 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXin Lv
Untangle the KNOT: Interweaving Conflicting Knowledge and Reasoning Skills in Large Language Models
Apr 04, 2024
Providing knowledge documents for large language models (LLMs) has emerged as a promising solution to update the static knowledge inherent in their parameters. However, knowledge in the document may conflict with the memory of LLMs due to outdated or incorrect knowledge in the LLMs' parameters. This leads to the necessity of examining the capability of LLMs to assimilate supplemental external knowledge that conflicts with their memory. While previous studies have explained to what extent LLMs extract conflicting knowledge from the provided text, they neglect the necessity to reason with conflicting knowledge. Furthermore, there lack a detailed analysis on strategies to enable LLMs to resolve conflicting knowledge via prompting, decoding strategy, and supervised fine-tuning. To address these limitations, we construct a new dataset, dubbed KNOT, for knowledge conflict resolution examination in the form of question answering. KNOT facilitates in-depth analysis by dividing reasoning with conflicting knowledge into three levels: (1) Direct Extraction, which directly extracts conflicting knowledge to answer questions. (2) Explicit Reasoning, which reasons with conflicting knowledge when the reasoning path is explicitly provided in the question. (3) Implicit Reasoning, where reasoning with conflicting knowledge requires LLMs to infer the reasoning path independently to answer questions. We also conduct extensive experiments on KNOT to establish empirical guidelines for LLMs to utilize conflicting knowledge in complex circumstances. Dataset and associated codes can be accessed at https://github.com/THU-KEG/KNOT .
LongAlign: A Recipe for Long Context Alignment of Large Language Models
Jan 31, 2024Extending large language models to effectively handle long contexts requires instruction fine-tuning on input sequences of similar length. To address this, we present LongAlign -- a recipe of the instruction data, training, and evaluation for long context alignment. First, we construct a long instruction-following dataset using Self-Instruct. To ensure the data diversity, it covers a broad range of tasks from various long context sources. Second, we adopt the packing and sorted batching strategies to speed up supervised fine-tuning on data with varied length distributions. Additionally, we develop a loss weighting method to balance the contribution to the loss across different sequences during packing training. Third, we introduce the LongBench-Chat benchmark for evaluating instruction-following capabilities on queries of 10k-100k in length. Experiments show that LongAlign outperforms existing recipes for LLMs in long context tasks by up to 30\%, while also maintaining their proficiency in handling short, generic tasks. The code, data, and long-aligned models are open-sourced at https://github.com/THUDM/LongAlign.
Probabilistic Tree-of-thought Reasoning for Answering Knowledge-intensive Complex Questions
Nov 23, 2023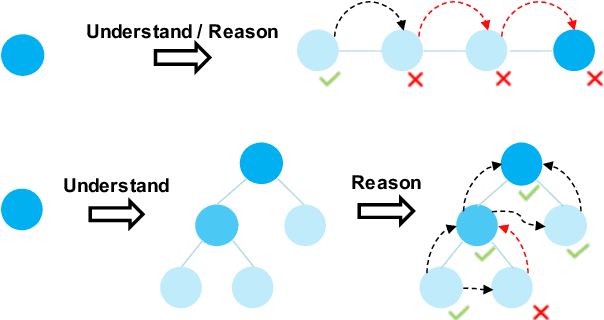
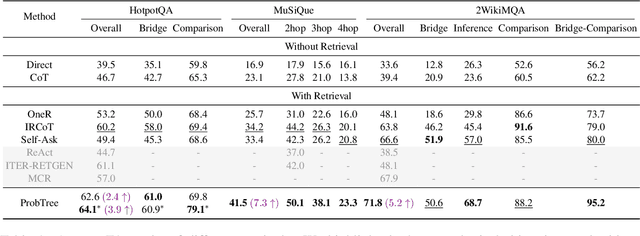

Large language models (LLMs) are capable of answering knowledge-intensive complex questions with chain-of-thought (CoT) reasoning. However, they tend to generate factually incorrect reasoning steps when the required knowledge is not available or up-to-date in models' parameters. Recent works turn to retrieving external knowledge to augment CoT reasoning. Despite being promising, these chain-based methods suffer from: 1) Negative retrieval. Unnecessary or incorrect retrieval may mislead the reasoning; 2) Limited sight. Lacking the ability to look backward or forward, a local error in one step will propagate along the chain. In this paper, we propose a novel approach: Probabilistic Tree-of-thought Reasoning (ProbTree). First, LLMs translate a complex question into a query tree, in which each non-root node denotes a sub-question of its parent node. Then, probabilistic reasoning is conducted over the tree, by solving questions from leaf to root considering the confidence of both question decomposing and answering. During reasoning, for leaf nodes, LLMs choose a more confident answer from Closed-book QA that employs parametric knowledge and Open-book QA that employs retrieved external knowledge, thus eliminating the negative retrieval problem. For non-leaf nodes, with the hierarchical structure, LLMs have broader sights and are able to globally reason with the information from child nodes, thus recovering from local errors. The experiments on three Complex QA datasets under the open-domain setting show that our approach outperforms SOTA methods significantly, demonstrating the effect of probabilistic tree-of-thought reasoning.
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Aug 28, 2023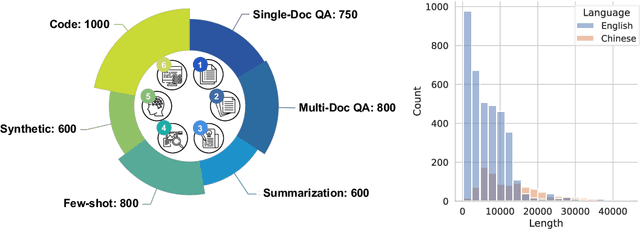
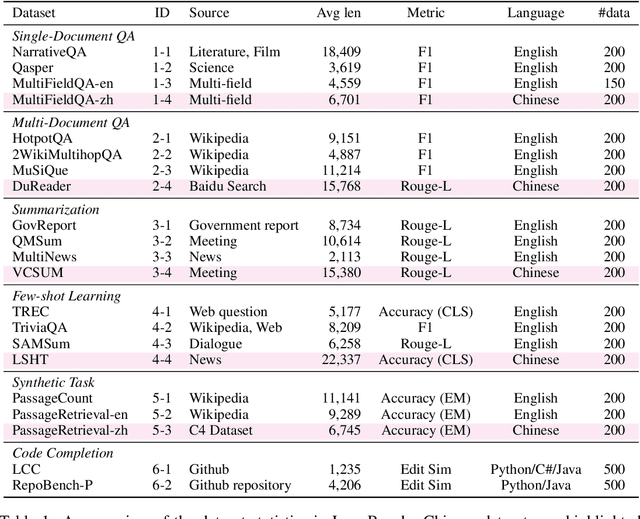
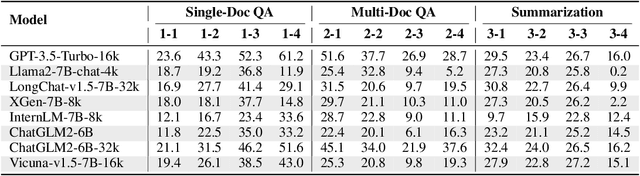
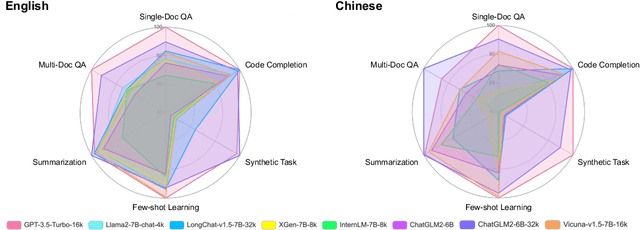
Although large language models (LLMs) demonstrate impressive performance for many language tasks, most of them can only handle texts a few thousand tokens long, limiting their applications on longer sequence inputs, such as books, reports, and codebases. Recent works have proposed methods to improve LLMs' long context capabilities by extending context windows and more sophisticated memory mechanisms. However, comprehensive benchmarks tailored for evaluating long context understanding are lacking. In this paper, we introduce LongBench, the first bilingual, multi-task benchmark for long context understanding, enabling a more rigorous evaluation of long context understanding. LongBench comprises 21 datasets across 6 task categories in both English and Chinese, with an average length of 6,711 words (English) and 13,386 characters (Chinese). These tasks cover key long-text application areas including single-doc QA, multi-doc QA, summarization, few-shot learning, synthetic tasks, and code completion. All datasets in LongBench are standardized into a unified format, allowing for effortless automatic evaluation of LLMs. Upon comprehensive evaluation of 8 LLMs on LongBench, we find that: (1) Commercial model (GPT-3.5-Turbo-16k) outperforms other open-sourced models, but still struggles on longer contexts. (2) Scaled position embedding and fine-tuning on longer sequences lead to substantial improvement on long context understanding. (3) Context compression technique such as retrieval brings improvement for model with weak ability on long contexts, but the performance still lags behind models that have strong long context understanding capability. The code and datasets are available at https://github.com/THUDM/LongBench.
VisKoP: Visual Knowledge oriented Programming for Interactive Knowledge Base Question Answering
Jul 06, 2023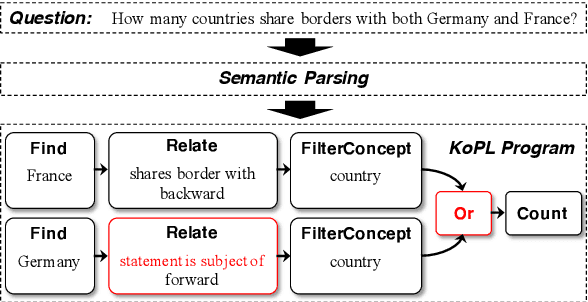

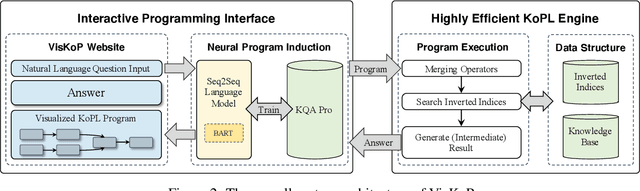

We present Visual Knowledge oriented Programming platform (VisKoP), a knowledge base question answering (KBQA) system that integrates human into the loop to edit and debug the knowledge base (KB) queries. VisKoP not only provides a neural program induction module, which converts natural language questions into knowledge oriented program language (KoPL), but also maps KoPL programs into graphical elements. KoPL programs can be edited with simple graphical operators, such as dragging to add knowledge operators and slot filling to designate operator arguments. Moreover, VisKoP provides auto-completion for its knowledge base schema and users can easily debug the KoPL program by checking its intermediate results. To facilitate the practical KBQA on a million-entity-level KB, we design a highly efficient KoPL execution engine for the back-end. Experiment results show that VisKoP is highly efficient and user interaction can fix a large portion of wrong KoPL programs to acquire the correct answer. The VisKoP online demo https://demoviskop.xlore.cn (Stable release of this paper) and https://viskop.xlore.cn (Beta release with new features), highly efficient KoPL engine https://pypi.org/project/kopl-engine, and screencast video https://youtu.be/zAbJtxFPTXo are now publicly available.
KoRC: Knowledge oriented Reading Comprehension Benchmark for Deep Text Understanding
Jul 06, 2023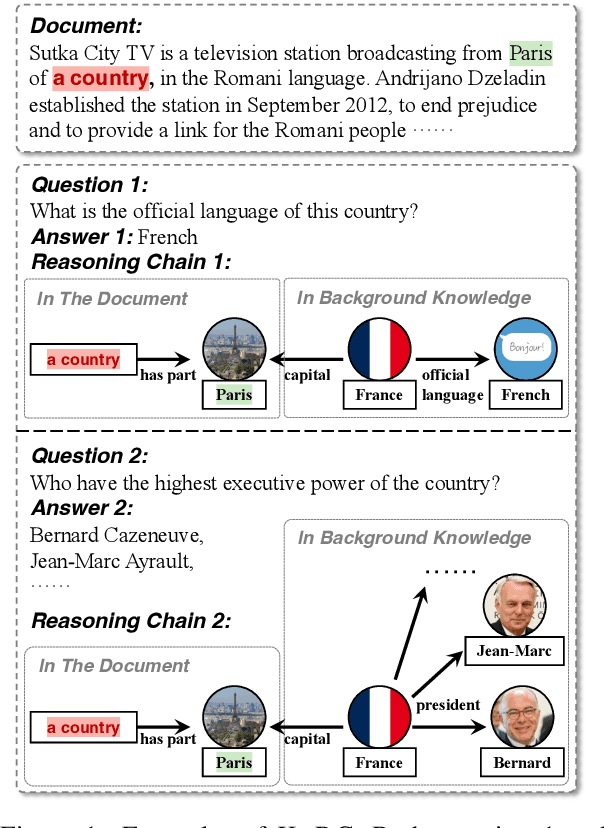

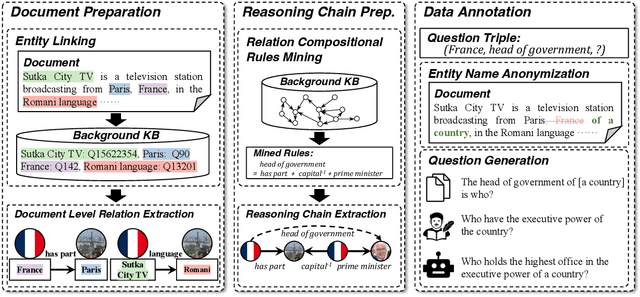
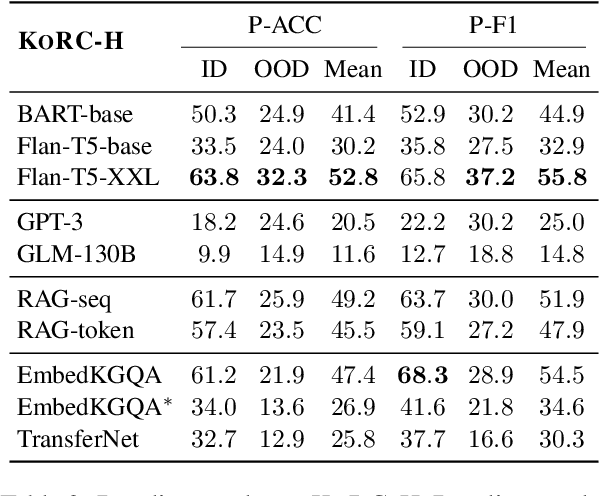
Deep text understanding, which requires the connections between a given document and prior knowledge beyond its text, has been highlighted by many benchmarks in recent years. However, these benchmarks have encountered two major limitations. On the one hand, most of them require human annotation of knowledge, which leads to limited knowledge coverage. On the other hand, they usually use choices or spans in the texts as the answers, which results in narrow answer space. To overcome these limitations, we build a new challenging benchmark named KoRc in this paper. Compared with previous benchmarks, KoRC has two advantages, i.e., broad knowledge coverage and flexible answer format. Specifically, we utilize massive knowledge bases to guide annotators or large language models (LLMs) to construct knowledgable questions. Moreover, we use labels in knowledge bases rather than spans or choices as the final answers. We test state-of-the-art models on KoRC and the experimental results show that the strongest baseline only achieves 68.3% and 30.0% F1 measure in the in-distribution and out-of-distribution test set, respectively. These results indicate that deep text understanding is still an unsolved challenge. The benchmark dataset, leaderboard, and baseline methods are released in https://github.com/THU-KEG/KoRC.
KoLA: Carefully Benchmarking World Knowledge of Large Language Models
Jun 15, 2023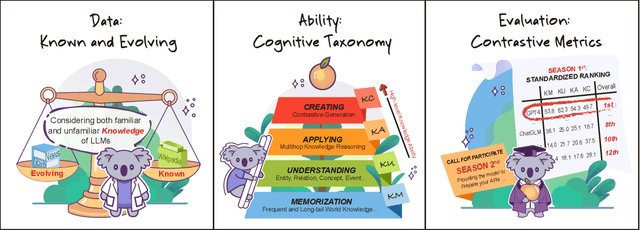
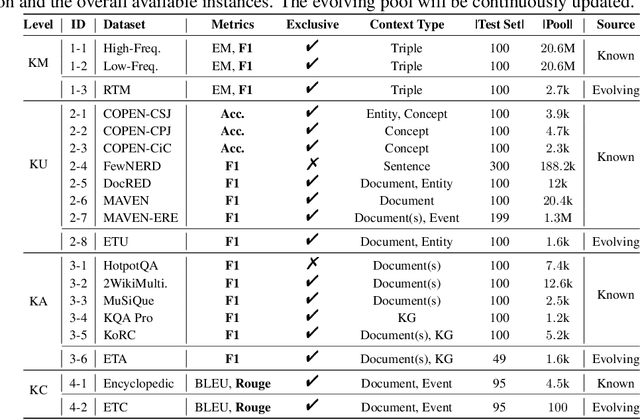

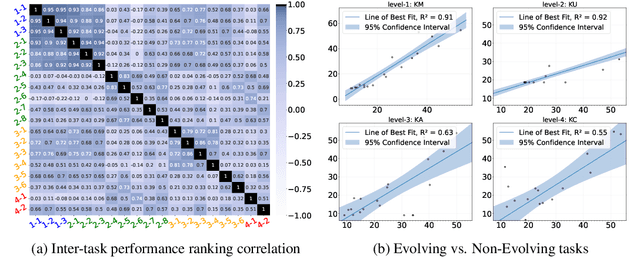
The unprecedented performance of large language models (LLMs) necessitates improvements in evaluations. Rather than merely exploring the breadth of LLM abilities, we believe meticulous and thoughtful designs are essential to thorough, unbiased, and applicable evaluations. Given the importance of world knowledge to LLMs, we construct a Knowledge-oriented LLM Assessment benchmark (KoLA), in which we carefully design three crucial factors: (1) For ability modeling, we mimic human cognition to form a four-level taxonomy of knowledge-related abilities, covering $19$ tasks. (2) For data, to ensure fair comparisons, we use both Wikipedia, a corpus prevalently pre-trained by LLMs, along with continuously collected emerging corpora, aiming to evaluate the capacity to handle unseen data and evolving knowledge. (3) For evaluation criteria, we adopt a contrastive system, including overall standard scores for better numerical comparability across tasks and models and a unique self-contrast metric for automatically evaluating knowledge hallucination. We evaluate $21$ open-source and commercial LLMs and obtain some intriguing findings. The KoLA dataset and open-participation leaderboard are publicly released at https://kola.xlore.cn and will be continuously updated to provide references for developing LLMs and knowledge-related systems.
Benchmarking Foundation Models with Language-Model-as-an-Examiner
Jun 07, 2023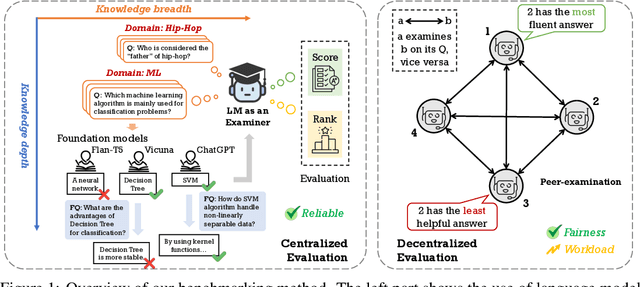

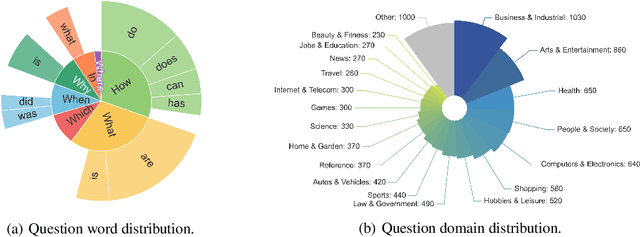
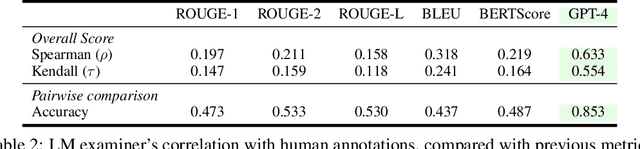
Numerous benchmarks have been established to assess the performance of foundation models on open-ended question answering, which serves as a comprehensive test of a model's ability to understand and generate language in a manner similar to humans. Most of these works focus on proposing new datasets, however, we see two main issues within previous benchmarking pipelines, namely testing leakage and evaluation automation. In this paper, we propose a novel benchmarking framework, Language-Model-as-an-Examiner, where the LM serves as a knowledgeable examiner that formulates questions based on its knowledge and evaluates responses in a reference-free manner. Our framework allows for effortless extensibility as various LMs can be adopted as the examiner, and the questions can be constantly updated given more diverse trigger topics. For a more comprehensive and equitable evaluation, we devise three strategies: (1) We instruct the LM examiner to generate questions across a multitude of domains to probe for a broad acquisition, and raise follow-up questions to engage in a more in-depth assessment. (2) Upon evaluation, the examiner combines both scoring and ranking measurements, providing a reliable result as it aligns closely with human annotations. (3) We additionally propose a decentralized Peer-examination method to address the biases in a single examiner. Our data and benchmarking results are available at: https://lmexam.com.
Reasoning over Hierarchical Question Decomposition Tree for Explainable Question Answering
May 24, 2023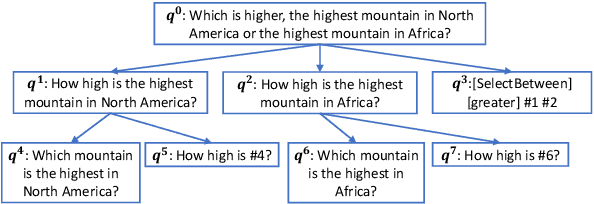
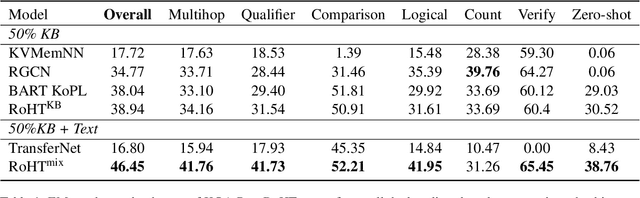
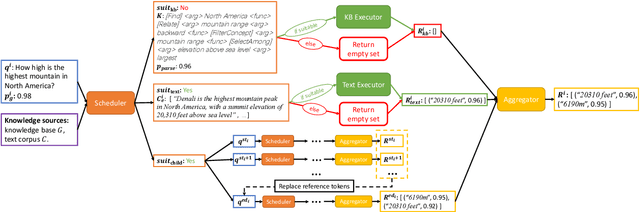
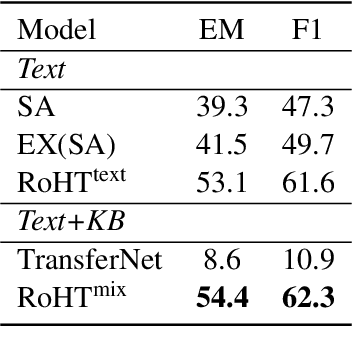
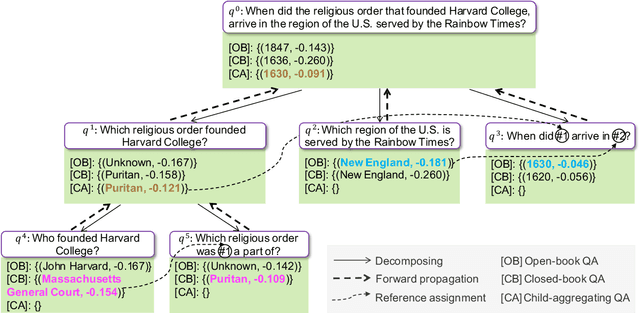
Explainable question answering (XQA) aims to answer a given question and provide an explanation why the answer is selected. Existing XQA methods focus on reasoning on a single knowledge source, e.g., structured knowledge bases, unstructured corpora, etc. However, integrating information from heterogeneous knowledge sources is essential to answer complex questions. In this paper, we propose to leverage question decomposing for heterogeneous knowledge integration, by breaking down a complex question into simpler ones, and selecting the appropriate knowledge source for each sub-question. To facilitate reasoning, we propose a novel two-stage XQA framework, Reasoning over Hierarchical Question Decomposition Tree (RoHT). First, we build the Hierarchical Question Decomposition Tree (HQDT) to understand the semantics of a complex question; then, we conduct probabilistic reasoning over HQDT from root to leaves recursively, to aggregate heterogeneous knowledge at different tree levels and search for a best solution considering the decomposing and answering probabilities. The experiments on complex QA datasets KQA Pro and Musique show that our framework outperforms SOTA methods significantly, demonstrating the effectiveness of leveraging question decomposing for knowledge integration and our RoHT framework.
Answering Complex Logical Queries on Knowledge Graphs via Query Computation Tree Optimization
Dec 21, 2022
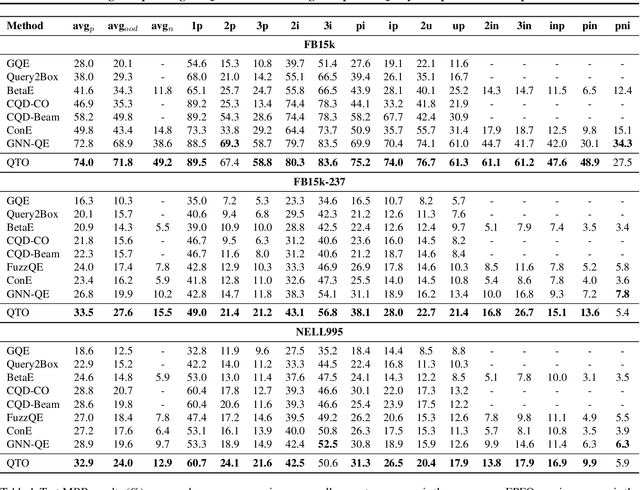

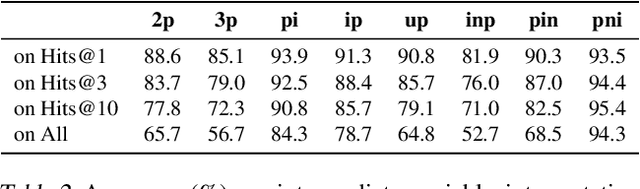
Answering complex logical queries on incomplete knowledge graphs is a challenging task, and has been widely studied. Embedding-based methods require training on complex queries, and cannot generalize well to out-of-distribution query structures. Recent work frames this task as an end-to-end optimization problem, and it only requires a pretrained link predictor. However, due to the exponentially large combinatorial search space, the optimal solution can only be approximated, limiting the final accuracy. In this work, we propose QTO (Query Computation Tree Optimization) that can efficiently find the exact optimal solution. QTO finds the optimal solution by a forward-backward propagation on the tree-like computation graph, i.e., query computation tree. In particular, QTO utilizes the independence encoded in the query computation tree to reduce the search space, where only local computations are involved during the optimization procedure. Experiments on 3 datasets show that QTO obtains state-of-the-art performance on complex query answering, outperforming previous best results by an average of 22%. Moreover, QTO can interpret the intermediate solutions for each of the one-hop atoms in the query with over 90% accuracy.