 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaniel Zhang-Li
TableLLM: Enabling Tabular Data Manipulation by LLMs in Real Office Usage Scenarios
Apr 01, 2024
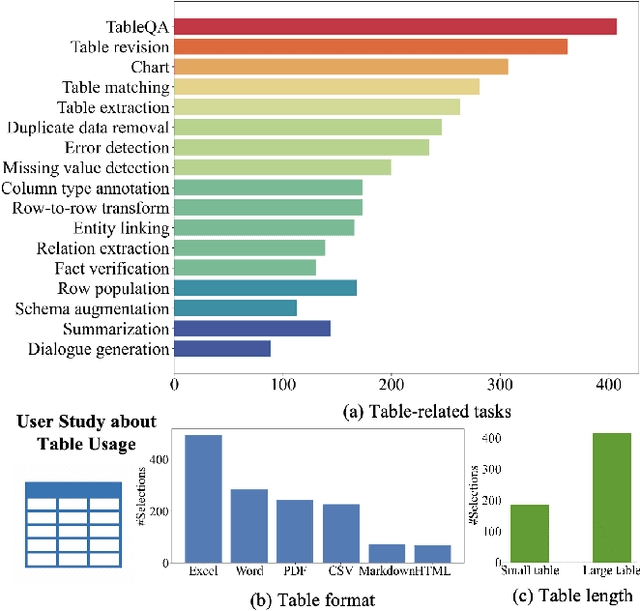

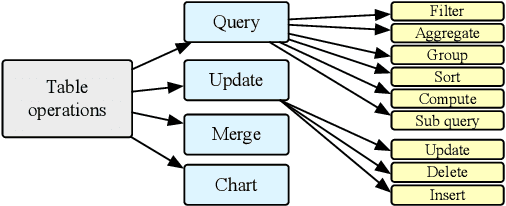
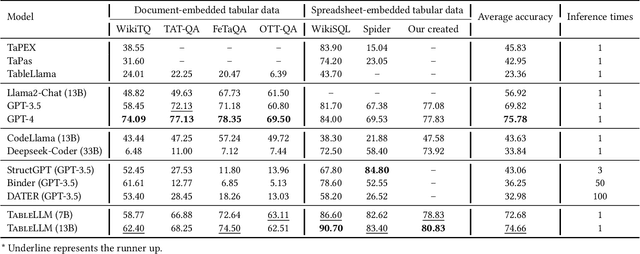
We introduce TableLLM, a robust large language model (LLM) with 13 billion parameters, purpose-built for proficiently handling tabular data manipulation tasks, whether they are embedded within documents or spreadsheets, catering to real-world office scenarios. We propose a distant supervision method for training, which comprises a reasoning process extension strategy, aiding in training LLMs to understand reasoning patterns more effectively as well as a cross-way validation strategy, ensuring the quality of the automatically generated data. To evaluate the performance of TableLLM, we have crafted a benchmark tailored to address both document and spreadsheet formats as well as constructed a well-organized evaluation pipeline capable of handling both scenarios. Thorough evaluations underscore the advantages of TableLLM when compared to various existing general-purpose and tabular data-focused LLMs. We have publicly released the model checkpoint, source code, benchmarks, and a web application for user interaction.Our codes and data are publicly available at https://github.com/TableLLM/TableLLM.
Reverse That Number! Decoding Order Matters in Arithmetic Learning
Mar 09, 2024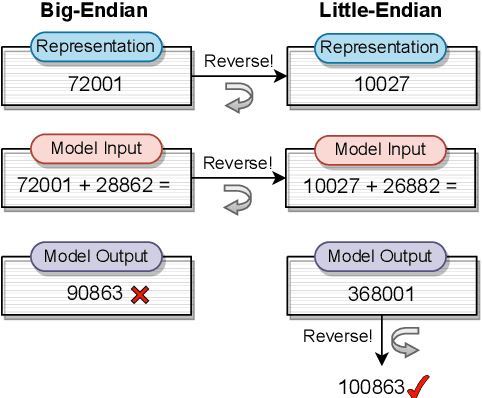

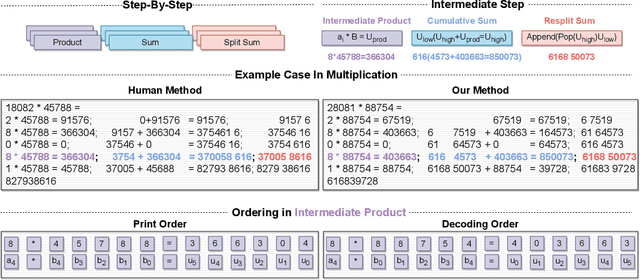
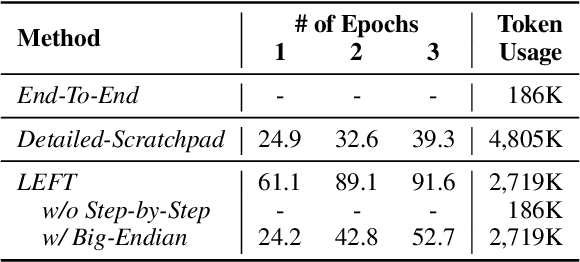
Recent advancements in pretraining have demonstrated that modern Large Language Models (LLMs) possess the capability to effectively learn arithmetic operations. However, despite acknowledging the significance of digit order in arithmetic computation, current methodologies predominantly rely on sequential, step-by-step approaches for teaching LLMs arithmetic, resulting in a conclusion where obtaining better performance involves fine-grained step-by-step. Diverging from this conventional path, our work introduces a novel strategy that not only reevaluates the digit order by prioritizing output from the least significant digit but also incorporates a step-by-step methodology to substantially reduce complexity. We have developed and applied this method in a comprehensive set of experiments. Compared to the previous state-of-the-art (SOTA) method, our findings reveal an overall improvement of in accuracy while requiring only a third of the tokens typically used during training. For the purpose of facilitating replication and further research, we have made our code and dataset publicly available at \url{https://anonymous.4open.science/r/RAIT-9FB7/}.
KoLA: Carefully Benchmarking World Knowledge of Large Language Models
Jun 15, 2023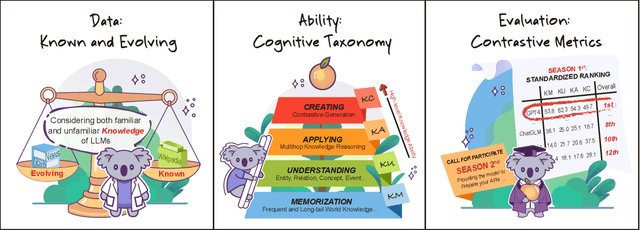
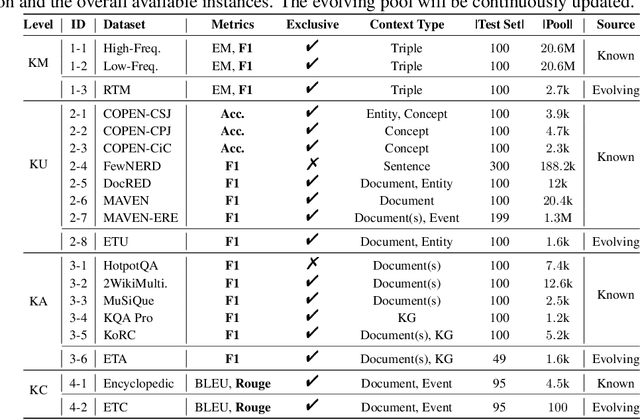

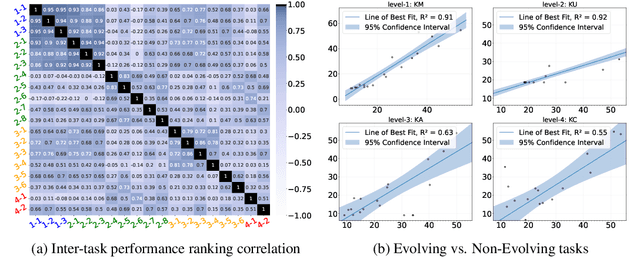
The unprecedented performance of large language models (LLMs) necessitates improvements in evaluations. Rather than merely exploring the breadth of LLM abilities, we believe meticulous and thoughtful designs are essential to thorough, unbiased, and applicable evaluations. Given the importance of world knowledge to LLMs, we construct a Knowledge-oriented LLM Assessment benchmark (KoLA), in which we carefully design three crucial factors: (1) For ability modeling, we mimic human cognition to form a four-level taxonomy of knowledge-related abilities, covering $19$ tasks. (2) For data, to ensure fair comparisons, we use both Wikipedia, a corpus prevalently pre-trained by LLMs, along with continuously collected emerging corpora, aiming to evaluate the capacity to handle unseen data and evolving knowledge. (3) For evaluation criteria, we adopt a contrastive system, including overall standard scores for better numerical comparability across tasks and models and a unique self-contrast metric for automatically evaluating knowledge hallucination. We evaluate $21$ open-source and commercial LLMs and obtain some intriguing findings. The KoLA dataset and open-participation leaderboard are publicly released at https://kola.xlore.cn and will be continuously updated to provide references for developing LLMs and knowledge-related systems.
GLM-Dialog: Noise-tolerant Pre-training for Knowledge-grounded Dialogue Generation
Feb 28, 2023
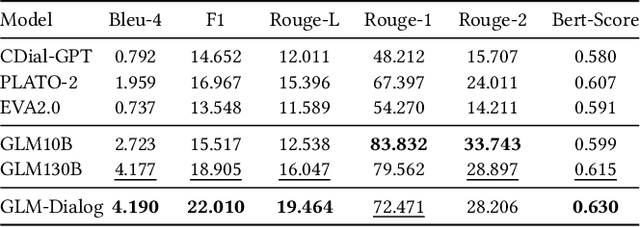

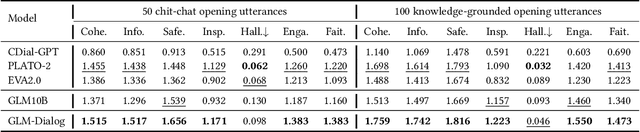
We present GLM-Dialog, a large-scale language model (LLM) with 10B parameters capable of knowledge-grounded conversation in Chinese using a search engine to access the Internet knowledge. GLM-Dialog offers a series of applicable techniques for exploiting various external knowledge including both helpful and noisy knowledge, enabling the creation of robust knowledge-grounded dialogue LLMs with limited proper datasets. To evaluate the GLM-Dialog more fairly, we also propose a novel evaluation method to allow humans to converse with multiple deployed bots simultaneously and compare their performance implicitly instead of explicitly rating using multidimensional metrics.Comprehensive evaluations from automatic to human perspective demonstrate the advantages of GLM-Dialog comparing with existing open source Chinese dialogue models. We release both the model checkpoint and source code, and also deploy it as a WeChat application to interact with users. We offer our evaluation platform online in an effort to prompt the development of open source models and reliable dialogue evaluation systems. The additional easy-to-use toolkit that consists of short text entity linking, query generation, and helpful knowledge classification is also released to enable diverse applications. All the source code is available on Github.