 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZheyuan Zhang
PAM-UNet: Shifting Attention on Region of Interest in Medical Images
May 02, 2024
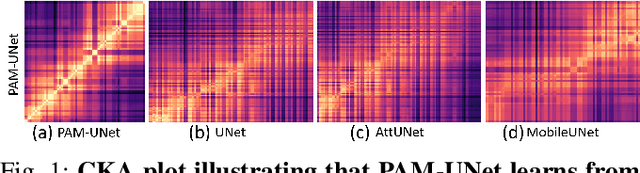
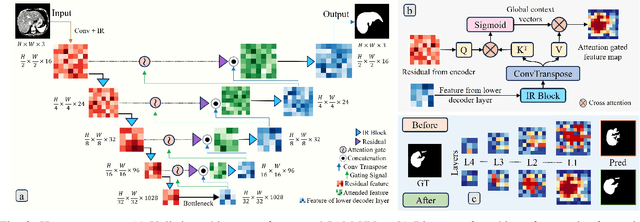
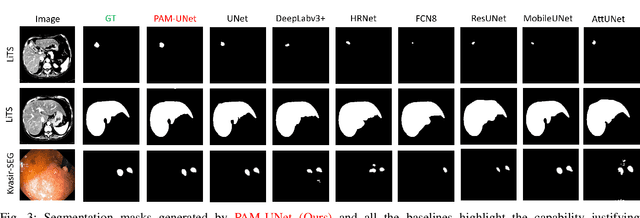

Computer-aided segmentation methods can assist medical personnel in improving diagnostic outcomes. While recent advancements like UNet and its variants have shown promise, they face a critical challenge: balancing accuracy with computational efficiency. Shallow encoder architectures in UNets often struggle to capture crucial spatial features, leading in inaccurate and sparse segmentation. To address this limitation, we propose a novel \underline{P}rogressive \underline{A}ttention based \underline{M}obile \underline{UNet} (\underline{PAM-UNet}) architecture. The inverted residual (IR) blocks in PAM-UNet help maintain a lightweight framework, while layerwise \textit{Progressive Luong Attention} ($\mathcal{PLA}$) promotes precise segmentation by directing attention toward regions of interest during synthesis. Our approach prioritizes both accuracy and speed, achieving a commendable balance with a mean IoU of 74.65 and a dice score of 82.87, while requiring only 1.32 floating-point operations per second (FLOPS) on the Liver Tumor Segmentation Benchmark (LiTS) 2017 dataset. These results highlight the importance of developing efficient segmentation models to accelerate the adoption of AI in clinical practice.
Segmentation Quality and Volumetric Accuracy in Medical Imaging
Apr 27, 2024Current medical image segmentation relies on the region-based (Dice, F1-score) and boundary-based (Hausdorff distance, surface distance) metrics as the de-facto standard. While these metrics are widely used, they lack a unified interpretation, particularly regarding volume agreement. Clinicians often lack clear benchmarks to gauge the "goodness" of segmentation results based on these metrics. Recognizing the clinical relevance of volumetry, we utilize relative volume prediction error (vpe) to directly assess the accuracy of volume predictions derived from segmentation tasks. Our work integrates theoretical analysis and empirical validation across diverse datasets. We delve into the often-ambiguous relationship between segmentation quality (measured by Dice) and volumetric accuracy in clinical practice. Our findings highlight the critical role of incorporating volumetric prediction accuracy into segmentation evaluation. This approach empowers clinicians with a more nuanced understanding of segmentation performance, ultimately improving the interpretation and utility of these metrics in real-world healthcare settings.
Detection of Peri-Pancreatic Edema using Deep Learning and Radiomics Techniques
Apr 25, 2024Identifying peri-pancreatic edema is a pivotal indicator for identifying disease progression and prognosis, emphasizing the critical need for accurate detection and assessment in pancreatitis diagnosis and management. This study \textit{introduces a novel CT dataset sourced from 255 patients with pancreatic diseases, featuring annotated pancreas segmentation masks and corresponding diagnostic labels for peri-pancreatic edema condition}. With the novel dataset, we first evaluate the efficacy of the \textit{LinTransUNet} model, a linear Transformer based segmentation algorithm, to segment the pancreas accurately from CT imaging data. Then, we use segmented pancreas regions with two distinctive machine learning classifiers to identify existence of peri-pancreatic edema: deep learning-based models and a radiomics-based eXtreme Gradient Boosting (XGBoost). The LinTransUNet achieved promising results, with a dice coefficient of 80.85\%, and mIoU of 68.73\%. Among the nine benchmarked classification models for peri-pancreatic edema detection, \textit{Swin-Tiny} transformer model demonstrated the highest recall of $98.85 \pm 0.42$ and precision of $98.38\pm 0.17$. Comparatively, the radiomics-based XGBoost model achieved an accuracy of $79.61\pm4.04$ and recall of $91.05\pm3.28$, showcasing its potential as a supplementary diagnostic tool given its rapid processing speed and reduced training time. Our code is available \url{https://github.com/NUBagciLab/Peri-Pancreatic-Edema-Detection}.
COMBO: Compositional World Models for Embodied Multi-Agent Cooperation
Apr 16, 2024In this paper, we investigate the problem of embodied multi-agent cooperation, where decentralized agents must cooperate given only partial egocentric views of the world. To effectively plan in this setting, in contrast to learning world dynamics in a single-agent scenario, we must simulate world dynamics conditioned on an arbitrary number of agents' actions given only partial egocentric visual observations of the world. To address this issue of partial observability, we first train generative models to estimate the overall world state given partial egocentric observations. To enable accurate simulation of multiple sets of actions on this world state, we then propose to learn a compositional world model for multi-agent cooperation by factorizing the naturally composable joint actions of multiple agents and compositionally generating the video. By leveraging this compositional world model, in combination with Vision Language Models to infer the actions of other agents, we can use a tree search procedure to integrate these modules and facilitate online cooperative planning. To evaluate the efficacy of our methods, we create two challenging embodied multi-agent long-horizon cooperation tasks using the ThreeDWorld simulator and conduct experiments with 2-4 agents. The results show our compositional world model is effective and the framework enables the embodied agents to cooperate efficiently with different agents across various tasks and an arbitrary number of agents, showing the promising future of our proposed framework. More videos can be found at https://vis-www.cs.umass.edu/combo/.
Explainable Transformer Prototypes for Medical Diagnoses
Mar 11, 2024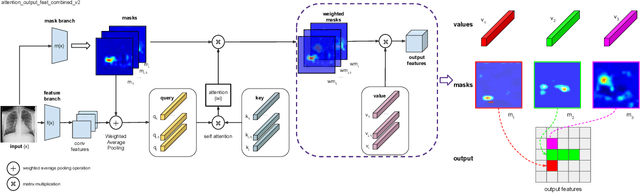
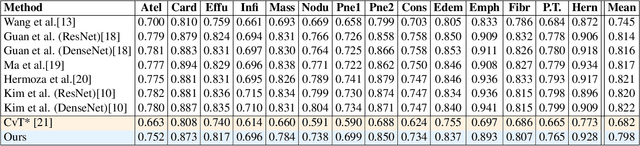
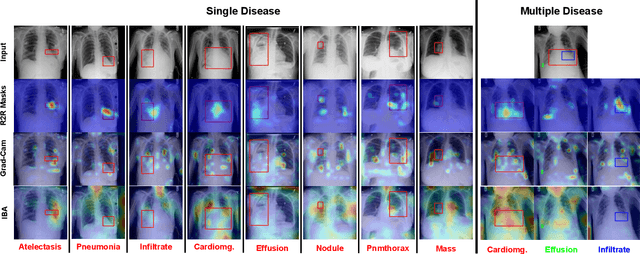
Deployments of artificial intelligence in medical diagnostics mandate not just accuracy and efficacy but also trust, emphasizing the need for explainability in machine decisions. The recent trend in automated medical image diagnostics leans towards the deployment of Transformer-based architectures, credited to their impressive capabilities. Since the self-attention feature of transformers contributes towards identifying crucial regions during the classification process, they enhance the trustability of the methods. However, the complex intricacies of these attention mechanisms may fall short of effectively pinpointing the regions of interest directly influencing AI decisions. Our research endeavors to innovate a unique attention block that underscores the correlation between 'regions' rather than 'pixels'. To address this challenge, we introduce an innovative system grounded in prototype learning, featuring an advanced self-attention mechanism that goes beyond conventional ad-hoc visual explanation techniques by offering comprehensible visual insights. A combined quantitative and qualitative methodological approach was used to demonstrate the effectiveness of the proposed method on the large-scale NIH chest X-ray dataset. Experimental results showed that our proposed method offers a promising direction for explainability, which can lead to the development of more trustable systems, which can facilitate easier and rapid adoption of such technology into routine clinics. The code is available at www.github.com/NUBagcilab/r2r_proto.
Reverse That Number! Decoding Order Matters in Arithmetic Learning
Mar 09, 2024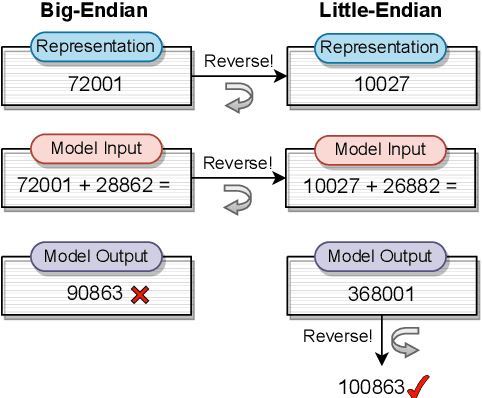

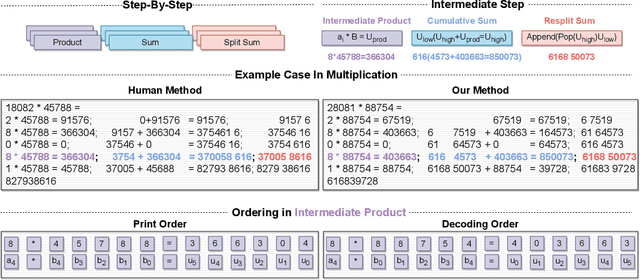
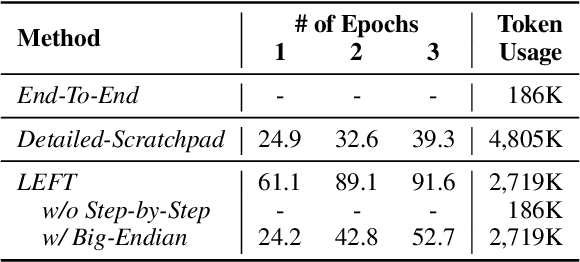
Recent advancements in pretraining have demonstrated that modern Large Language Models (LLMs) possess the capability to effectively learn arithmetic operations. However, despite acknowledging the significance of digit order in arithmetic computation, current methodologies predominantly rely on sequential, step-by-step approaches for teaching LLMs arithmetic, resulting in a conclusion where obtaining better performance involves fine-grained step-by-step. Diverging from this conventional path, our work introduces a novel strategy that not only reevaluates the digit order by prioritizing output from the least significant digit but also incorporates a step-by-step methodology to substantially reduce complexity. We have developed and applied this method in a comprehensive set of experiments. Compared to the previous state-of-the-art (SOTA) method, our findings reveal an overall improvement of in accuracy while requiring only a third of the tokens typically used during training. For the purpose of facilitating replication and further research, we have made our code and dataset publicly available at \url{https://anonymous.4open.science/r/RAIT-9FB7/}.
EmoBench: Evaluating the Emotional Intelligence of Large Language Models
Feb 19, 2024Recent advances in Large Language Models (LLMs) have highlighted the need for robust, comprehensive, and challenging benchmarks. Yet, research on evaluating their Emotional Intelligence (EI) is considerably limited. Existing benchmarks have two major shortcomings: first, they mainly focus on emotion recognition, neglecting essential EI capabilities such as emotion regulation and thought facilitation through emotion understanding; second, they are primarily constructed from existing datasets, which include frequent patterns, explicit information, and annotation errors, leading to unreliable evaluation. We propose EmoBench, a benchmark that draws upon established psychological theories and proposes a comprehensive definition for machine EI, including Emotional Understanding and Emotional Application. EmoBench includes a set of 400 hand-crafted questions in English and Chinese, which are meticulously designed to require thorough reasoning and understanding. Our findings reveal a considerable gap between the EI of existing LLMs and the average human, highlighting a promising direction for future research. Our code and data will be publicly available from https://github.com/Sahandfer/EmoBench.
Tackling Negative Transfer on Graphs
Feb 14, 2024Transfer learning aims to boost the learning on the target task leveraging knowledge learned from other relevant tasks. However, when the source and target are not closely related, the learning performance may be adversely affected, a phenomenon known as negative transfer. In this paper, we investigate the negative transfer in graph transfer learning, which is important yet underexplored. We reveal that, unlike image or text, negative transfer commonly occurs in graph-structured data, even when source and target graphs share semantic similarities. Specifically, we identify that structural differences significantly amplify the dissimilarities in the node embeddings across graphs. To mitigate this, we bring a new insight: for semantically similar graphs, although structural differences lead to significant distribution shift in node embeddings, their impact on subgraph embeddings could be marginal. Building on this insight, we introduce two effective yet elegant methods, Subgraph Pooling (SP) and Subgraph Pooling++ (SP++), that transfer subgraph-level knowledge across graphs. We theoretically analyze the role of SP in reducing graph discrepancy and conduct extensive experiments to evaluate its superiority under various settings. Our code and datasets are available at: https://github.com/Zehong-Wang/Subgraph-Pooling.
Graph Inference Acceleration by Learning MLPs on Graphs without Supervision
Feb 14, 2024Graph Neural Networks (GNNs) have demonstrated effectiveness in various graph learning tasks, yet their reliance on message-passing constraints their deployment in latency-sensitive applications such as financial fraud detection. Recent works have explored distilling knowledge from GNNs to Multi-Layer Perceptrons (MLPs) to accelerate inference. However, this task-specific supervised distillation limits generalization to unseen nodes, which are prevalent in latency-sensitive applications. To this end, we present \textbf{\textsc{SimMLP}}, a \textbf{\textsc{Sim}}ple yet effective framework for learning \textbf{\textsc{MLP}}s on graphs without supervision, to enhance generalization. \textsc{SimMLP} employs self-supervised alignment between GNNs and MLPs to capture the fine-grained and generalizable correlation between node features and graph structures, and proposes two strategies to alleviate the risk of trivial solutions. Theoretically, we comprehensively analyze \textsc{SimMLP} to demonstrate its equivalence to GNNs in the optimal case and its generalization capability. Empirically, \textsc{SimMLP} outperforms state-of-the-art baselines, especially in settings with unseen nodes. In particular, it obtains significant performance gains {\bf (7$\sim$26\%)} over MLPs and inference acceleration over GNNs {\bf (90$\sim$126$\times$)} on large-scale graph datasets. Our codes are available at: \url{https://github.com/Zehong-Wang/SimMLP}.
Efficient In-Context Learning in Vision-Language Models for Egocentric Videos
Nov 29, 2023Recent advancements in text-only large language models (LLMs) have highlighted the benefit of in-context learning for adapting to new tasks with a few demonstrations. However, extending in-context learning to large vision-language models (VLMs) using a huge amount of naturalistic vision-language data has shown limited success, particularly for egocentric videos, due to high data collection costs. We propose a novel training method $\mathbb{E}$fficient $\mathbb{I}$n-context $\mathbb{L}$earning on $\mathbb{E}$gocentric $\mathbb{V}$ideos ($\mathbb{EILEV}$), which elicits in-context learning in VLMs for egocentric videos without requiring massive, naturalistic egocentric video datasets. $\mathbb{EILEV}$ involves architectural and training data adaptations to allow the model to process contexts interleaved with video clips and narrations, sampling of in-context examples with clusters of similar verbs and nouns, use of data with skewed marginal distributions with a long tail of infrequent verbs and nouns, as well as homonyms and synonyms. Our evaluations show that $\mathbb{EILEV}$-trained models outperform larger VLMs trained on a huge amount of naturalistic data in in-context learning. Furthermore, they can generalize to not only out-of-distribution, but also novel, rare egocentric videos and texts via in-context learning, demonstrating potential for applications requiring cost-effective training, and rapid post-deployment adaptability. Our code and demo are available at \url{https://github.com/yukw777/EILEV}.