 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaokang Zhang
MaskCD: A Remote Sensing Change Detection Network Based on Mask Classification
Apr 18, 2024
Change detection (CD) from remote sensing (RS) images using deep learning has been widely investigated in the literature. It is typically regarded as a pixel-wise labeling task that aims to classify each pixel as changed or unchanged. Although per-pixel classification networks in encoder-decoder structures have shown dominance, they still suffer from imprecise boundaries and incomplete object delineation at various scenes. For high-resolution RS images, partly or totally changed objects are more worthy of attention rather than a single pixel. Therefore, we revisit the CD task from the mask prediction and classification perspective and propose MaskCD to detect changed areas by adaptively generating categorized masks from input image pairs. Specifically, it utilizes a cross-level change representation perceiver (CLCRP) to learn multiscale change-aware representations and capture spatiotemporal relations from encoded features by exploiting deformable multihead self-attention (DeformMHSA). Subsequently, a masked-attention-based detection transformers (MA-DETR) decoder is developed to accurately locate and identify changed objects based on masked attention and self-attention mechanisms. It reconstructs the desired changed objects by decoding the pixel-wise representations into learnable mask proposals and making final predictions from these candidates. Experimental results on five benchmark datasets demonstrate the proposed approach outperforms other state-of-the-art models. Codes and pretrained models are available online (https://github.com/EricYu97/MaskCD).
Transferable and Efficient Non-Factual Content Detection via Probe Training with Offline Consistency Checking
Apr 10, 2024Detecting non-factual content is a longstanding goal to increase the trustworthiness of large language models (LLMs) generations. Current factuality probes, trained using humanannotated labels, exhibit limited transferability to out-of-distribution content, while online selfconsistency checking imposes extensive computation burden due to the necessity of generating multiple outputs. This paper proposes PINOSE, which trains a probing model on offline self-consistency checking results, thereby circumventing the need for human-annotated data and achieving transferability across diverse data distributions. As the consistency check process is offline, PINOSE reduces the computational burden of generating multiple responses by online consistency verification. Additionally, it examines various aspects of internal states prior to response decoding, contributing to more effective detection of factual inaccuracies. Experiment results on both factuality detection and question answering benchmarks show that PINOSE achieves surpassing results than existing factuality detection methods. Our code and datasets are publicly available on this anonymized repository.
Frequency Decomposition-Driven Unsupervised Domain Adaptation for Remote Sensing Image Semantic Segmentation
Apr 06, 2024Cross-domain semantic segmentation of remote sensing (RS) imagery based on unsupervised domain adaptation (UDA) techniques has significantly advanced deep-learning applications in the geosciences. Recently, with its ingenious and versatile architecture, the Transformer model has been successfully applied in RS-UDA tasks. However, existing UDA methods mainly focus on domain alignment in the high-level feature space. It is still challenging to retain cross-domain local spatial details and global contextual semantics simultaneously, which is crucial for the RS image semantic segmentation task. To address these problems, we propose novel high/low-frequency decomposition (HLFD) techniques to guide representation alignment in cross-domain semantic segmentation. Specifically, HLFD attempts to decompose the feature maps into high- and low-frequency components before performing the domain alignment in the corresponding subspaces. Secondly, to further facilitate the alignment of decomposed features, we propose a fully global-local generative adversarial network, namely GLGAN, to learn domain-invariant detailed and semantic features across domains by leveraging global-local transformer blocks (GLTBs). By integrating HLFD techniques and the GLGAN, a novel UDA framework called FD-GLGAN is developed to improve the cross-domain transferability and generalization capability of semantic segmentation models. Extensive experiments on two fine-resolution benchmark datasets, namely ISPRS Potsdam and ISPRS Vaihingen, highlight the effectiveness and superiority of the proposed approach as compared to the state-of-the-art UDA methods. The source code for this work will be accessible at https://github.com/sstary/SSRS.
RS3Mamba: Visual State Space Model for Remote Sensing Images Semantic Segmentation
Apr 03, 2024Semantic segmentation of remote sensing images is a fundamental task in geoscience research. However, there are some significant shortcomings for the widely used convolutional neural networks (CNNs) and Transformers. The former is limited by its insufficient long-range modeling capabilities, while the latter is hampered by its computational complexity. Recently, a novel visual state space (VSS) model represented by Mamba has emerged, capable of modeling long-range relationships with linear computability. In this work, we propose a novel dual-branch network named remote sensing images semantic segmentation Mamba (RS3Mamba) to incorporate this innovative technology into remote sensing tasks. Specifically, RS3Mamba utilizes VSS blocks to construct an auxiliary branch, providing additional global information to convolution-based main branch. Moreover, considering the distinct characteristics of the two branches, we introduce a collaborative completion module (CCM) to enhance and fuse features from the dual-encoder. Experimental results on two widely used datasets, ISPRS Vaihingen and LoveDA Urban, demonstrate the effectiveness and potential of the proposed RS3Mamba. To the best of our knowledge, this is the first vision Mamba specifically designed for remote sensing images semantic segmentation. The source code will be made available at https://github.com/sstary/SSRS.
TableLLM: Enabling Tabular Data Manipulation by LLMs in Real Office Usage Scenarios
Apr 01, 2024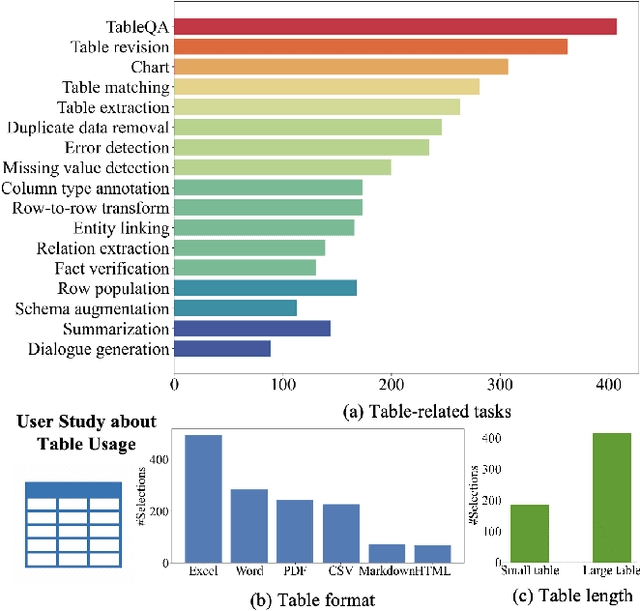

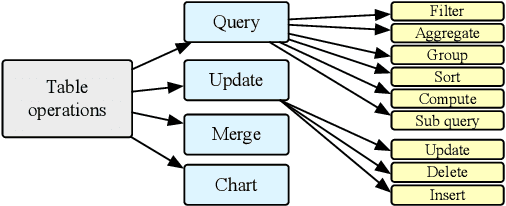
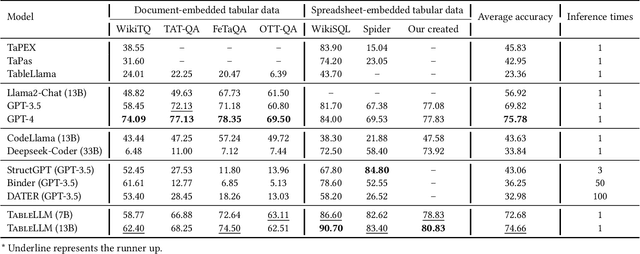
We introduce TableLLM, a robust large language model (LLM) with 13 billion parameters, purpose-built for proficiently handling tabular data manipulation tasks, whether they are embedded within documents or spreadsheets, catering to real-world office scenarios. We propose a distant supervision method for training, which comprises a reasoning process extension strategy, aiding in training LLMs to understand reasoning patterns more effectively as well as a cross-way validation strategy, ensuring the quality of the automatically generated data. To evaluate the performance of TableLLM, we have crafted a benchmark tailored to address both document and spreadsheet formats as well as constructed a well-organized evaluation pipeline capable of handling both scenarios. Thorough evaluations underscore the advantages of TableLLM when compared to various existing general-purpose and tabular data-focused LLMs. We have publicly released the model checkpoint, source code, benchmarks, and a web application for user interaction.Our codes and data are publicly available at https://github.com/TableLLM/TableLLM.
Adaptive Semantic-Enhanced Denoising Diffusion Probabilistic Model for Remote Sensing Image Super-Resolution
Mar 17, 2024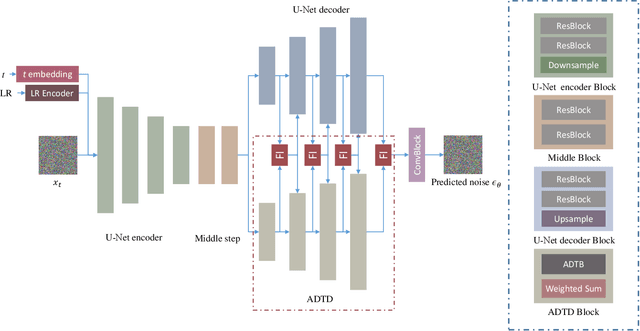
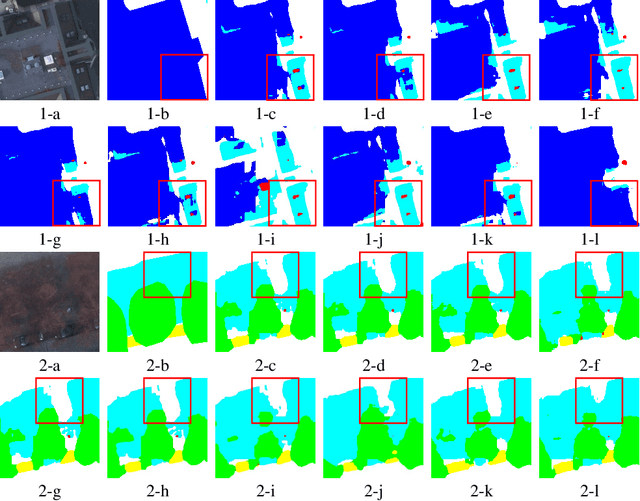
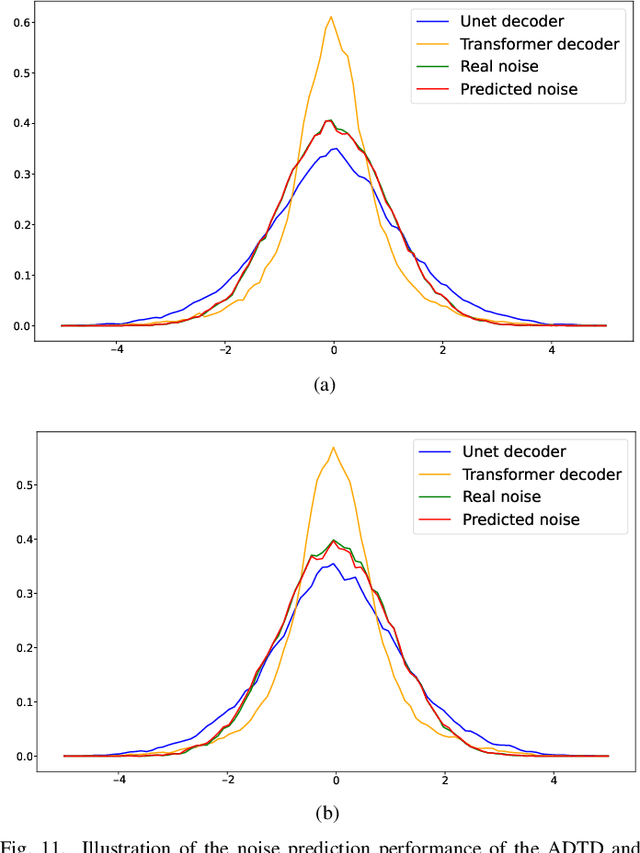
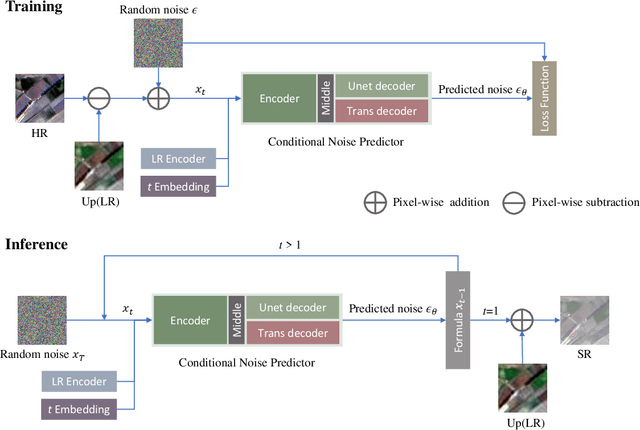
Remote sensing image super-resolution (SR) is a crucial task to restore high-resolution (HR) images from low-resolution (LR) observations. Recently, the Denoising Diffusion Probabilistic Model (DDPM) has shown promising performance in image reconstructions by overcoming problems inherent in generative models, such as over-smoothing and mode collapse. However, the high-frequency details generated by DDPM often suffer from misalignment with HR images due to the model's tendency to overlook long-range semantic contexts. This is attributed to the widely used U-Net decoder in the conditional noise predictor, which tends to overemphasize local information, leading to the generation of noises with significant variances during the prediction process. To address these issues, an adaptive semantic-enhanced DDPM (ASDDPM) is proposed to enhance the detail-preserving capability of the DDPM by incorporating low-frequency semantic information provided by the Transformer. Specifically, a novel adaptive diffusion Transformer decoder (ADTD) is developed to bridge the semantic gap between the encoder and decoder through regulating the noise prediction with the global contextual relationships and long-range dependencies in the diffusion process. Additionally, a residual feature fusion strategy establishes information exchange between the two decoders at multiple levels. As a result, the predicted noise generated by our approach closely approximates that of the real noise distribution.Extensive experiments on two SR and two semantic segmentation datasets confirm the superior performance of the proposed ASDDPM in both SR and the subsequent downstream applications. The source code will be available at https://github.com/littlebeen/ASDDPM-Adaptive-Semantic-Enhanced-DDPM.
Reverse That Number! Decoding Order Matters in Arithmetic Learning
Mar 09, 2024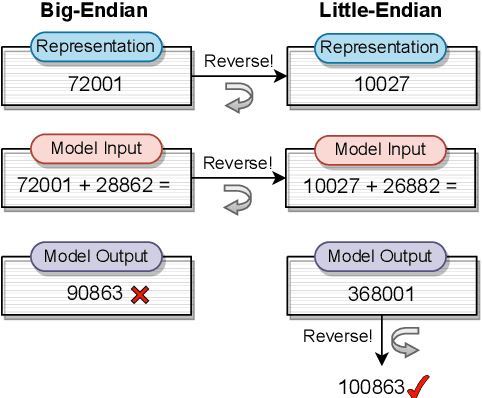

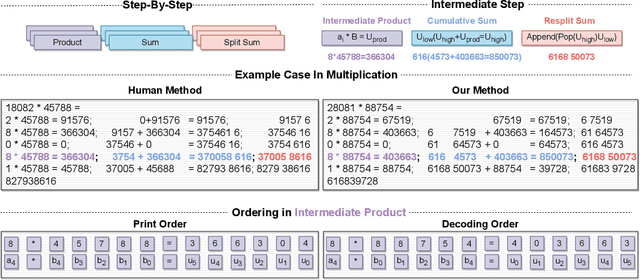
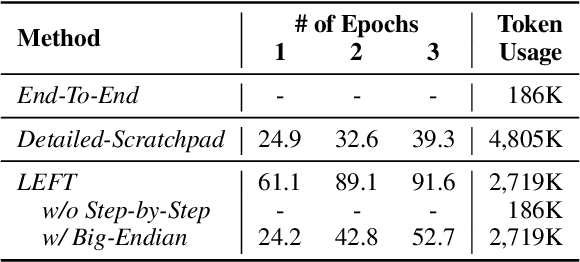
Recent advancements in pretraining have demonstrated that modern Large Language Models (LLMs) possess the capability to effectively learn arithmetic operations. However, despite acknowledging the significance of digit order in arithmetic computation, current methodologies predominantly rely on sequential, step-by-step approaches for teaching LLMs arithmetic, resulting in a conclusion where obtaining better performance involves fine-grained step-by-step. Diverging from this conventional path, our work introduces a novel strategy that not only reevaluates the digit order by prioritizing output from the least significant digit but also incorporates a step-by-step methodology to substantially reduce complexity. We have developed and applied this method in a comprehensive set of experiments. Compared to the previous state-of-the-art (SOTA) method, our findings reveal an overall improvement of in accuracy while requiring only a third of the tokens typically used during training. For the purpose of facilitating replication and further research, we have made our code and dataset publicly available at \url{https://anonymous.4open.science/r/RAIT-9FB7/}.
CodeS: Towards Building Open-source Language Models for Text-to-SQL
Feb 26, 2024Language models have shown promising performance on the task of translating natural language questions into SQL queries (Text-to-SQL). However, most of the state-of-the-art (SOTA) approaches rely on powerful yet closed-source large language models (LLMs), such as ChatGPT and GPT-4, which may have the limitations of unclear model architectures, data privacy risks, and expensive inference overheads. To address the limitations, we introduce CodeS, a series of pre-trained language models with parameters ranging from 1B to 15B, specifically designed for the text-to-SQL task. CodeS is a fully open-source language model, which achieves superior accuracy with much smaller parameter sizes. This paper studies the research challenges in building CodeS. To enhance the SQL generation abilities of CodeS, we adopt an incremental pre-training approach using a specifically curated SQL-centric corpus. Based on this, we address the challenges of schema linking and rapid domain adaptation through strategic prompt construction and a bi-directional data augmentation technique. We conduct comprehensive evaluations on multiple datasets, including the widely used Spider benchmark, the newly released BIRD benchmark, robustness-diagnostic benchmarks such as Spider-DK, Spider-Syn, Spider-Realistic, and Dr.Spider, as well as two real-world datasets created for financial and academic applications. The experimental results show that our CodeS achieves new SOTA accuracy and robustness on nearly all challenging text-to-SQL benchmarks.
Diffusion Enhancement for Cloud Removal in Ultra-Resolution Remote Sensing Imagery
Jan 25, 2024The presence of cloud layers severely compromises the quality and effectiveness of optical remote sensing (RS) images. However, existing deep-learning (DL)-based Cloud Removal (CR) techniques encounter difficulties in accurately reconstructing the original visual authenticity and detailed semantic content of the images. To tackle this challenge, this work proposes to encompass enhancements at the data and methodology fronts. On the data side, an ultra-resolution benchmark named CUHK Cloud Removal (CUHK-CR) of 0.5m spatial resolution is established. This benchmark incorporates rich detailed textures and diverse cloud coverage, serving as a robust foundation for designing and assessing CR models. From the methodology perspective, a novel diffusion-based framework for CR called Diffusion Enhancement (DE) is proposed to perform progressive texture detail recovery, which mitigates the training difficulty with improved inference accuracy. Additionally, a Weight Allocation (WA) network is developed to dynamically adjust the weights for feature fusion, thereby further improving performance, particularly in the context of ultra-resolution image generation. Furthermore, a coarse-to-fine training strategy is applied to effectively expedite training convergence while reducing the computational complexity required to handle ultra-resolution images. Extensive experiments on the newly established CUHK-CR and existing datasets such as RICE confirm that the proposed DE framework outperforms existing DL-based methods in terms of both perceptual quality and signal fidelity.
SAM-Assisted Remote Sensing Imagery Semantic Segmentation with Object and Boundary Constraints
Dec 05, 2023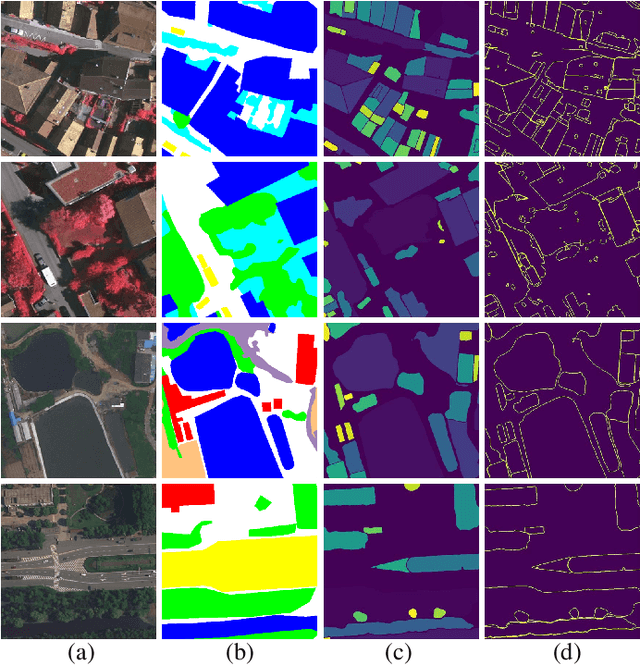
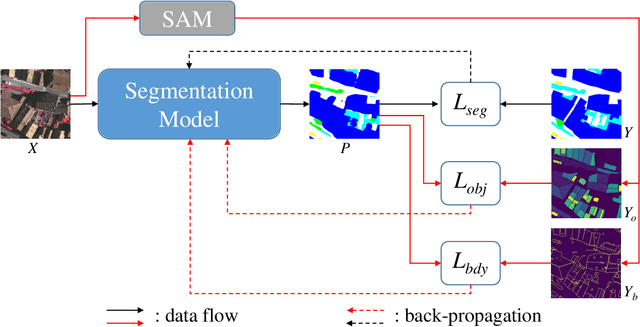


Semantic segmentation of remote sensing imagery plays a pivotal role in extracting precise information for diverse down-stream applications. Recent development of the Segment Anything Model (SAM), an advanced general-purpose segmentation model, has revolutionized this field, presenting new avenues for accurate and efficient segmentation. However, SAM is limited to generating segmentation results without class information. Consequently, the utilization of such a powerful general vision model for semantic segmentation in remote sensing images has become a focal point of research. In this paper, we present a streamlined framework aimed at leveraging the raw output of SAM by exploiting two novel concepts called SAM-Generated Object (SGO) and SAM-Generated Boundary (SGB). More specifically, we propose a novel object loss and further introduce a boundary loss as augmentative components to aid in model optimization in a general semantic segmentation framework. Taking into account the content characteristics of SGO, we introduce the concept of object consistency to leverage segmented regions lacking semantic information. By imposing constraints on the consistency of predicted values within objects, the object loss aims to enhance semantic segmentation performance. Furthermore, the boundary loss capitalizes on the distinctive features of SGB by directing the model's attention to the boundary information of the object. Experimental results on two well-known datasets, namely ISPRS Vaihingen and LoveDA Urban, demonstrate the effectiveness of our proposed method. The source code for this work will be accessible at https://github.com/sstary/SSRS.