 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuiping Li
LLMTune: Accelerate Database Knob Tuning with Large Language Models
Apr 17, 2024
Database knob tuning is a critical challenge in the database community, aiming to optimize knob values to enhance database performance for specific workloads. DBMS often feature hundreds of tunable knobs, posing a significant challenge for DBAs to recommend optimal configurations. Consequently, many machine learning-based tuning methods have been developed to automate this process. Despite the introduction of various optimizers, practical applications have unveiled a new problem: they typically require numerous workload runs to achieve satisfactory performance, a process that is both time-consuming and resource-intensive. This inefficiency largely stems from the optimal configuration often being substantially different from the default setting, necessitating multiple iterations during tuning. Recognizing this, we argue that an effective starting point could significantly reduce redundant exploration in less efficient areas, thereby potentially speeding up the tuning process for the optimizers. Based on this assumption, we introduce LLMTune, a large language model-based configuration generator designed to produce an initial, high-quality configuration for new workloads. These generated configurations can then serve as starting points for various base optimizers, accelerating their tuning processes. To obtain training data for LLMTune's supervised fine-tuning, we have devised a new automatic data generation framework capable of efficiently creating a large number of <workload, configuration> pairs. We have conducted thorough experiments to evaluate LLMTune's effectiveness with different workloads, such as TPC-H and JOB. In comparison to leading methods, LLMTune demonstrates a quicker ability to identify superior configurations. For instance, with the challenging TPC-H workload, our LLMTune achieves a significant 15.6x speed-up ratio in finding the best-performing configurations.
SGSH: Stimulate Large Language Models with Skeleton Heuristics for Knowledge Base Question Generation
Apr 02, 2024Knowledge base question generation (KBQG) aims to generate natural language questions from a set of triplet facts extracted from KB. Existing methods have significantly boosted the performance of KBQG via pre-trained language models (PLMs) thanks to the richly endowed semantic knowledge. With the advance of pre-training techniques, large language models (LLMs) (e.g., GPT-3.5) undoubtedly possess much more semantic knowledge. Therefore, how to effectively organize and exploit the abundant knowledge for KBQG becomes the focus of our study. In this work, we propose SGSH--a simple and effective framework to Stimulate GPT-3.5 with Skeleton Heuristics to enhance KBQG. The framework incorporates "skeleton heuristics", which provides more fine-grained guidance associated with each input to stimulate LLMs to generate optimal questions, encompassing essential elements like the question phrase and the auxiliary verb.More specifically, we devise an automatic data construction strategy leveraging ChatGPT to construct a skeleton training dataset, based on which we employ a soft prompting approach to train a BART model dedicated to generating the skeleton associated with each input. Subsequently, skeleton heuristics are encoded into the prompt to incentivize GPT-3.5 to generate desired questions. Extensive experiments demonstrate that SGSH derives the new state-of-the-art performance on the KBQG tasks.
Open-World Semi-Supervised Learning for Node Classification
Mar 18, 2024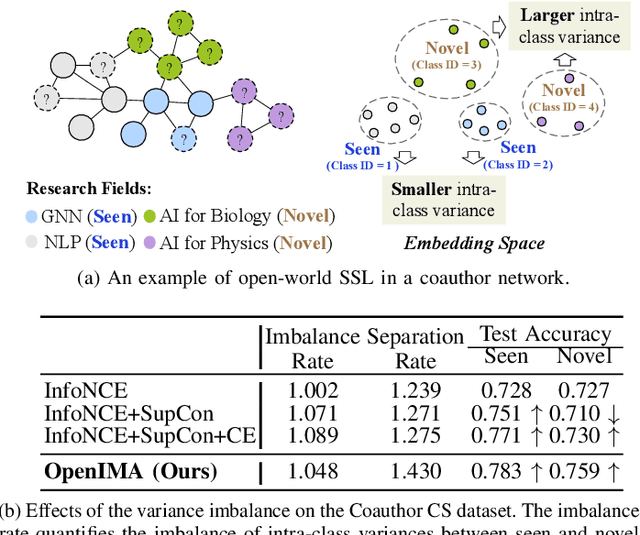
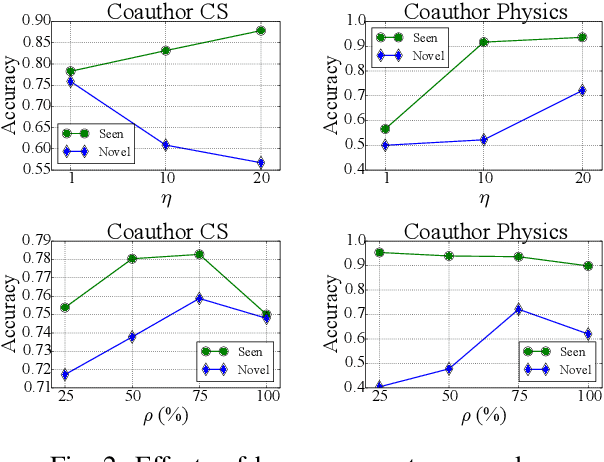
Open-world semi-supervised learning (Open-world SSL) for node classification, that classifies unlabeled nodes into seen classes or multiple novel classes, is a practical but under-explored problem in the graph community. As only seen classes have human labels, they are usually better learned than novel classes, and thus exhibit smaller intra-class variances within the embedding space (named as imbalance of intra-class variances between seen and novel classes). Based on empirical and theoretical analysis, we find the variance imbalance can negatively impact the model performance. Pre-trained feature encoders can alleviate this issue via producing compact representations for novel classes. However, creating general pre-trained encoders for various types of graph data has been proven to be challenging. As such, there is a demand for an effective method that does not rely on pre-trained graph encoders. In this paper, we propose an IMbalance-Aware method named OpenIMA for Open-world semi-supervised node classification, which trains the node classification model from scratch via contrastive learning with bias-reduced pseudo labels. Extensive experiments on seven popular graph benchmarks demonstrate the effectiveness of OpenIMA, and the source code has been available on GitHub.
A Survey on Neural Question Generation: Methods, Applications, and Prospects
Feb 28, 2024In this survey, we present a detailed examination of the advancements in Neural Question Generation (NQG), a field leveraging neural network techniques to generate relevant questions from diverse inputs like knowledge bases, texts, and images. The survey begins with an overview of NQG's background, encompassing the task's problem formulation, prevalent benchmark datasets, established evaluation metrics, and notable applications. It then methodically classifies NQG approaches into three predominant categories: structured NQG, which utilizes organized data sources, unstructured NQG, focusing on more loosely structured inputs like texts or visual content, and hybrid NQG, drawing on diverse input modalities. This classification is followed by an in-depth analysis of the distinct neural network models tailored for each category, discussing their inherent strengths and potential limitations. The survey culminates with a forward-looking perspective on the trajectory of NQG, identifying emergent research trends and prospective developmental paths. Accompanying this survey is a curated collection of related research papers, datasets and codes, systematically organized on Github, providing an extensive reference for those delving into NQG.
CodeS: Towards Building Open-source Language Models for Text-to-SQL
Feb 26, 2024Language models have shown promising performance on the task of translating natural language questions into SQL queries (Text-to-SQL). However, most of the state-of-the-art (SOTA) approaches rely on powerful yet closed-source large language models (LLMs), such as ChatGPT and GPT-4, which may have the limitations of unclear model architectures, data privacy risks, and expensive inference overheads. To address the limitations, we introduce CodeS, a series of pre-trained language models with parameters ranging from 1B to 15B, specifically designed for the text-to-SQL task. CodeS is a fully open-source language model, which achieves superior accuracy with much smaller parameter sizes. This paper studies the research challenges in building CodeS. To enhance the SQL generation abilities of CodeS, we adopt an incremental pre-training approach using a specifically curated SQL-centric corpus. Based on this, we address the challenges of schema linking and rapid domain adaptation through strategic prompt construction and a bi-directional data augmentation technique. We conduct comprehensive evaluations on multiple datasets, including the widely used Spider benchmark, the newly released BIRD benchmark, robustness-diagnostic benchmarks such as Spider-DK, Spider-Syn, Spider-Realistic, and Dr.Spider, as well as two real-world datasets created for financial and academic applications. The experimental results show that our CodeS achieves new SOTA accuracy and robustness on nearly all challenging text-to-SQL benchmarks.
FOSS: A Self-Learned Doctor for Query Optimizer
Dec 11, 2023Various works have utilized deep reinforcement learning (DRL) to address the query optimization problem in database system. They either learn to construct plans from scratch in a bottom-up manner or guide the plan generation behavior of traditional optimizer using hints. While these methods have achieved some success, they face challenges in either low training efficiency or limited plan search space. To address these challenges, we introduce FOSS, a novel DRL-based framework for query optimization. FOSS initiates optimization from the original plan generated by a traditional optimizer and incrementally refines suboptimal nodes of the plan through a sequence of actions. Additionally, we devise an asymmetric advantage model to evaluate the advantage between two plans. We integrate it with a traditional optimizer to form a simulated environment. Leveraging this simulated environment, FOSS can bootstrap itself to rapidly generate a large amount of high-quality simulated experiences. FOSS then learns and improves its optimization capability from these simulated experiences. We evaluate the performance of FOSS on Join Order Benchmark, TPC-DS, and Stack Overflow. The experimental results demonstrate that FOSS outperforms the state-of-the-art methods in terms of latency performance and optimization time. Compared to PostgreSQL, FOSS achieves savings ranging from 15% to 83% in total latency across different benchmarks.
Diversifying Question Generation over Knowledge Base via External Natural Questions
Sep 23, 2023

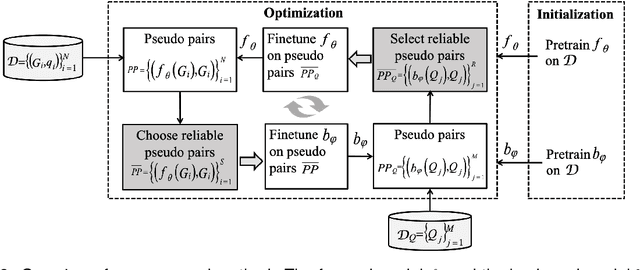
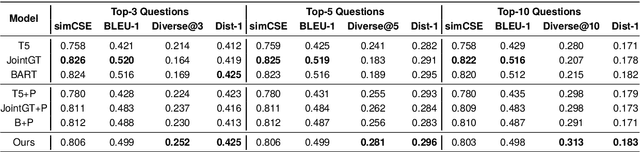
Previous methods on knowledge base question generation (KBQG) primarily focus on enhancing the quality of a single generated question. Recognizing the remarkable paraphrasing ability of humans, we contend that diverse texts should convey the same semantics through varied expressions. The above insights make diversifying question generation an intriguing task, where the first challenge is evaluation metrics for diversity. Current metrics inadequately assess the above diversity since they calculate the ratio of unique n-grams in the generated question itself, which leans more towards measuring duplication rather than true diversity. Accordingly, we devise a new diversity evaluation metric, which measures the diversity among top-k generated questions for each instance while ensuring their relevance to the ground truth. Clearly, the second challenge is how to enhance diversifying question generation. To address this challenge, we introduce a dual model framework interwoven by two selection strategies to generate diverse questions leveraging external natural questions. The main idea of our dual framework is to extract more diverse expressions and integrate them into the generation model to enhance diversifying question generation. Extensive experiments on widely used benchmarks for KBQG demonstrate that our proposed approach generates highly diverse questions and improves the performance of question answering tasks.
Transformer Compression via Subspace Projection
Aug 31, 2023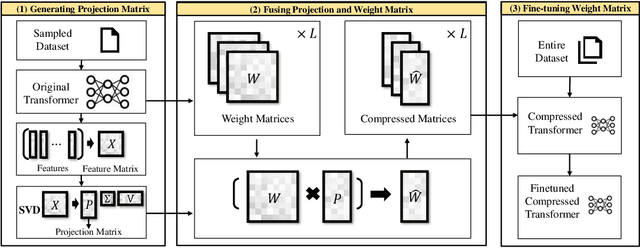
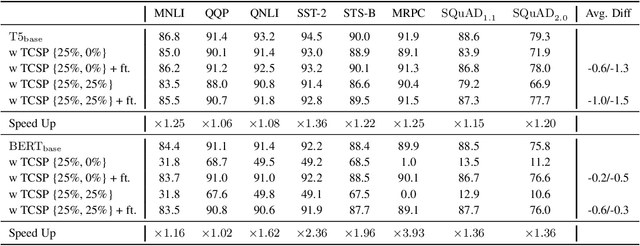


We propose TCSP, a novel method for compressing a transformer model by focusing on reducing the hidden size of the model. By projecting the whole transform model into a subspace, we enable matrix operations between the weight matrices in the model and features in a reduced-dimensional space, leading to significant reductions in model parameters and computing resources. To establish this subspace, we decompose the feature matrix, derived from different layers of sampled data instances, into a projection matrix. For evaluation, TCSP is applied to compress T5 and BERT models on the GLUE and SQuAD benchmarks. Experimental results demonstrate that TCSP achieves a compression ratio of 44\% with at most 1.6\% degradation in accuracy, surpassing or matching prior compression methods. Furthermore, TCSP exhibits compatibility with other methods targeting filter and attention head size compression.
Semi-Supervised Learning via Weight-aware Distillation under Class Distribution Mismatch
Aug 23, 2023
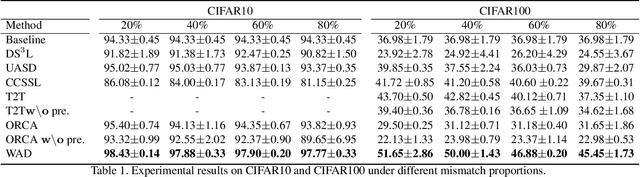

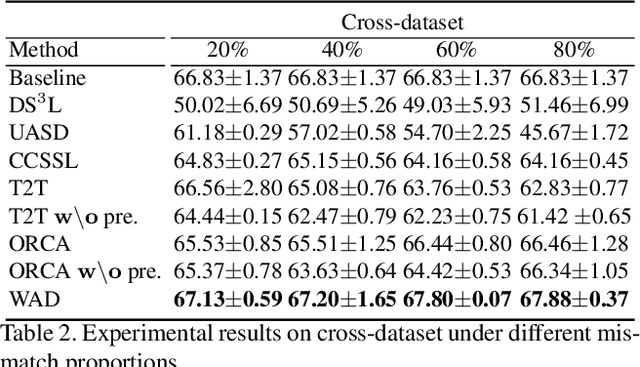
Semi-Supervised Learning (SSL) under class distribution mismatch aims to tackle a challenging problem wherein unlabeled data contain lots of unknown categories unseen in the labeled ones. In such mismatch scenarios, traditional SSL suffers severe performance damage due to the harmful invasion of the instances with unknown categories into the target classifier. In this study, by strict mathematical reasoning, we reveal that the SSL error under class distribution mismatch is composed of pseudo-labeling error and invasion error, both of which jointly bound the SSL population risk. To alleviate the SSL error, we propose a robust SSL framework called Weight-Aware Distillation (WAD) that, by weights, selectively transfers knowledge beneficial to the target task from unsupervised contrastive representation to the target classifier. Specifically, WAD captures adaptive weights and high-quality pseudo labels to target instances by exploring point mutual information (PMI) in representation space to maximize the role of unlabeled data and filter unknown categories. Theoretically, we prove that WAD has a tight upper bound of population risk under class distribution mismatch. Experimentally, extensive results demonstrate that WAD outperforms five state-of-the-art SSL approaches and one standard baseline on two benchmark datasets, CIFAR10 and CIFAR100, and an artificial cross-dataset. The code is available at https://github.com/RUC-DWBI-ML/research/tree/main/WAD-master.
FC-KBQA: A Fine-to-Coarse Composition Framework for Knowledge Base Question Answering
Jun 26, 2023
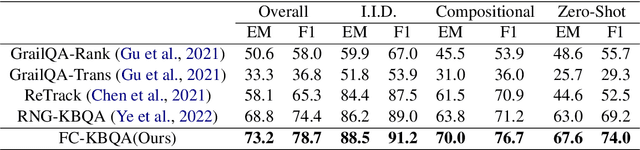
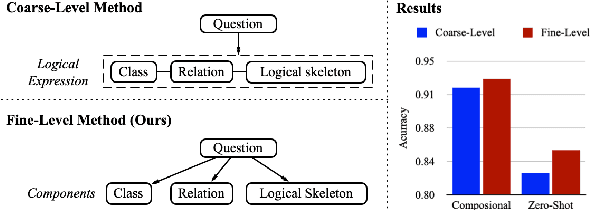
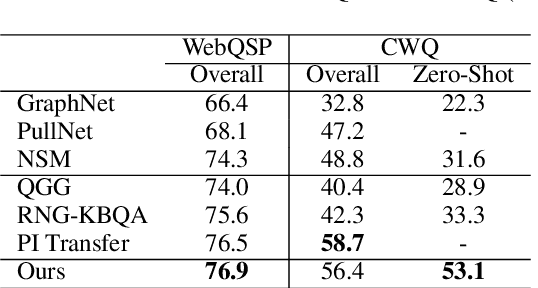
The generalization problem on KBQA has drawn considerable attention. Existing research suffers from the generalization issue brought by the entanglement in the coarse-grained modeling of the logical expression, or inexecutability issues due to the fine-grained modeling of disconnected classes and relations in real KBs. We propose a Fine-to-Coarse Composition framework for KBQA (FC-KBQA) to both ensure the generalization ability and executability of the logical expression. The main idea of FC-KBQA is to extract relevant fine-grained knowledge components from KB and reformulate them into middle-grained knowledge pairs for generating the final logical expressions. FC-KBQA derives new state-of-the-art performance on GrailQA and WebQSP, and runs 4 times faster than the baseline.