 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYury Velichko
Analysis of the BraTS 2023 Intracranial Meningioma Segmentation Challenge
May 16, 2024
We describe the design and results from the BraTS 2023 Intracranial Meningioma Segmentation Challenge. The BraTS Meningioma Challenge differed from prior BraTS Glioma challenges in that it focused on meningiomas, which are typically benign extra-axial tumors with diverse radiologic and anatomical presentation and a propensity for multiplicity. Nine participating teams each developed deep-learning automated segmentation models using image data from the largest multi-institutional systematically expert annotated multilabel multi-sequence meningioma MRI dataset to date, which included 1000 training set cases, 141 validation set cases, and 283 hidden test set cases. Each case included T2, T2/FLAIR, T1, and T1Gd brain MRI sequences with associated tumor compartment labels delineating enhancing tumor, non-enhancing tumor, and surrounding non-enhancing T2/FLAIR hyperintensity. Participant automated segmentation models were evaluated and ranked based on a scoring system evaluating lesion-wise metrics including dice similarity coefficient (DSC) and 95% Hausdorff Distance. The top ranked team had a lesion-wise median dice similarity coefficient (DSC) of 0.976, 0.976, and 0.964 for enhancing tumor, tumor core, and whole tumor, respectively and a corresponding average DSC of 0.899, 0.904, and 0.871, respectively. These results serve as state-of-the-art benchmarks for future pre-operative meningioma automated segmentation algorithms. Additionally, we found that 1286 of 1424 cases (90.3%) had at least 1 compartment voxel abutting the edge of the skull-stripped image edge, which requires further investigation into optimal pre-processing face anonymization steps.
MDNet: Multi-Decoder Network for Abdominal CT Organs Segmentation
May 10, 2024Accurate segmentation of organs from abdominal CT scans is essential for clinical applications such as diagnosis, treatment planning, and patient monitoring. To handle challenges of heterogeneity in organ shapes, sizes, and complex anatomical relationships, we propose a \textbf{\textit{\ac{MDNet}}}, an encoder-decoder network that uses the pre-trained \textit{MiT-B2} as the encoder and multiple different decoder networks. Each decoder network is connected to a different part of the encoder via a multi-scale feature enhancement dilated block. With each decoder, we increase the depth of the network iteratively and refine segmentation masks, enriching feature maps by integrating previous decoders' feature maps. To refine the feature map further, we also utilize the predicted masks from the previous decoder to the current decoder to provide spatial attention across foreground and background regions. MDNet effectively refines the segmentation mask with a high dice similarity coefficient (DSC) of 0.9013 and 0.9169 on the Liver Tumor segmentation (LiTS) and MSD Spleen datasets. Additionally, it reduces Hausdorff distance (HD) to 3.79 for the LiTS dataset and 2.26 for the spleen segmentation dataset, underscoring the precision of MDNet in capturing the complex contours. Moreover, \textit{\ac{MDNet}} is more interpretable and robust compared to the other baseline models.
PAM-UNet: Shifting Attention on Region of Interest in Medical Images
May 02, 2024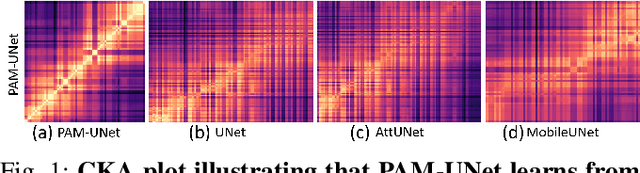
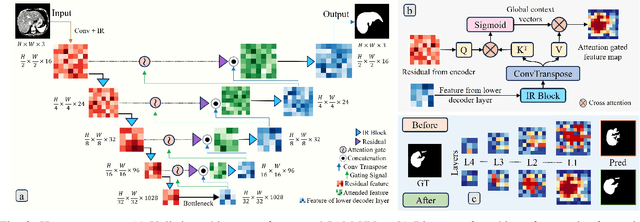
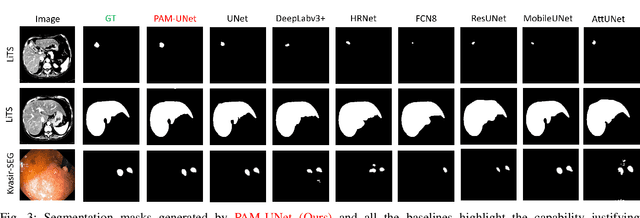

Computer-aided segmentation methods can assist medical personnel in improving diagnostic outcomes. While recent advancements like UNet and its variants have shown promise, they face a critical challenge: balancing accuracy with computational efficiency. Shallow encoder architectures in UNets often struggle to capture crucial spatial features, leading in inaccurate and sparse segmentation. To address this limitation, we propose a novel \underline{P}rogressive \underline{A}ttention based \underline{M}obile \underline{UNet} (\underline{PAM-UNet}) architecture. The inverted residual (IR) blocks in PAM-UNet help maintain a lightweight framework, while layerwise \textit{Progressive Luong Attention} ($\mathcal{PLA}$) promotes precise segmentation by directing attention toward regions of interest during synthesis. Our approach prioritizes both accuracy and speed, achieving a commendable balance with a mean IoU of 74.65 and a dice score of 82.87, while requiring only 1.32 floating-point operations per second (FLOPS) on the Liver Tumor Segmentation Benchmark (LiTS) 2017 dataset. These results highlight the importance of developing efficient segmentation models to accelerate the adoption of AI in clinical practice.
Detection of Peri-Pancreatic Edema using Deep Learning and Radiomics Techniques
Apr 25, 2024Identifying peri-pancreatic edema is a pivotal indicator for identifying disease progression and prognosis, emphasizing the critical need for accurate detection and assessment in pancreatitis diagnosis and management. This study \textit{introduces a novel CT dataset sourced from 255 patients with pancreatic diseases, featuring annotated pancreas segmentation masks and corresponding diagnostic labels for peri-pancreatic edema condition}. With the novel dataset, we first evaluate the efficacy of the \textit{LinTransUNet} model, a linear Transformer based segmentation algorithm, to segment the pancreas accurately from CT imaging data. Then, we use segmented pancreas regions with two distinctive machine learning classifiers to identify existence of peri-pancreatic edema: deep learning-based models and a radiomics-based eXtreme Gradient Boosting (XGBoost). The LinTransUNet achieved promising results, with a dice coefficient of 80.85\%, and mIoU of 68.73\%. Among the nine benchmarked classification models for peri-pancreatic edema detection, \textit{Swin-Tiny} transformer model demonstrated the highest recall of $98.85 \pm 0.42$ and precision of $98.38\pm 0.17$. Comparatively, the radiomics-based XGBoost model achieved an accuracy of $79.61\pm4.04$ and recall of $91.05\pm3.28$, showcasing its potential as a supplementary diagnostic tool given its rapid processing speed and reduced training time. Our code is available \url{https://github.com/NUBagciLab/Peri-Pancreatic-Edema-Detection}.
A Probabilistic Hadamard U-Net for MRI Bias Field Correction
Mar 08, 2024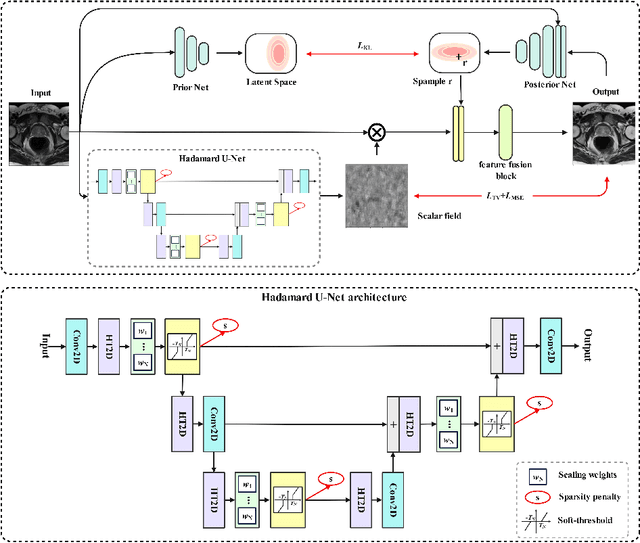
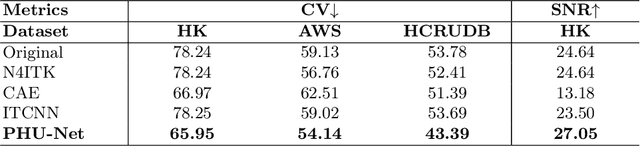
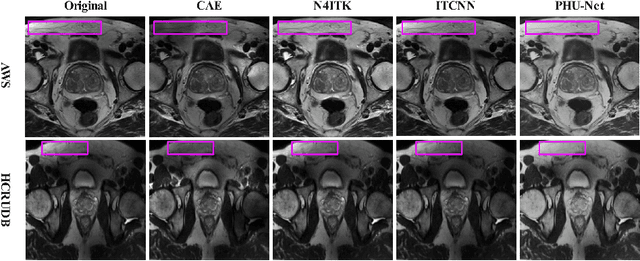
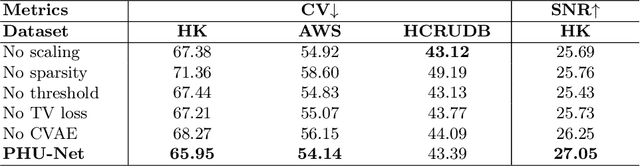
Magnetic field inhomogeneity correction remains a challenging task in MRI analysis. Most established techniques are designed for brain MRI by supposing that image intensities in the identical tissue follow a uniform distribution. Such an assumption cannot be easily applied to other organs, especially those that are small in size and heterogeneous in texture (large variations in intensity), such as the prostate. To address this problem, this paper proposes a probabilistic Hadamard U-Net (PHU-Net) for prostate MRI bias field correction. First, a novel Hadamard U-Net (HU-Net) is introduced to extract the low-frequency scalar field, multiplied by the original input to obtain the prototypical corrected image. HU-Net converts the input image from the time domain into the frequency domain via Hadamard transform. In the frequency domain, high-frequency components are eliminated using the trainable filter (scaling layer), hard-thresholding layer, and sparsity penalty. Next, a conditional variational autoencoder is used to encode possible bias field-corrected variants into a low-dimensional latent space. Random samples drawn from latent space are then incorporated with a prototypical corrected image to generate multiple plausible images. Experimental results demonstrate the effectiveness of PHU-Net in correcting bias-field in prostate MRI with a fast inference speed. It has also been shown that prostate MRI segmentation accuracy improves with the high-quality corrected images from PHU-Net. The code will be available in the final version of this manuscript.
CT Liver Segmentation via PVT-based Encoding and Refined Decoding
Jan 17, 2024Accurate liver segmentation from CT scans is essential for computer-aided diagnosis and treatment planning. Recently, Vision Transformers achieved a competitive performance in computer vision tasks compared to convolutional neural networks due to their exceptional ability to learn global representations. However, they often struggle with scalability, memory constraints, and computational inefficiency, particularly in handling high-resolution medical images. To overcome scalability and efficiency issues, we propose a novel deep learning approach, \textit{\textbf{PVTFormer}}, that is built upon a pretrained pyramid vision transformer (PVT v2) combined with advanced residual upsampling and decoder block. By integrating a refined feature channel approach with hierarchical decoding strategy, PVTFormer generates high quality segmentation masks by enhancing semantic features. Rigorous evaluation of the proposed method on Liver Tumor Segmentation Benchmark (LiTS) 2017 demonstrates that our proposed architecture not only achieves a high dice coefficient of 86.78\%, mIoU of 78.46\%, but also obtains a low HD of 3.50. The results underscore PVTFormer's efficacy in setting a new benchmark for state-of-the-art liver segmentation methods. The source code of the proposed PVTFormer is available at \url{https://github.com/DebeshJha/PVTFormer}.
FuseNet: Self-Supervised Dual-Path Network for Medical Image Segmentation
Nov 22, 2023Semantic segmentation, a crucial task in computer vision, often relies on labor-intensive and costly annotated datasets for training. In response to this challenge, we introduce FuseNet, a dual-stream framework for self-supervised semantic segmentation that eliminates the need for manual annotation. FuseNet leverages the shared semantic dependencies between the original and augmented images to create a clustering space, effectively assigning pixels to semantically related clusters, and ultimately generating the segmentation map. Additionally, FuseNet incorporates a cross-modal fusion technique that extends the principles of CLIP by replacing textual data with augmented images. This approach enables the model to learn complex visual representations, enhancing robustness against variations similar to CLIP's text invariance. To further improve edge alignment and spatial consistency between neighboring pixels, we introduce an edge refinement loss. This loss function considers edge information to enhance spatial coherence, facilitating the grouping of nearby pixels with similar visual features. Extensive experiments on skin lesion and lung segmentation datasets demonstrate the effectiveness of our method. \href{https://github.com/xmindflow/FuseNet}{Codebase.}
HCA-Net: Hierarchical Context Attention Network for Intervertebral Disc Semantic Labeling
Nov 21, 2023Accurate and automated segmentation of intervertebral discs (IVDs) in medical images is crucial for assessing spine-related disorders, such as osteoporosis, vertebral fractures, or IVD herniation. We present HCA-Net, a novel contextual attention network architecture for semantic labeling of IVDs, with a special focus on exploiting prior geometric information. Our approach excels at processing features across different scales and effectively consolidating them to capture the intricate spatial relationships within the spinal cord. To achieve this, HCA-Net models IVD labeling as a pose estimation problem, aiming to minimize the discrepancy between each predicted IVD location and its corresponding actual joint location. In addition, we introduce a skeletal loss term to reinforce the model's geometric dependence on the spine. This loss function is designed to constrain the model's predictions to a range that matches the general structure of the human vertebral skeleton. As a result, the network learns to reduce the occurrence of false predictions and adaptively improves the accuracy of IVD location estimation. Through extensive experimental evaluation on multi-center spine datasets, our approach consistently outperforms previous state-of-the-art methods on both MRI T1w and T2w modalities. The codebase is accessible to the public on \href{https://github.com/xmindflow/HCA-Net}{GitHub}.
Leveraging Unlabeled Data for 3D Medical Image Segmentation through Self-Supervised Contrastive Learning
Nov 21, 2023Current 3D semi-supervised segmentation methods face significant challenges such as limited consideration of contextual information and the inability to generate reliable pseudo-labels for effective unsupervised data use. To address these challenges, we introduce two distinct subnetworks designed to explore and exploit the discrepancies between them, ultimately correcting the erroneous prediction results. More specifically, we identify regions of inconsistent predictions and initiate a targeted verification training process. This procedure strategically fine-tunes and harmonizes the predictions of the subnetworks, leading to enhanced utilization of contextual information. Furthermore, to adaptively fine-tune the network's representational capacity and reduce prediction uncertainty, we employ a self-supervised contrastive learning paradigm. For this, we use the network's confidence to distinguish between reliable and unreliable predictions. The model is then trained to effectively minimize unreliable predictions. Our experimental results for organ segmentation, obtained from clinical MRI and CT scans, demonstrate the effectiveness of our approach when compared to state-of-the-art methods. The codebase is accessible on \href{https://github.com/xmindflow/SSL-contrastive}{GitHub}.
A multi-institutional pediatric dataset of clinical radiology MRIs by the Children's Brain Tumor Network
Oct 02, 2023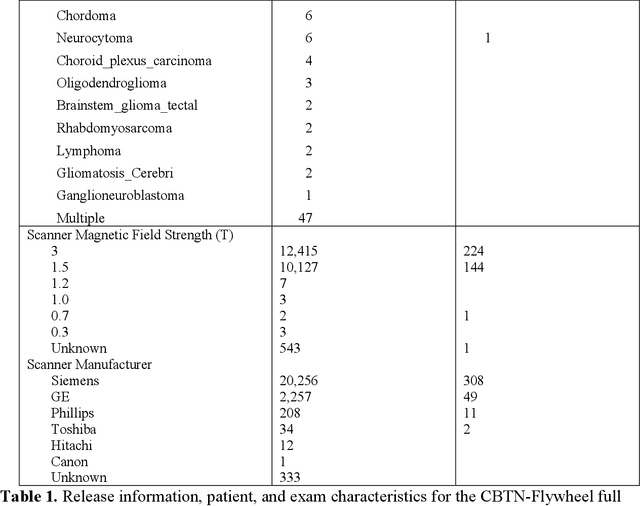
Pediatric brain and spinal cancers remain the leading cause of cancer-related death in children. Advancements in clinical decision-support in pediatric neuro-oncology utilizing the wealth of radiology imaging data collected through standard care, however, has significantly lagged other domains. Such data is ripe for use with predictive analytics such as artificial intelligence (AI) methods, which require large datasets. To address this unmet need, we provide a multi-institutional, large-scale pediatric dataset of 23,101 multi-parametric MRI exams acquired through routine care for 1,526 brain tumor patients, as part of the Children's Brain Tumor Network. This includes longitudinal MRIs across various cancer diagnoses, with associated patient-level clinical information, digital pathology slides, as well as tissue genotype and omics data. To facilitate downstream analysis, treatment-na\"ive images for 370 subjects were processed and released through the NCI Childhood Cancer Data Initiative via the Cancer Data Service. Through ongoing efforts to continuously build these imaging repositories, our aim is to accelerate discovery and translational AI models with real-world data, to ultimately empower precision medicine for children.