user intents from behavior data is the key to recommender systems, which poses two basic requirements for GNN-based recommender systems. One is how to learn complex and diverse intents especially when the user behavior is usually inadequate in reality. The other is different behaviors have different intent distributions, so how to establish their relations for a more explainable recommender system. In this paper, we present the Intent-aware Recommendation via Disentangled Graph Contrastive Learning (IDCL), which simultaneously learns interpretable intents and behavior distributions over those intents. Specifically, we first model the user behavior data as a user-item-concept graph, and design a GNN based behavior disentangling module to learn the different intents. Then we propose the intent-wise contrastive learning to enhance the intent disentangling and meanwhile infer the behavior distributions. Finally, the coding rate reduction regularization is introduced to make the behaviors of different intents orthogonal. Extensive experiments demonstrate the effectiveness of IDCL in terms of substantial improvement and the interpretability.
* Accepted by IJCAI 2023
CodeS: Towards Building Open-source Language Models for Text-to-SQL
Feb 26, 2024Language models have shown promising performance on the task of translating natural language questions into SQL queries (Text-to-SQL). However, most of the state-of-the-art (SOTA) approaches rely on powerful yet closed-source large language models (LLMs), such as ChatGPT and GPT-4, which may have the limitations of unclear model architectures, data privacy risks, and expensive inference overheads. To address the limitations, we introduce CodeS, a series of pre-trained language models with parameters ranging from 1B to 15B, specifically designed for the text-to-SQL task. CodeS is a fully open-source language model, which achieves superior accuracy with much smaller parameter sizes. This paper studies the research challenges in building CodeS. To enhance the SQL generation abilities of CodeS, we adopt an incremental pre-training approach using a specifically curated SQL-centric corpus. Based on this, we address the challenges of schema linking and rapid domain adaptation through strategic prompt construction and a bi-directional data augmentation technique. We conduct comprehensive evaluations on multiple datasets, including the widely used Spider benchmark, the newly released BIRD benchmark, robustness-diagnostic benchmarks such as Spider-DK, Spider-Syn, Spider-Realistic, and Dr.Spider, as well as two real-world datasets created for financial and academic applications. The experimental results show that our CodeS achieves new SOTA accuracy and robustness on nearly all challenging text-to-SQL benchmarks.
Cross-Space Adaptive Filter: Integrating Graph Topology and Node Attributes for Alleviating the Over-smoothing Problem
Jan 26, 2024The vanilla Graph Convolutional Network (GCN) uses a low-pass filter to extract low-frequency signals from graph topology, which may lead to the over-smoothing problem when GCN goes deep. To this end, various methods have been proposed to create an adaptive filter by incorporating an extra filter (e.g., a high-pass filter) extracted from the graph topology. However, these methods heavily rely on topological information and ignore the node attribute space, which severely sacrifices the expressive power of the deep GCNs, especially when dealing with disassortative graphs. In this paper, we propose a cross-space adaptive filter, called CSF, to produce the adaptive-frequency information extracted from both the topology and attribute spaces. Specifically, we first derive a tailored attribute-based high-pass filter that can be interpreted theoretically as a minimizer for semi-supervised kernel ridge regression. Then, we cast the topology-based low-pass filter as a Mercer's kernel within the context of GCNs. This serves as a foundation for combining it with the attribute-based filter to capture the adaptive-frequency information. Finally, we derive the cross-space filter via an effective multiple-kernel learning strategy, which unifies the attribute-based high-pass filter and the topology-based low-pass filter. This helps to address the over-smoothing problem while maintaining effectiveness. Extensive experiments demonstrate that CSF not only successfully alleviates the over-smoothing problem but also promotes the effectiveness of the node classification task.
Graph Invariant Learning with Subgraph Co-mixup for Out-Of-Distribution Generalization
Dec 18, 2023Graph neural networks (GNNs) have been demonstrated to perform well in graph representation learning, but always lacking in generalization capability when tackling out-of-distribution (OOD) data. Graph invariant learning methods, backed by the invariance principle among defined multiple environments, have shown effectiveness in dealing with this issue. However, existing methods heavily rely on well-predefined or accurately generated environment partitions, which are hard to be obtained in practice, leading to sub-optimal OOD generalization performances. In this paper, we propose a novel graph invariant learning method based on invariant and variant patterns co-mixup strategy, which is capable of jointly generating mixed multiple environments and capturing invariant patterns from the mixed graph data. Specifically, we first adopt a subgraph extractor to identify invariant subgraphs. Subsequently, we design one novel co-mixup strategy, i.e., jointly conducting environment Mixup and invariant Mixup. For the environment Mixup, we mix the variant environment-related subgraphs so as to generate sufficiently diverse multiple environments, which is important to guarantee the quality of the graph invariant learning. For the invariant Mixup, we mix the invariant subgraphs, further encouraging to capture invariant patterns behind graphs while getting rid of spurious correlations for OOD generalization. We demonstrate that the proposed environment Mixup and invariant Mixup can mutually promote each other. Extensive experiments on both synthetic and real-world datasets demonstrate that our method significantly outperforms state-of-the-art under various distribution shifts.
Out-of-Distribution Generalized Dynamic Graph Neural Network with Disentangled Intervention and Invariance Promotion
Nov 24, 2023Dynamic graph neural networks (DyGNNs) have demonstrated powerful predictive abilities by exploiting graph structural and temporal dynamics. However, the existing DyGNNs fail to handle distribution shifts, which naturally exist in dynamic graphs, mainly because the patterns exploited by DyGNNs may be variant with respect to labels under distribution shifts. In this paper, we propose Disentangled Intervention-based Dynamic graph Attention networks with Invariance Promotion (I-DIDA) to handle spatio-temporal distribution shifts in dynamic graphs by discovering and utilizing invariant patterns, i.e., structures and features whose predictive abilities are stable across distribution shifts. Specifically, we first propose a disentangled spatio-temporal attention network to capture the variant and invariant patterns. By utilizing the disentangled patterns, we design a spatio-temporal intervention mechanism to create multiple interventional distributions and an environment inference module to infer the latent spatio-temporal environments, and minimize the variance of predictions among these intervened distributions and environments, so that our model can make predictions based on invariant patterns with stable predictive abilities under distribution shifts. Extensive experiments demonstrate the superiority of our method over state-of-the-art baselines under distribution shifts. Our work is the first study of spatio-temporal distribution shifts in dynamic graphs, to the best of our knowledge.
LLM4DyG: Can Large Language Models Solve Problems on Dynamic Graphs?
Oct 26, 2023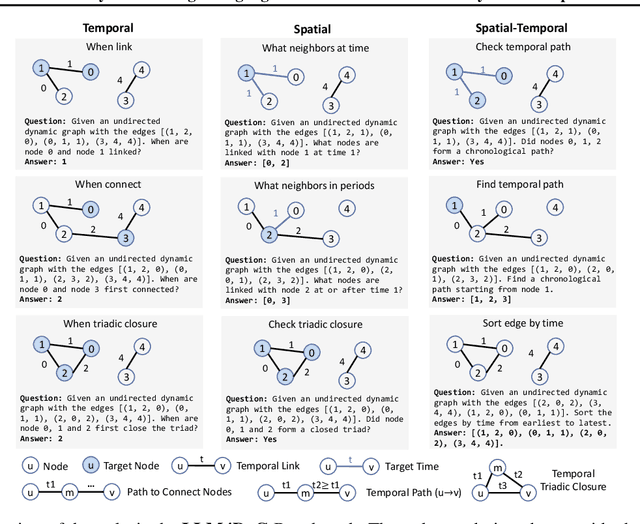
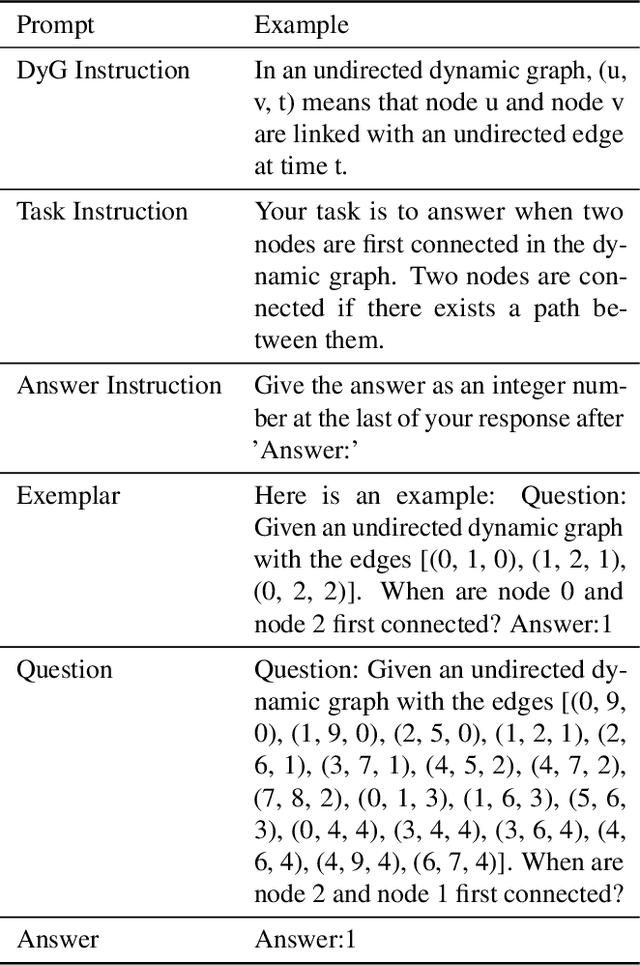

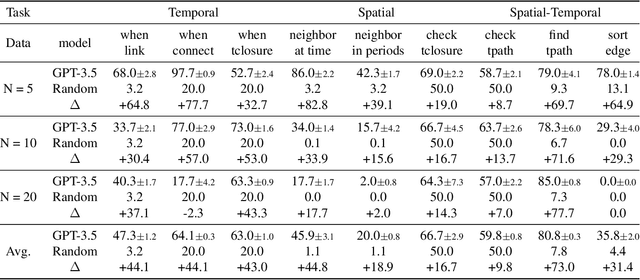
In an era marked by the increasing adoption of Large Language Models (LLMs) for various tasks, there is a growing focus on exploring LLMs' capabilities in handling web data, particularly graph data. Dynamic graphs, which capture temporal network evolution patterns, are ubiquitous in real-world web data. Evaluating LLMs' competence in understanding spatial-temporal information on dynamic graphs is essential for their adoption in web applications, which remains unexplored in the literature. In this paper, we bridge the gap via proposing to evaluate LLMs' spatial-temporal understanding abilities on dynamic graphs, to the best of our knowledge, for the first time. Specifically, we propose the LLM4DyG benchmark, which includes nine specially designed tasks considering the capability evaluation of LLMs from both temporal and spatial dimensions. Then, we conduct extensive experiments to analyze the impacts of different data generators, data statistics, prompting techniques, and LLMs on the model performance. Finally, we propose Disentangled Spatial-Temporal Thoughts (DST2) for LLMs on dynamic graphs to enhance LLMs' spatial-temporal understanding abilities. Our main observations are: 1) LLMs have preliminary spatial-temporal understanding abilities on dynamic graphs, 2) Dynamic graph tasks show increasing difficulties for LLMs as the graph size and density increase, while not sensitive to the time span and data generation mechanism, 3) the proposed DST2 prompting method can help to improve LLMs' spatial-temporal understanding abilities on dynamic graphs for most tasks. The data and codes will be open-sourced at publication time.